当我们想要访问DOM中的文本内容时,肯定会第一时间想到HTMLElement.innerText。事实上,JavaScript 提供了两个可用于「访问元素文本内容的」属性:Node.textContent和HTMLElement.innerText。在大多数情况下,这两者似乎可以互换。但我们在互换使用它们,往往会忽略两者之间存在重要区别。
相似之处
我认为在深入研究差异之前确定这两个属性的相似之处很有帮助。这也将阐明它们在大多数情况下的使用方式。
假设有一个 HTML 元素,其中包含一些文本:
这两个属性都将返回元素的文本内容,包括任何子「元素」的文本内容。它们还将忽略元素内容中可能出现的「任何 HTML 标记。」而且,它们也可用于「设置元素的文本内容」。
差异
到目前为止,这两个属性似乎在做完全相同的事情。事实上,它们都提供了一些非常有用的便利功能。然而,当元素的内容稍微复杂一点时,它们开始表现出一些差异。
以下面的 HTML 元素为例:
让我们看一下这两个属性各自的输出,看看它们有何不同。
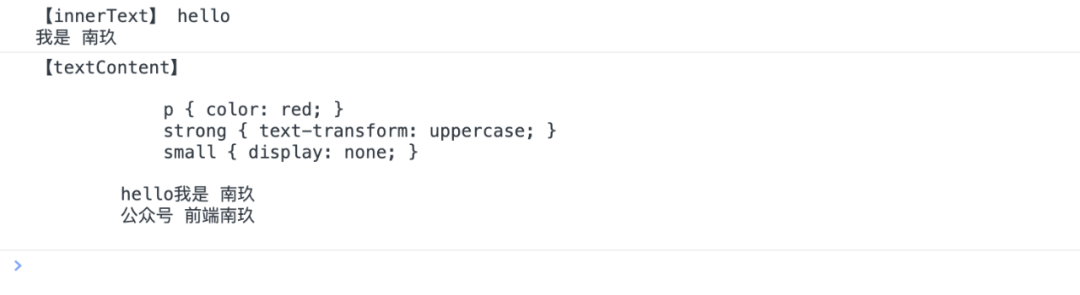
在这种情况下是完全不同的,对吧?HTMLElement.innerText应该大致「匹配用户」在浏览器中看到的内容。另一种思考方式是它的输出应该与用户选择元素的内容并将其复制到剪贴板时得到的结果非常相似。
根据这个定义,首先要注意的是「隐藏的元素被忽略了」。这适用于不呈现的元素,例如<style>和<script>,也适用于使用 CSS 隐藏的元素。在此示例中,该<small>元素是隐藏的,因此它不包含在 的输出中HTMLElement.innerText。
其次, 的输出HTMLElement.innerText被「归一化」。这意味着所有空格都折叠成一个空格,并且所有换行符都替换为单个换行符。如果存在,<br>标签也会受到尊重,因此它们会被换行符替换。
我想说的最后一点是将「文本转换」HTMLElement.innerText应用于元素的内容。在本例中,元素被转换为大写,因此 的输出反映了这一点。<strong> HTMLElement.innerText
另一方面,Node.textContent返回元素的「确切文本内容,包括任何空格和换行符。」然而,<br>标签在没有任何替代品的情况下被剥离。它还包括任何隐藏元素的文本内容,例如<style>和<script>并且没有应用任何文本转换。
表现
可是等等!还有更多!虽然HTMLElement.innerText看起来是明智的选择,但它带有性能问题。为了弄清楚浏览器呈现的内容,必须考虑 CSS,触发重排。这在计算上可能「很昂贵」,并且可能会造成无意的性能瓶颈。
在我看来,一个好的经验法则是Node.textContent尽可能使用纯文本元素。对于更复杂的元素,请尝试确定它们如何受布局和用户交互的影响。例如,只呈现一次且永远不会改变的复杂元素将是 的用例HTMLElement.innerText,但您可以将输出存储在变量中并重新使用它。
结论
HTMLElement.innerText并且Node.textContent是两个非常相似的属性,可用于访问和操作元素的文本内容。但是,它们在一些重要方面有所不同,你应该了解这些差异以选择最适合您需求的一种。始终检查你的用例并考虑你的选择对性能的影响。
- textContent会获取所有元素的content,包括<script>和<style>元素或者可以说innerText的值依赖于浏览器的显示,textContent依赖于代码的显示
- innerText返回值会被格式化,而textContent不会。textContent会把空标签解析成换行(几个空标签就是几行),innerText只会把block元素类型的空标签解析换行,并且如果是多个的话仍看成是一个,而inline类型的原素则解析成空格
- innerText 会带来性能影响(innerText会触发reflow,而textContent不会)