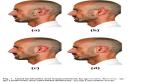
4 月 10 日消息,美国康奈尔大学的研究人员开发了一种新技术,可以通过声纳眼镜进行无声沟通。这种眼镜利用微型扬声器和麦克风来读取佩戴者默念的单词,从而可以在不需要物理输入的情况下执行各种任务。
 could be utilized to control devices, or even to help the voiceless communicate")
这项技术由康奈尔大学的博士生张瑞东(音译)领导开发,是在一个类似的项目的基础上进行的改进,该项目使用了一个无线耳机,而之前的模型则依赖于摄像头。
据IT之家了解,该声纳眼镜使用一种名为 EchoSpeech 的无声语音识别接口,利用声纳来感知嘴部运动,同时使用一个深度学习算法实时分析回波特征。这使得系统能够以约 95% 的准确率识别佩戴者默念的单词。
这项技术最令人兴奋的前景之一是,对于有语言障碍的人来说,可以使用它来无声地将对话输入到语音合成器中,然后将单词大声说出来。眼镜也可以用来在安静的图书馆中控制音乐播放,或者在嘈杂的音乐会上口述信息。
该技术既小巧又低功耗,也不会侵犯隐私,因为没有数据离开用户的手机。这样,就不会有隐私方面的担忧。眼镜佩戴非常方便,比其他可用的无声语音识别技术更实用、更可行。
研究人员表示,该系统只需要几分钟的训练数据来学习用户的语音模式,学习完成后,就可以朝用户的脸上发送和接收声波,感知嘴部运动,同时使用深度学习算法分析回波特征。该系统目前能够识别 31 个孤立的命令和一串连续的数字,并且错误率低于 10%。
该系统目前的版本提供了大约 10 小时的电池续航,并且可以通过蓝牙无线地与用户的智能手机通信。智能手机负责处理和预测所有数据,并将结果传输到一些“动作键”,让它可以播放音乐、与智能设备交互或激活语音助手。
康奈尔大学智能计算机接口未来交互(SciFi)实验室正在利用康奈尔大学的一个资助计划来探索将这项技术商业化的可能性。