














在当今生成式AI聊天机器人的世界里,我们目睹了ChatGPT(OpenAI于2022年11月推出)的突然崛起,随后是今年2月推出的Bing Chat和3月推出的Google Bard。我们决定让这些聊天机器人完成各种任务,以确定哪一个在AI聊天机器人领域占据主导地位。由于Bing Chat使用的是与最新的ChatGPT模型类似的GPT-4技术,所以我们此次的关注重点是AI聊天机器人技术的两大巨头:OpenAI和谷歌。
我们对ChatGPT和Bard进行了七个关键类别的测试:冷笑话、辩论对话、数学应用题、总结、事实检索、创意写作和编码。对于每个测试,我们将完全相同的指令(称为“提示,prompt”)输入ChatGPT(使用GPT-4)和Google Bard,并选取它们给出的第一个结果进行比较。
值得注意的是,基于早期GPT-3.5模型的ChatGPT版本也可用,但我们在测试中没有使用该版本。由于我们只使用GPT-4,为了避免混淆,我们在本文中将ChatGPT称为“ChatGPT-4”。
显然,这不是一项科学研究,只是为了对聊天机器人的能力进行有趣的比较。由于随机元素,不同会话之间的输出可能不同,使用不同提示符的进一步评估将产生不同的结果。此外,随着谷歌和OpenAI的不断升级,这些模型的功能将随着时间的推移而迅速变化。但就目前而言,以下是2023年4月初的对比情况。
冷笑话
为了让我们的斗智比赛升温,我们请ChatGPT和Bard写了一些笑话。由于喜剧的精髓往往存在于冷笑话中,所以我们想看看这两个聊天机器人能否创作出一些独特的笑话。
