1 服务发现的意义
为高可用,生产环境中服务提供方都以集群对外提供服务,集群里这些IP随时可能变化,也需要用一本“通信录”及时获取对应服务节点,这获取过程即“服务发现”。
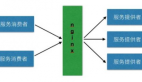
对服务调用方和服务提供方,其契约就是接口,相当于“通信录”中的姓名,服务节点就是提供该契约的一个具体实例。服务IP集合作为“通信录”中的地址,从而可通过接口获取服务IP的集合来完成服务的发现。即PRC框架的服务发现:

RPC服务发现原理图
1.1 服务注册
在服务提供方启动时,将对外暴露的接口注册到注册中心,注册中心将这个服务节点的IP和接口保存
1.2 服务订阅
在服务调用方启动时,去注册中心查找并订阅服务提供方的IP,然后缓存到本地,并用于后续的远程调用
2 为何不使用DNS?
服务发现的本质,就是完成接口跟服务提供者IP的映射。能否把服务提供者IP统一换成一个域名,利用DNS实现?
2.1 DNS流程

DNS查询流程
所有服务提供者节点都配置在同一域名下,调用方是可通过DNS拿到随机的一个服务提供者的IP,并建立长连接,但业界为何不用这方案?
异常考虑
- • 若该IP端口下线了,服务调用者能否及时摘除服务节点
- • 若在之前已上线一部分服务节点,突然对这服务扩容,新上线的服务节点能否及时接收到流量
都不能。因为为提升性能和减少DNS服务压力,DNS采取多级缓存,缓存时间较长,特别是JVM的默认缓存是永久有效,所以服务调用者不能及时感知到服务节点变化。
是否可加一个负载均衡设备?将域名绑定到这台负载均衡设备,通过DNS拿到负载均衡的IP。服务调用时,服务调用方就能直接跟VIP建立连接,然后由VIP机器完成TCP转发:

VIP方案
这是能解决DNS遇到的一些问题,但RPC里不是很合适:
- • 搭建负载均衡设备或TCP/IP四层代理,需额外成本
- • 请求流量都经过负载均衡设备,多经过一次网络传输,浪费性能
- • 负载均衡添加节点和摘除节点,一般要手动添加,当大批量扩容和下线时,会有大量人工操作和生效延迟
- • 服务治理时,需更灵活的负载均衡策略,目前负载均衡设备的算法不满足灵活需求
由此可见,DNS或者VIP方案虽然可以充当服务发现的角色,但在RPC场景里面直接用还是很难的。
3 基于zk的服务发现(CP)
服务发现的本质:完成接口跟服务提供者IP的映射。就是一种命名服务,还希望注册中心完成实时变更推送,zk、etcd都能实现。
搭建一个zk集群作为注册中心集群,服务注册时,只需服务节点向zk写入注册信息,利用zk的Watcher机制完成服务订阅与服务下发功能。
整体流程

基于ZooKeeper服务发现结构图
1. 服务平台管理端先在zk创建一个服务根路径,可根据接口名命名(如:/service/com.javaedge.xxService),在这路径再创建服务提供方目录与服务调用方目录(如:provider、consumer),分别存储服务提供方、服务调用方的节点信息
2. 当服务提供方发起注册时,会在服务提供方目录中创建一个临时节点,节点中存储该服务提供方的注册信息
3. 当服务调用方发起订阅时,则在服务调用方目录中创建一个临时节点,节点中存储该服务调用方的信息,同时服务调用方watch该服务的服务提供方目录(/service/com.demo.xxService/provider)中所有的服务节点数据。
4. 当服务提供方目录下有节点数据发生变更时,zk通知给发起订阅的服务调用方
zk缺陷
早期RPC框架服务发现就是基于zk实现,但后续团队微服务化程度越来越高,zk集群整体压力越来越高,尤其在集中上线时越发明显。“集中爆发”是在一次大规模上线时,当时有超大批量服务节点在同时发起注册操作,ZooKeeper集群的CPU飙升,导致集群不能工作,也无法立马将zk集群重新启动,一直到zk集群恢复后业务才能继续上线。
根本原因就是zk本身性能问题,当连接到zk的节点数量特多,对zk读写特频繁,且zk存储目录达到一定数量,zk将不再稳定,CPU持续升高,最终宕机。宕机后,由于各业务的节点还在持续发送读写请求,刚一启动,zk就因无法承受瞬间的读写压力,马上宕机。
要重新考虑服务发现方案。
4 消息总线(AP)
zk强一致性,集群的每个节点的数据每次发生更新操作,都通知其它节点同时执行更新。它要求保证每个节点的数据实时完全一致,直接导致集群性能下降。
而RPC框架的服务发现,在服务节点刚上线时,服务调用方可容忍在一段时间后(如几s后)发现这个新上线的节点。毕竟服务节点刚上线后的几s内,甚至更长的一段时间内没有接收到请求流量,对整个服务集群没有什么影响,可牺牲掉CP(强制一致性),选择AP(最终一致),换取整个注册中心集群的性能和稳定性。
是否有一种简单、高效,并且最终一致的更新机制,代替zk数据强一致的数据更新机制?最终一致性,可考虑消息总线机制。注册数据可全量缓存在每个注册中心的内存,通过消息总线来同步数据。当有一个注册中心节点接收到服务节点注册时,会产生一个消息推送给消息总线,再通过消息总线通知给其它注册中心节点更新数据并进行服务下发,从而达到注册中心间数据最终一致性。
4.1 总体流程

