1、背景
货品活动运营在圈选所需货品清单时,需要操作自助取数、智能运营系统、数据报表等多个系统工具才能完成。需要一个以供给侧盘货为核心需求的盘货工具,实现运营各场景盘货及货品分析诉求,提升运营效率。但是实现起来由以下几个难点。
- 指标复杂。除了常用的聚合函数SUM,MIN,MAX等,还有各种占比、期末 、水平等。
- 查询条件灵活。几乎每一列数据都可以作为查询条件进行筛选。常规的数据库无法承担此类查询。
- 数据量大。总计几十亿的数据量。

业内比较流行的OLAP数据库主要有ClickHouse和StarRocks。ClickHouse使用成本较高,非标准SQL协议,对JOIN支持不好,对灵活的业务开发并不友好。StarRocks支持标准的SQL协议,且对JOIN支持较好,MPP+向量化的查询引擎,性能也得到保障。并且在与其他数据库的性能测试对比中,StarRocks表现也十分亮眼。

上图测试对比结果来自于:https://benchmark.clickhouse.com/
2、模型选择
StarRocks 支持四种数据模型,分别是明细模型、聚合模型、更新模型和主键模型 。这四种数据模型能够支持多种数据分析场景,例如日志分析、数据汇总分析、实时分析等。
特点 | 适用场景 | |
明细模型 | 用于保存和分析原始明细数据,以追加写为主要写入方式,数据写入后几乎无更新 | 日志、操作记录、设备状态采样、时序类数据等 |
聚合模型 | 用于保存和分析汇总(max/min/sum)数据,不需要查询明细数据。数据导入后实时完成聚合,数据写入后几乎无更新 | 按时间、条件等汇总数据 |
主键模型 | 支持基于主键的更新,Delete and insert,大批量导入时保证高性能查询,用于保存和分析需要更新的数据 | 状态会发生变动的数据,例如订单、设备状态等 |
更新模型 | 支持基于主键的更新,Merge On Read,更新频率比主键模型更高,用于保存和分析需要更新的数据 | 状态会发生变动的数据,例如订单、设备状态等 |
盘货底层的数据按照多维度存储,多个维度之间可以通过join来互相关联,并且最终聚合计算结果会按照spu的维度在前台展示。因为数据需要保存明细,以满足丰富多变的查询条件组合,所以首先排除了聚合模型。而在实时和频繁更新的场景下,主键模型相较于更新模型能够带来更加高效的查询体验。所以在数据模型选择上,对于数据量较大的T+1维度表我们选择了明细模型+物化视图的方式(因为2.5版本前的主键模型不支持物化视图的自动查询改写,需要在SQL中指定异步物化视图的名称来查询),对而于数据量较小的基础数据、可更新的(spu信息)场景我们选择了主键模型。

3、数据写入
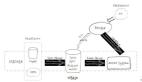
设计完表结构后,我们考虑如何进行数据的导入。StarRocks支持多种数据源的导入,下图展示了在各种数据源场景下,应该选择哪一种导入方式。

!盘货的指标数据我们选择通过DataWorks(DataX)方式进行导入。而在导入的过程中经常会碰到以下两个问题。
3.1 列数量不匹配
默认设置下,数据会被转化为字符串,以 CSV 格式通过 Stream Load 导入至 StarRocks。字符串以 \t 作为列分隔符,\n 作为行分隔符。
实际场景,我们的数据可能正好包含了\t 和 \n,再按照默认的规则进行分割,会导致列的数量不匹配或者数据错误。这个时候可以通过在参数 SteamLoad 请求参数中添加以下配置,以更改分隔符,StarRocks 支持设置长度最大不超过 50 个字节的 UTF-8 编码字符串作为列分隔符。尽可能缩短分隔符的长度,如果分割符太长,会变相的导致CSV数据包变大,从而导致导入速度变慢。
另外,倘若在以CSV的格式导入时难以确定合适的分隔符的话,可以考虑使用json格式进行数据的导入,能够很好地避免分隔符问题带来的烦扰。但是json格式相比CSV格式,数据集中多出很多譬如“{}"、列名称等的字符,会导致导入数据量不变的情况下,导入数据的行数变少,从而使得导入的速度变慢。
- 错误现象