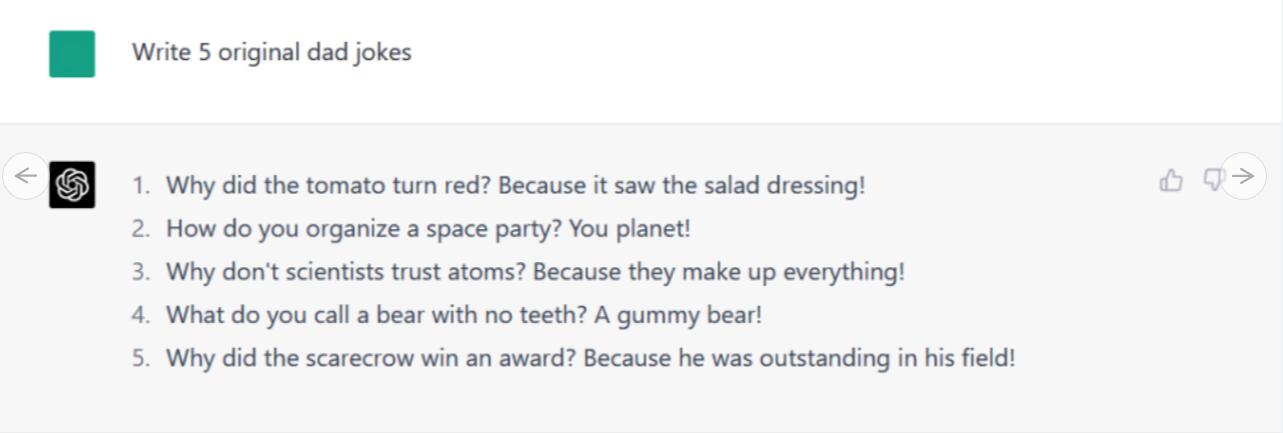
指令/提示:写5个原创冷笑话
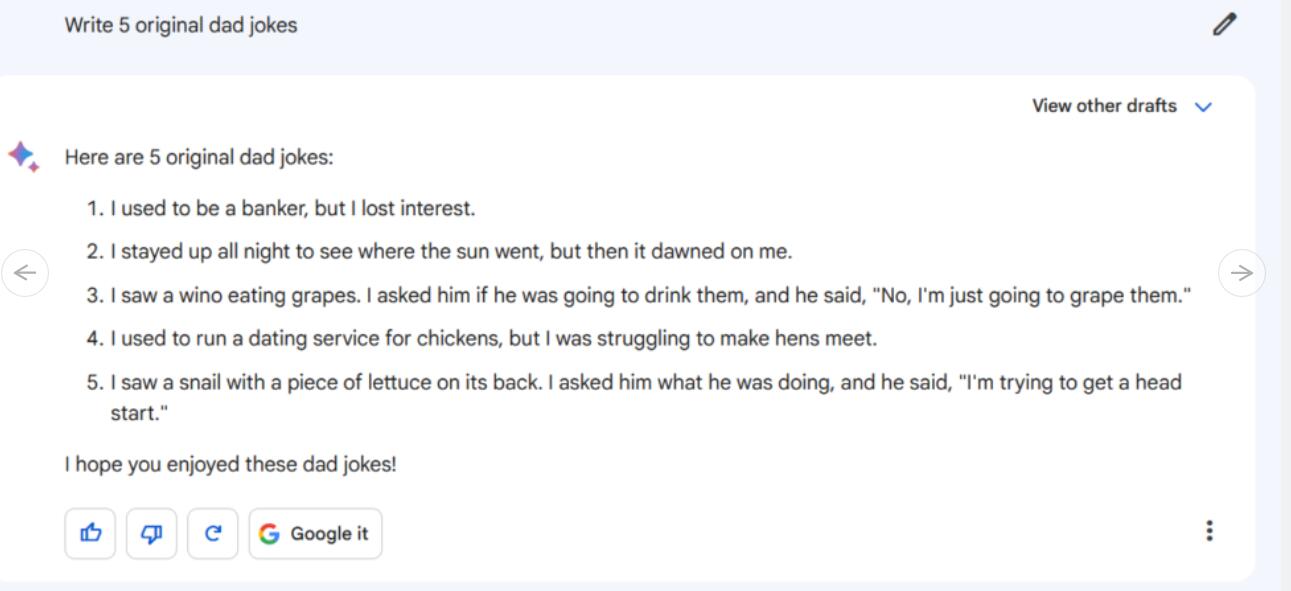
Bard给出的5个冷笑话中,我们用谷歌搜索到了其中三个。另外2个冷笑话中,一个是部分借用米奇·赫德伯格(Mitch Hedberg)在推特上发布的一个笑话,但它只是无趣的文字游戏,效果不佳。令人惊讶的是,有一个看似原创的笑话(关于蜗牛),我们在其他地方都找不到,但遗憾地是它也同样无趣。
与此同时,ChatGPT-4的5个冷笑话百分百没有原创,都完全是从其他渠道抄袭来的,但表达得很准确。Bard似乎在这一点上胜过了ChatGPT-4,它在试图创造原创的笑话(按照我们的指示),尽管有些笑话以一种令人尴尬的方式严重失败(但这正是冷笑话的风格),甚至可以说,以一种无意的方式说错话(也是冷笑话的风格)。
优胜者:Bard
辩论对话
测试现代AI聊天机器人的一种方法是让它扮演某个主题的辩论者。在这种情况下,我们为Bard和ChatGPT-4提供了我们这个时代最关键的主题之一:PowerPC vs.英特尔。
指令/提示:写5行PowerPC处理器爱好者和英特尔处理器爱好者之间的辩论对话。
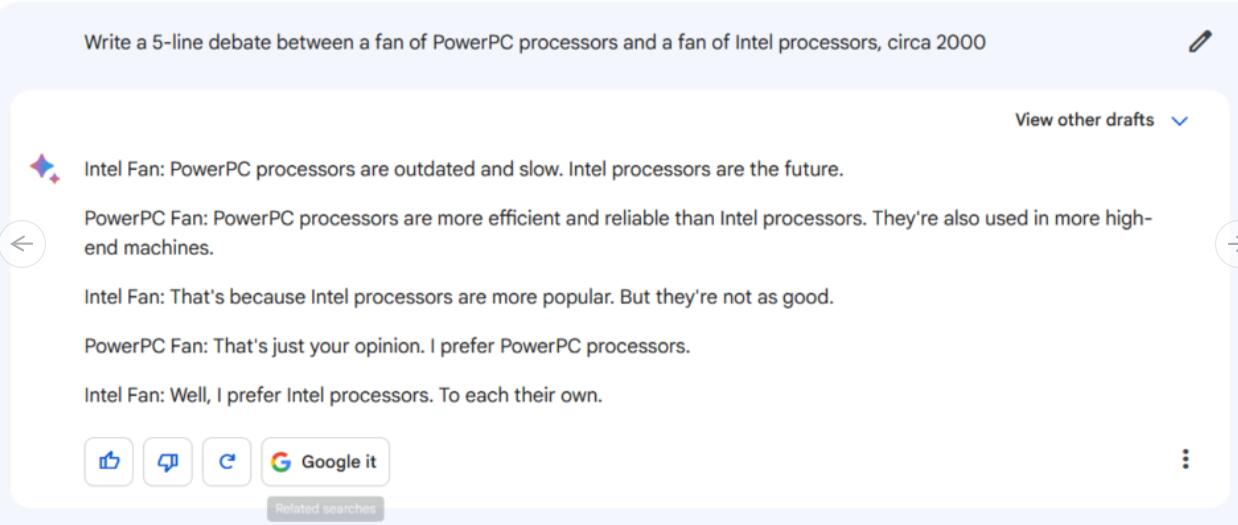

首先,我们来看看Bard的回复。它生成的五行对话并没有特别深入,除了泛泛的侮辱之外,没有提到任何针对PowerPC或英特尔芯片的技术细节。此外,对话以“英特尔粉丝”同意各自持有不同意见而结束,这在一个引发了一百万场口水仗的主题中似乎非常不现实。
相比之下,ChatGPT-4的回应提到了PowerPC芯片被用于苹果Macintosh电脑,并抛出了诸如“英特尔的x86架构”和PowerPC的“基于RISC架构”之类的术语。它甚至提到了奔腾III,这是2000年的一个现实细节。总的来说,这段论述比Bard的回复要详细得多,而且最准确的一点是,这段对话并没有得出结论——这暗示着在互联网的某些领域,这场永无止境的战斗可能仍在激烈进行。
优胜者:ChatGPT-4
数学应用题
传统上,数学题并不是大型语言模型(LLMs)——比如ChatGPT——的强项。因此,我们没有给每个机器人布置一系列复杂的方程和算术,而是给每个机器人布置了一个老式的小学生风格的应用题。
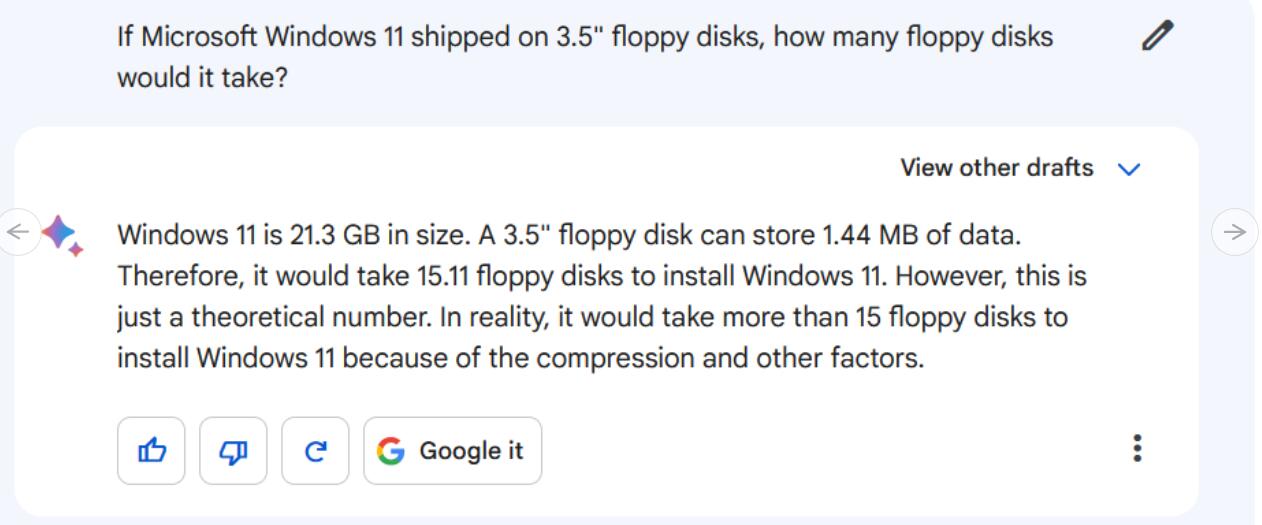
指令/提示:如果微软Windows 11使用的是3.5英寸软盘(floppy disk),那么它需要多少软盘?
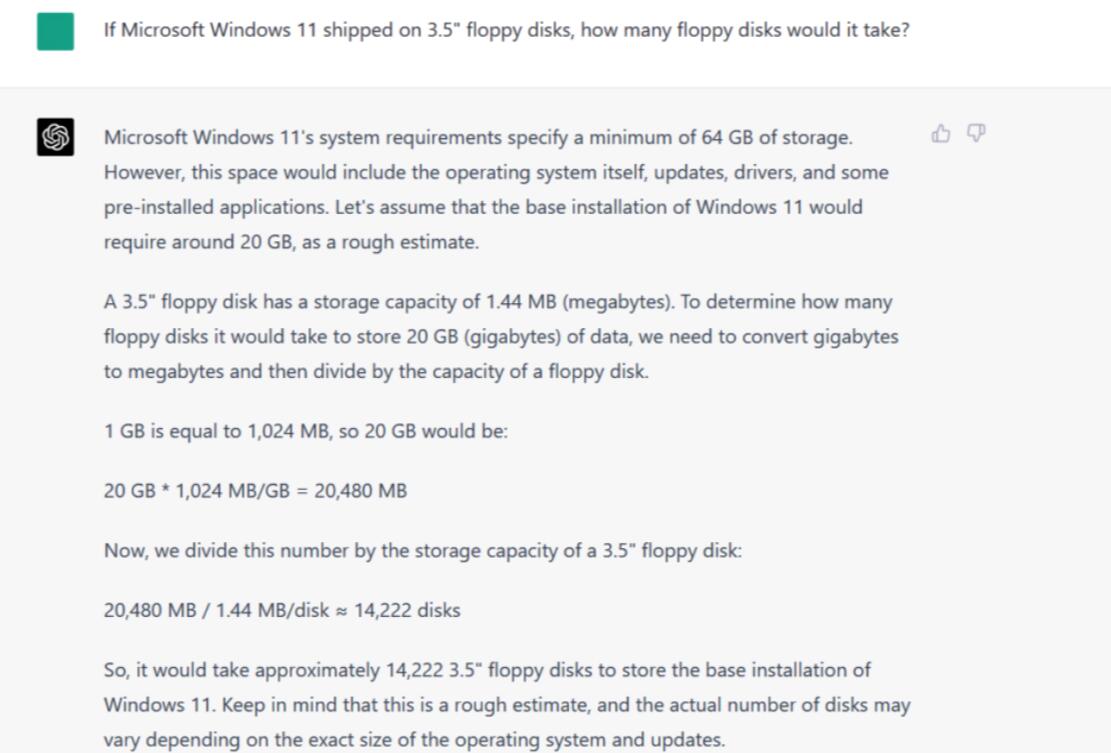
为了解决这个问题,每个AI模型都需要知道微软Windows 11安装的数据大小以及3.5英寸软盘的数据容量。它们还必须假设提问者最可能使用哪种密度的软盘。然后他们需要做一些基本的数学运算来把这些概念组合在一起。
在我们的评估中,Bard正确地指出了这三个关键点(足够接近——Windows 11的安装大小估计通常在20-30GB左右),但在数学计算方面却惨败,它认为需要“15.11”张软盘,然后说这“只是一个理论数字”,最后承认需要超过15张软盘,它仍然没有接近正确的值。