- 解决示例
3.2 版本号超出限制
单表在导入千万级别的数据后,经常会报“Too many version”,导致同步任务失败,原因是导入频率太快,数据没能及时合并,从而导致版本数超过参数限制的tablet最大版本数。默认支持的最大未合并版本数为 1000。此时有两种方式解决:一是数据库服务端调高BE的合并参数,加快数据的合并,但注意此时会增加数据库CPU、内存等资源的消耗;二是数据导入端可以通过增大单次导入数据量,减少导入的频率来解决,StarRocks的通过以下3个参数来控制导入,但需要将同步任务转换为代码模式,并在Writer节点的parameter参数中进行添加。
- 错误现象

- 解决示例

属性名称 | 说明 | 默认值 |
maxBatchRows | 单次 Stream Load 导入的最大行数。导入大量数据时,StarRocks Writer 将根据 maxBatchRows 或 maxBatchSize 将数据分为多个 Stream Load 作业分批导入 | 500000 |
maxBatchSize | 单次 Stream Load 导入的最大字节数,单位为 Byte。导入大量数据时,StarRocks Writer 将根据 maxBatchRows 或 maxBatchSize 将数据分为多个 Stream Load 作业分批导入 | 104857600 |
flushInterval | 上一次 Stream Load 结束至下一次开始的时间间隔,单位为 ms | 300000 |
4、性能优化
4.1 执行计划
- Query Plan
通过以下命令查看 Query Plan。
我们以如下SQL举例子:
执行explain后展示如下:
核心指标主要有以下几个:
名称 | 说明 |
avgRowSize | 扫描数据行的平均大小 |
cardinality | 扫描表的数据总行数 |
colocate | 是否采用了 Colocate Join |
numNodes | 扫描涉及的节点数 |
rollup | 物化视图,如果没有则与表名一致 |
preaggregation | 预聚合 |
predicates | 谓词,也就是查询过滤条件 |
partitions | 分区名 |
table | 表名 |
- Query Profile
如果想看更为详细的执行计划,需要通过profile的方式获取。2.5之前的版本需要指定以下参数(session级别),然后可以在starrocks的控制台上查看到执行计划。

4.2 索引
- 前缀索引
在建表时,可以指定一个或多个列作为排序键 。表中的行会根据排序键进行排序后再落盘。查询数据时可以按照二分的方式进行扫描,避免了全表扫描。同时为减少内存开销,StarRocks 在排序键的基础上又引入了前缀索引。前缀索引是一种稀疏索引。表中每 1024 行数据构成一个逻辑数据块 (Data Block)。每个逻辑数据块在前缀索引表中存储一个索引项,索引项的长度不超过 36 字节,其内容为数据块中第一行数据的排序列组成的前缀,在查找前缀索引表时可以帮助确定该行数据所在逻辑数据块的起始行号。前缀索引的大小会比数据量少 1024 倍,因此会全量缓存在内存中,在实际查找的过程中可以有效加速查询。

比如主键模型的建表语句,指定了PRIMARY KEY为spu_id,seller_id,date,当查询条件包含了spu_id、seller_id时能快速的定位到数据,但如果单独按照seller_id来查询,则无法利用到前缀索引(最左匹配原则)。所以在设计表结构时将经常作为查询条件的列,选为排序列。当排序键涉及多个列的时候,建议把区分度高、且经常查询的列放在前面。
- bitmap索引
如果想要提高一个非前缀索引列的查询效率,可以为这一列创建 Bitmap 索引。比如列基数较低,值大量重复,例如 ENUM 类型的列,使用 Bitmap 索引能够减少查询的响应时间。
举个🌰,现在对商品信息的商品状态和商品类型创建bitmap索引:
- 构建字典:StarRocks 根据 商品状态 列的取值构建一个字典,将 普通商品 和 定制服务 分别映射为 INT 类型的编码值:0 和 1。
- 生成 bitmap:StarRocks 根据字典的编码值生成 bitmap。因为 普通商品 出现在了1,2,3,4,5行,所以 普通商品 的 bitmap 是 111110000;定制服务 出现在第 6,7,8,9行,所以 定制服务 的 bitmap 是 000001111。
- 查询 定制服务 的商品:先查询字典映射,得到字典值1,再去查询字典值1的bitmap,得出定制服务在6,7,8,9行。
- 查询 定制服务 且 上架 的商品:类似的道理,会将两段bitmap值进行位运算,000001111 & 100100100 得出 000000100,也就是只有第7行满足条件。