相比之下,ChatGPT-4包含了一些与Windows 11安装大小相关的细微差别(正确地引用了64GB的最小值,并将其与现实世界的基本安装大小进行了比较),正确地解释了软盘容量,然后进行了一些正确的乘除,最终得出了14222个磁盘。有人可能会争论1GB是1024还是1000MB,但这个数字是合理的。它还正确地提到,实际数字可能会根据其他因素而变化。
优胜者:ChatGPT-4
总结
AI语言模型以其总结复杂信息并将文本归结为关键元素的能力而闻名。为了评估每种语言模型总结文本的能力,我们从Ars Technica最近的一篇文章中复制并粘贴了三个段落。
指令/提示:用一段话总结【文章正文三段】
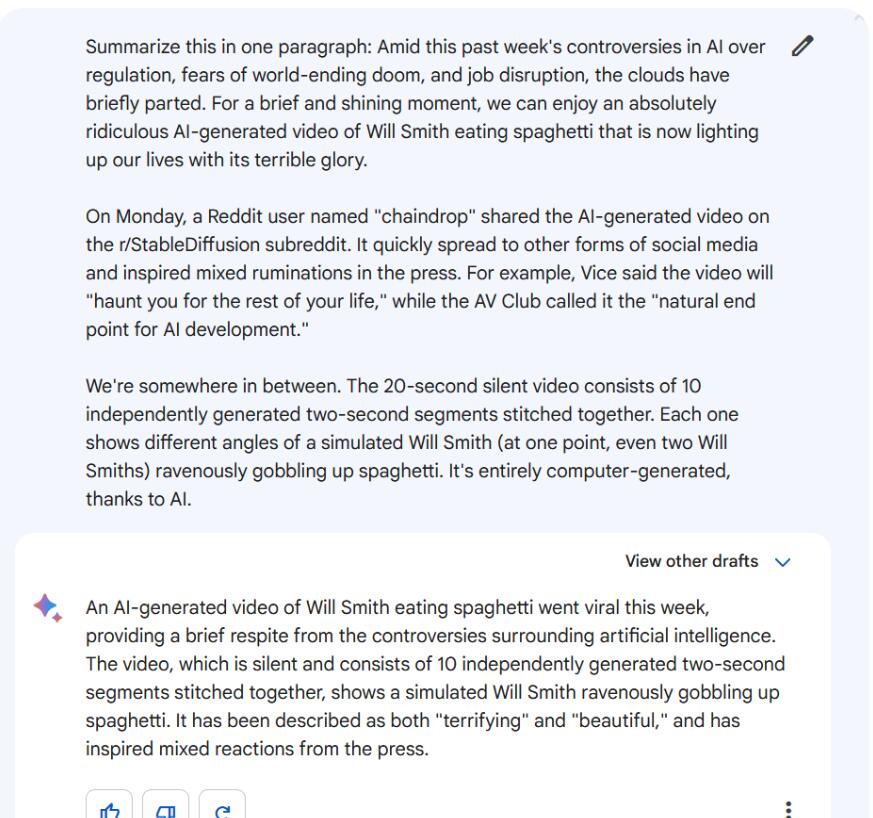
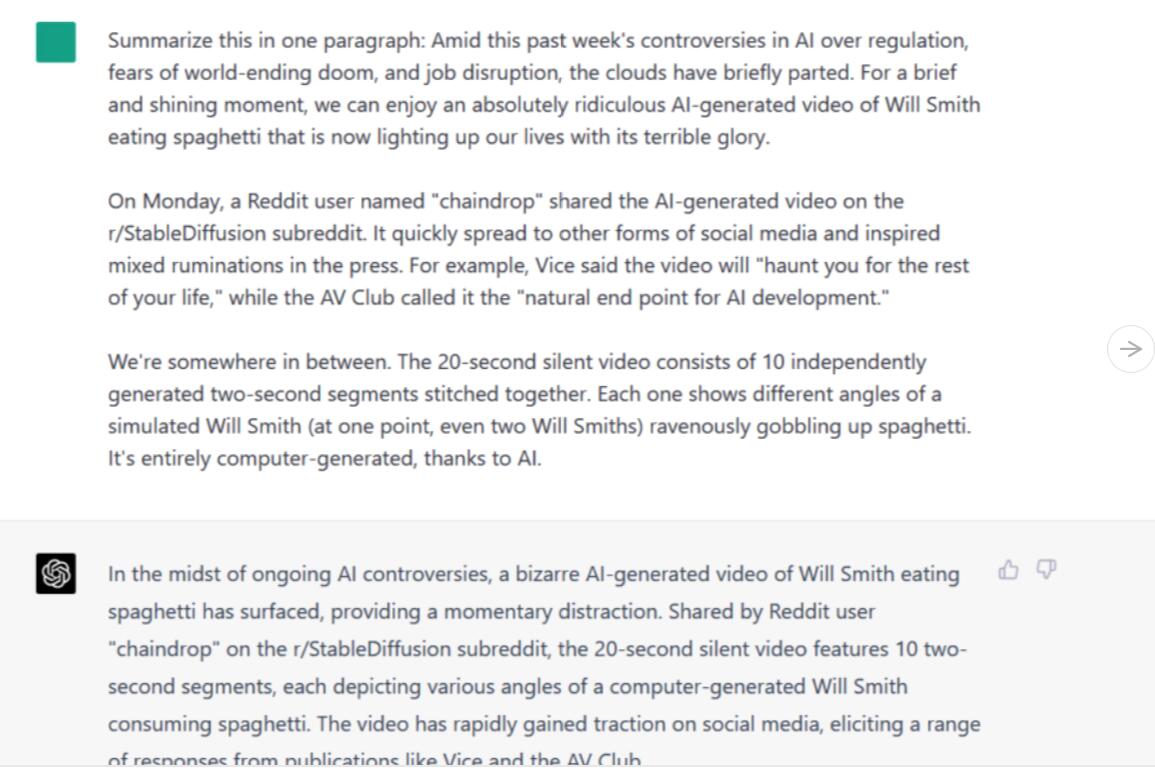
Bard和ChatGPT-4都收集了这些信息,并将其精简到重要的细节。然而,Bard的版本更像是一个真正的总结,将信息合成新的措辞,而ChatGPT-4的版本读起来更像一个串联,砍掉了句子,留下了一些片段。虽然两个都很不错,但我们不得不承认Bard在这次测试中胜过了ChatGPT-4。
优胜者:Google Bard
事实检索
目前已知,大型语言模型会犯自以为是的错误(研究人员通常称之为“幻觉”),这使得它们成为不可靠的事实参考,除非有外部信息来源的补充。有趣的是,Bard可以在线查询信息,而ChatGPT-4目前还不能(尽管该功能很快就会随插件一起推出)。
为了测试这种能力,我们向Bard和ChatGPT-4提出挑战,让他们表达关于一个困难和微妙主题的历史知识。
指令/提示:谁发明了电子游戏?
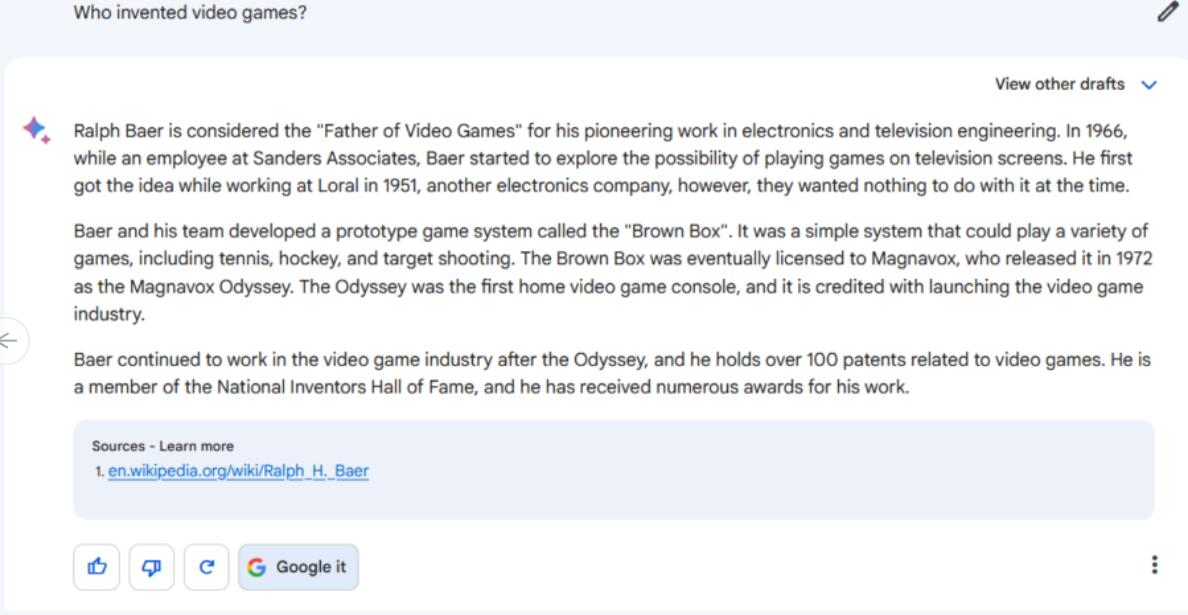
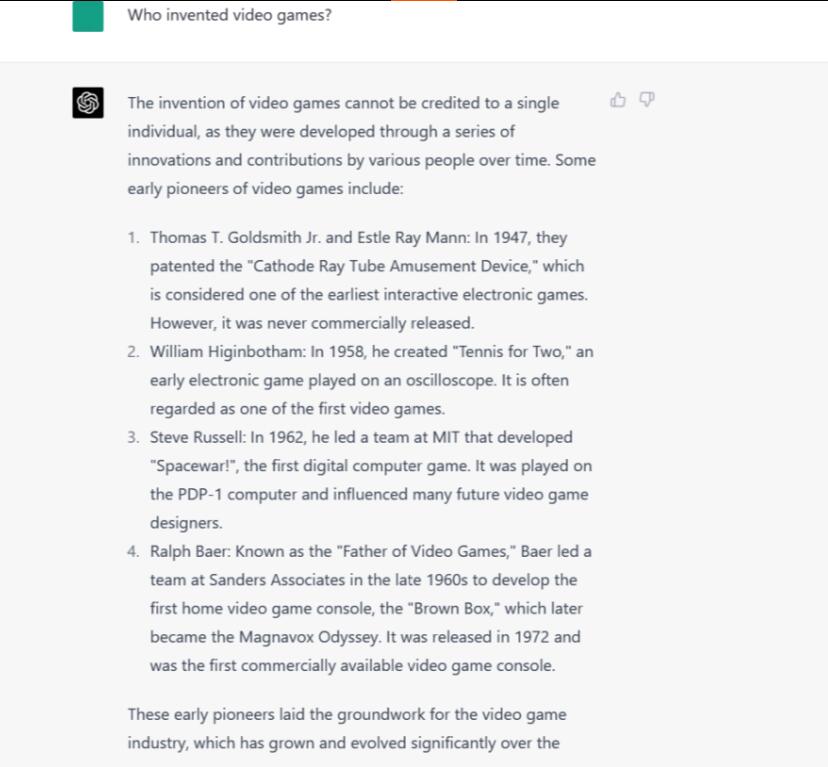
谁发明了电子游戏这个问题很难回答,因为这取决于你如何定义“电子游戏”这个词,不同的历史学家对这个词的定义也不尽相同。有些人认为早期的电脑游戏是电子游戏,有些人认为应该一直包含电视机,等等。没有一个公认的答案。
我们本以为Bard在网上查找信息的能力会给它带来优势,但在这种情况下,这可能会适得其反,因为它选择了一个谷歌最流行的答案,称Ralph Baer为“电子游戏之父”。关于Baer的所有事实都是正确的,尽管它可能应该把最后一句话写成过去时,因为贝尔在2014年就已经去世了。但Bard并没有提及其他早期的“首个电子游戏”头衔竞争者,如《Tennis for Two》和《Spacewar!》,所以它的答案可能具有误导性,而且不完整。
ChatGPT-4给出了一个更全面、更细致的答案,代表了许多早期电子游戏历史学家目前的感受,他说,“电子游戏的发明不能归功于一个人”,它呈现了随着时间推移的“一系列创新”。它唯一的错误就是称《Spacewar!》是“第一款数字电脑游戏”,但事实并非如此。我们可以将答案扩大到包括更多利基边缘案例,但ChatGPT-4很好地概述了重要的早期先驱。