4.3 Colocate Join
!Colocation Join 功能,是将一组拥有相同 Colocation Group Schema(CGS)的 Table 组成一个 Colocation Group(CG)。并保证这些 Table 对应的数据分片会落在同一个 BE 节点上。使得当 Colocation Group 内的表进行分桶列上的 Join 操作时,可以通过直接进行本地数据 Join,减少数据在节点间的传输耗时。
同一 CG 内的 Table 必须保证以下属性相同:
- 分桶列和分桶数相同,DISTRIBUTED BY HASH(k1) BUCKETS 8相同
- 副本数相同,replication_num相同
建表时,可以在 PROPERTIES 中指定属性 "colocate_with" = "group_name",表示这个表是一个 Colocation Join 表,并且归属于一个指定的 Colocation Group。
使用完Colocation Join 的执行计划,join op后会标注走的COLOCATE

4.4 物化视图
!物化视图是将预先计算好(根据定义好的 SELECT 语句)的数据集,存储在 StarRocks 中的一个特殊的表,本质上是张聚合模型的表。
2.5版本下物化视图还不支持查询改写,由于物化视图是预先定义聚合的数据,因此当要查询的数据列超过物化视图所定义列的范围的话,会导致物化视图失效。
创建语句如下:
当创建完物化视图后,可以明显的发现耗时变低了,再次查询执行计划,rollup已经变成了物化视图的表名:

对近200个字段分别做聚合操作后再分页,SQL如下:
从查询耗时上来看,物化视图能极大的提高查询效率,在大量数据下也比较平稳。

4.5 星型模型
StarRocks 支持选择更灵活的星型模型来替代传统建模方式的大宽表。用一个视图来取代宽表,直接使用多表关联来查询。在 SSB 的标准测试集的对比中,StarRocks 的多表关联性能相较于单表查询并无明显下降。
相比星型模型,宽表的缺点包括:
- 维度更新成本更高。宽表中,维度信息更新会反应到整张表中,其更新的频率直接影响查询的效率。
- 维护成本更高。宽表的建设需要额外的开发工作、存储空间。
- 导入成本更高。宽表的 Schema 字段数较多,导入过程中需要排序的列会增加,进而导致导入时间变长。

5、问题与规划
我们在上线后的使用过程中也发现了一些瓶颈点,比如高计算量 + 大数据量的查询时间会略久(数亿行数据的count(distinct case when),sum(case when)等)、主键模型下的某宽表数据空洞 + 列数越来越多导致查询及导入性能受影响,基于这些瓶颈我们未来有如下规划:
- 优化表结构设计
主键模型的某宽表的表结构及示例数据如下,由于不同指标(A、B、C、...、Y)的可能情况较多(1、2、3、...、20),就导致组合之下存在25 * 20=500列,且对于某一行数据的比如A指标,可能仅有A_1、A_2列是有具体值的,而对于A_3 ~ A_20其实都是默认值或者空值;而B指标,却可能是B_3和B_6列是有值的,其他列是默认值,这便造成了表中数据的空洞化;另一方面,假如需要新增指标的话,比如新增Z指标,大宽表在原有基础上又要新增20列(Z_1 ~ Z_20),这对于表的维护以及查询导入都会带来压力。
为此后续我们考虑两种思路进行表结构的优化,一是使用非结构化的数据类型比如json格式来存储相关数据,但会导致相关列的筛选性能下降;二是对宽表进行拆分,但会造成行数据量的暴涨。所以这块还是需要花费心思设计下的,也欢迎大家有好的想法与我们交流。
- 多表异步物化视图
对于多表关联的场景,我们希望后续能够使用多表物化视图的形式对数据进行预聚合,从而在查询时提高查询响应的速度,尤其是大数据量的查询场景下;同时由于我们数据是每天固定时间批量导入,完全可以接受在数据导入后异步刷新物化视图。但目前2.4版本的多表异步物化视图尚不支持查询改写,2.5支持SPJG类型查询的自动命中物化视图查询改写,3.0支持大多数查询场景的查询改写。
- Query Cache
Query Cache 可以保存查询的中间计算结果。后续发起的语义等价的查询,能够复用先前缓存的结果,加速计算,从而提升高并发场景下简单聚合查询的 QPS 并降低平均时延。该特性自2.5版本开始支持,且初期支持有限,比如2.5版本仅支持宽表模型下的单表聚合查询,而3.0会支持更多使用场景,包括各种 Broadcast Join、Bucket Shuffle Join 等 Join 场景。所以后续比较期待使用该特性扩展我们查询的QPS,提高查询体验。
6、写在最后
虽然整个过程遇到了很多问题也踩了不少的坑,但上线后查询响应时间以及整体运行的稳定性还是比较满意的,因此后续我们也考虑接入更多的数据以及场景到starrocks中,也特别感谢DBA 团队和 Starrocks 官方的支持。