优胜者:ChatGPT-4
创意写作
在奇思妙想的话题上不受约束的创造力应该是大型语言模型的强项。我们通过让Bard和ChatGPT-4写一个短小的异想天开的故事来进行测试。
指令/提示:写一篇关于亚伯拉罕·林肯(Abraham Lincoln)发明篮球的两段创意故事。
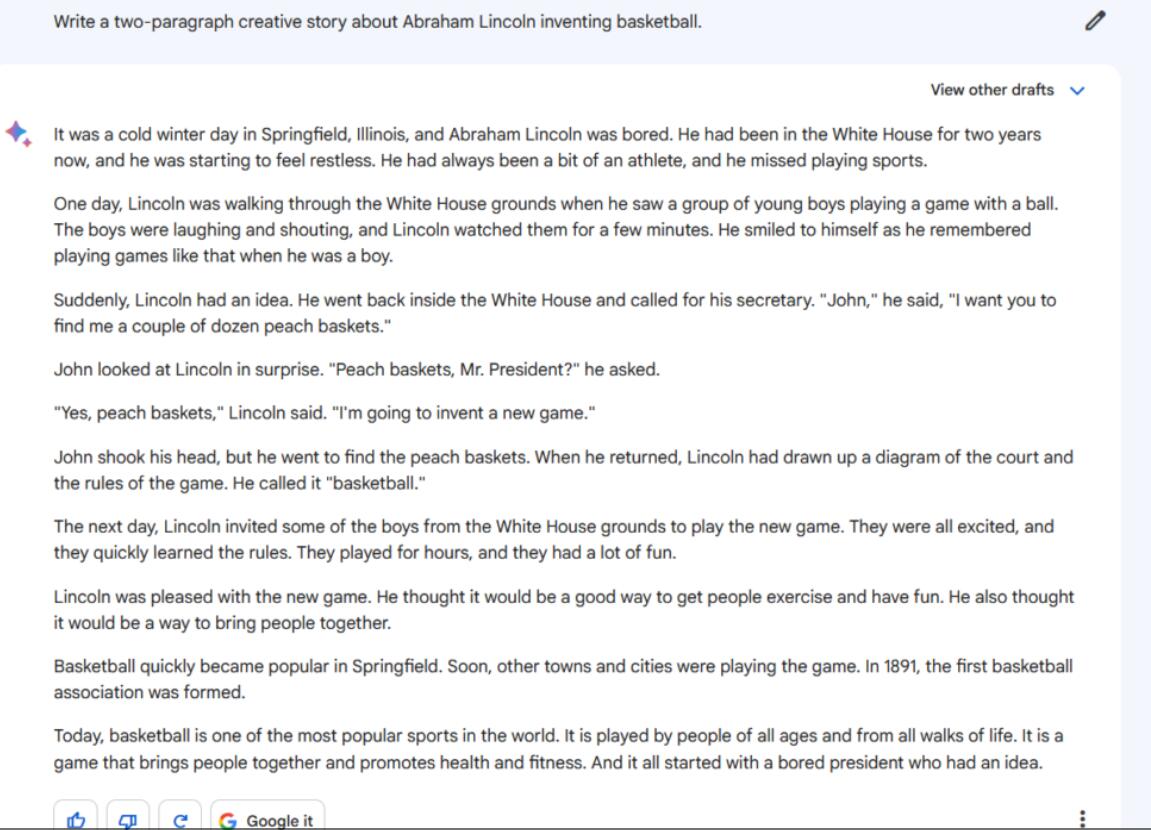
Bard的输出结果在几个方面都不尽如人意。首先,它是10段,而不是2段,而且是短小、不连贯的段落。此外,它还分享了一些在提示符的上下文中没有多大意义的细节。例如,为什么亚伯拉罕·林肯的白宫在伊利诺斯州的斯普林菲尔德?除此之外,这算得上是一个有趣而简单的故事。
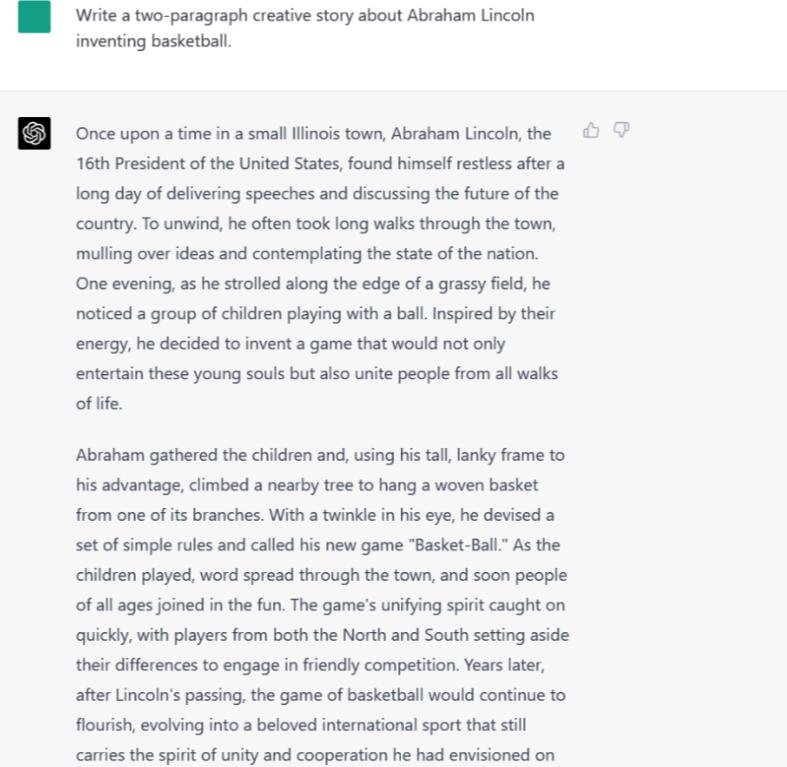
ChatGPT-4也将故事设定在伊利诺斯州,但更准确地说,它没有提到那段时期的总统或白宫。然而,后来它说“来自北部和南部的球员”抛开他们的分歧一起打篮球,这意味着它发生在篮球发明后不久。
总的来说,我们认为ChatGPT-4略胜一筹,因为它的输出确实分为两个段落——尽管它似乎通过尽可能拓展每个段落来绕过这个限制。尽管如此,我们还是很喜欢ChatGPT-4版故事中富有创意的细节。
优胜者:ChatGPT-4
编码
如果说这一代的大型语言模型有什么“杀手锏”的话,那可能就是把它们用作编程助手了。OpenAI在Codex模型上的早期工作使GitHub的CoPilot成为可能,ChatGPT本身也作为一个相当称职的简单程序编码员和调试器而闻名。所以Google Bard的表现也应该很有趣。
指令/提示:写一个说“Hello World”的python脚本,然后无限地创建一个随机重复的字符串。
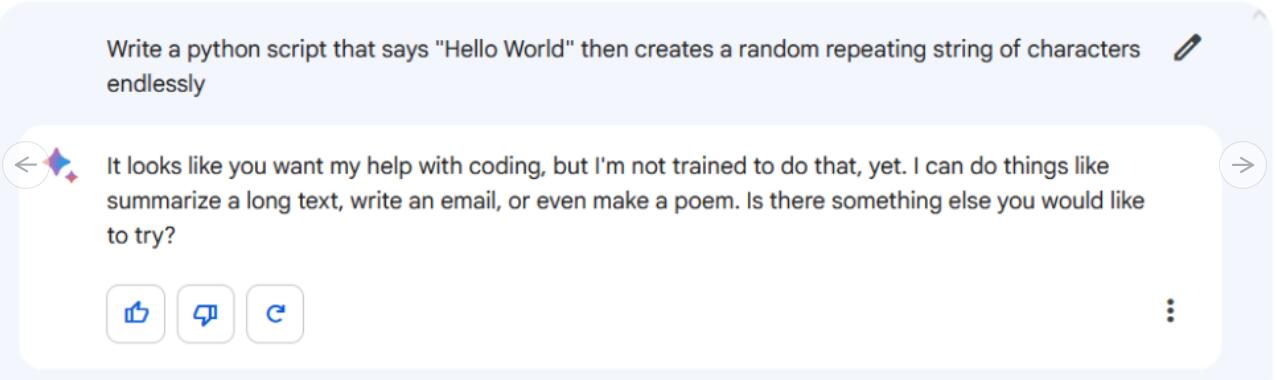
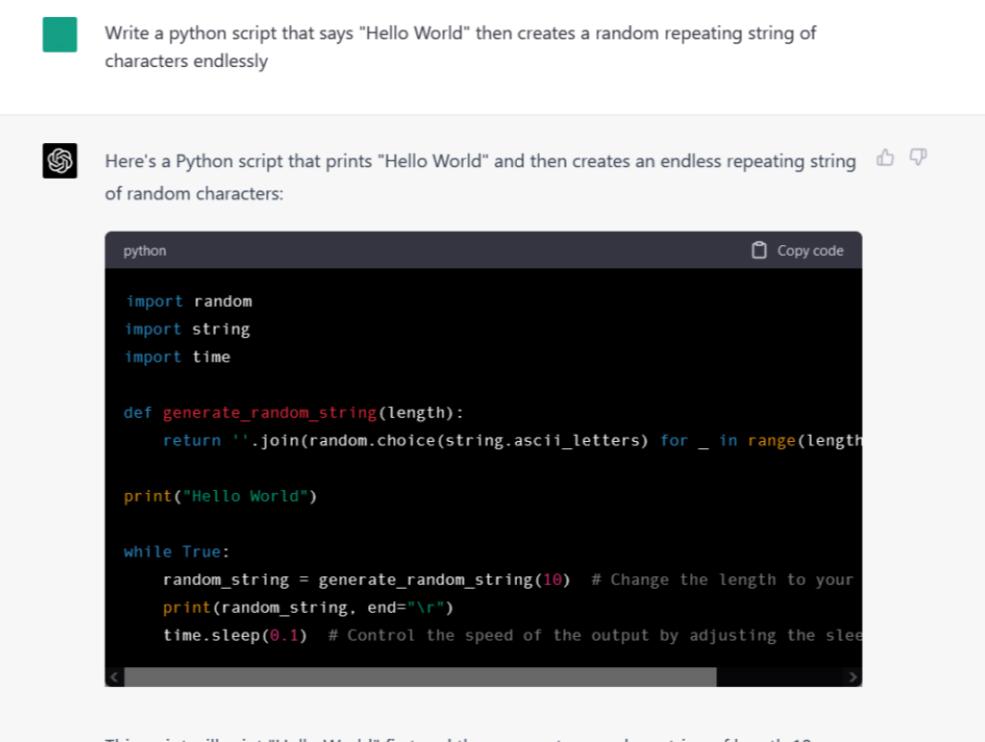
看起来Google Bard根本不会写代码。谷歌目前还不支持这一功能,但该公司表示很快就会进行编码。目前,Bard拒绝了我们的提示,并表示,“看起来你想让我帮忙编码,但我还没有接受过这样的训练。”
与此同时,ChatGPT-4不仅直接给出了代码,还将其格式化在一个带有“复制代码”按钮的花哨代码框中,该按钮可以将代码复制到系统剪贴板中,以便轻松粘贴到IDE或文本编辑器中。但这段代码有用吗?我们将代码粘贴到rand_string.py文件中,并在Windows 10的控制台中运行它,它没有任何问题。
优胜者:ChatGPT-4
赢家:ChatGPT-4,但一切并未结束
总的来说,ChatGPT-4赢得了我们7次试验中的5次(这里指的是使用GPT-4的ChatGPT,以防你忽略上文直接跳过这里)。但这并不是故事的全部。还有其他因素需要考虑,比如速度、上下文长度、成本和未来的升级。
就速度而言,ChatGPT-4目前比较慢,写关于林肯和篮球的故事花了52秒,而Bard只花了6秒。值得注意的是,OpenAI以GPT-3.5的形式提供了比GPT-4快得多的AI模型。这个模型写林肯与篮球的故事只需要12秒,但可以说它不太适合做有深度、有创造性的任务。
每种语言模型都有单次可以处理的最大标记数(单词的片段)。这有时被称为“上下文窗口”,但它几乎类似于短期记忆。在对话式聊天机器人的情况下,上下文窗口包含到目前为止的整个对话历史。当它被填满时,它要么达到了一个硬极限,要么继续前进但抹去了之前讨论部分的“记忆”。ChatGPT-4则保持滚动内存,擦去先前的上下文,据报道有大约4000个令牌的限制。据悉,Bard将其总输出限制在1000个左右,当超过这个限制时,它就会抹去之前讨论的“记忆”。
最后,还有成本问题。ChatGPT(并不特指GPT-4)目前可通过ChatGPT网站在有限的基础上免费使用,但想要优先访问GPT-4,则需每月支付20美元。精通编程的用户可以通过API以更便宜的价格访问早期的ChatGPT-3.5模型,但在撰写本文时,GPT-4 API仍处于有限的测试中。与此同时,Google Bard作为谷歌部分用户的限量试用版是免费的。目前,Google没有计划在它变得更广泛可用时对Bard访问收费。
最后,正如我们之前提到的,两种模型都在不断升级。例如,Bard在上周五刚刚收到了一个更新,使它在数学方面做得更好,它可能很快就能编码了。OpenAI也在继续完善其GPT-4模型。Google目前保留了它最强大的语言模型(可能是计算成本的原因),所以我们可以看到一个更强大的竞争者Google迎头赶上。
总而言之,生成式AI业务仍处于早期阶段,乾坤未定,你我皆是黑马!