流程图
• 服务上线,注册中心节点收到注册请求,服务列表数据变化,生成一个消息,推送给消息总线,每个消息都有整体递增的版本
• 消息总线主动推送消息到各注册中心,同时注册中心定时拉取消息。对获取到消息的,在消息回放模块里面回放,只接受大于本地版本号的消息,小于本地版本号的消息直接丢弃,实现最终一致性
• 消费者订阅可从注册中心内存拿到指定接口的全部服务实例,并缓存到消费者的内存
• 采用推拉模式,消费者可及时拿到服务实例增量变化情况,并和内存中的缓存数据进行合并。
为性能,这里采用两级缓存,注册中心和消费者的内存缓存,通过异步推拉模式确保最终一致性。
服务调用方拿到的服务节点不是最新的,所以目标节点存在已下线或不提供指定接口服务的情况,这时咋办?这问题放到RPC框架里处理,在服务调用方发送请求到目标节点后,目标节点会进行合法性验证,若指定接口服务不存在或正在下线,则拒绝该请求。服务调用方收到拒绝异常后,会安全重试到其它节点。
通过消息总线,完成注册中心集群间数据变更的通知,保证数据最终一致性,并能及时触发注册中心的服务下发。服务发现的特性是允许我们在设计超大规模集群服务发现系统的时候,舍弃强一致性,更多考虑系统健壮性。最终一致性才是分布式系统设计更常用策略。
5 总结
通常可使用zk、etcd或分布式缓存(如Hazelcast)解决事件通知问题,但当集群达到一定规模之后,依赖的ZooKeeper集群、etcd集群可能就不稳定,无法满足需求。
在超大规模的服务集群下,注册中心所面临的挑战就是超大批量服务节点同时上下线,注册中心集群接受到大量服务变更请求,集群间各节点间需要同步大量服务节点数据,导致:
• 注册中心负载过高
• 各节点数据不一致
• 服务下发不及时或下发错误的服务节点列表
RPC框架依赖的注册中心的服务数据的一致性其实并不需要满足CP,只要满足AP即可。我们就是采用“消息总线”的通知机制,来保证注册中心数据的最终一致性,来解决这些问题的。
如服务节点数据的推送采用增量更新的方式,这种方式提高了注册中心“服务下发”的效率,而这种方式,还可用于如统一配置中心,用此方式可以提升统一配置中心下发配置的效率。
6 FAQ
某大厂中间件的用户平台,服务挂了,在注册中心上还得手动删除死亡的节点,若是zk,服务没了,就代表会话也没了,临时节点应该会被通知到把?为何还要手动删除?
临时节点是需要等到超时时间之后才删除,不够实时。
如果要能切换流量,要服务端配置权重负载均衡策略,这样服务器端即可通过调整权重安排流量。
服务消费者都是从注册中心拉取服务提供者的地址信息,所以要切走某些服务提供者数据,只需要将注册中心这些实例的地址信息删除(其实下线应用实例,实际也是去删除注册中心地址信息),然后注册中心反向通知消费者,消费者受到拉取最新提供者地址信息就没有这些实例了。
通过服务发现来摘除流量是最常见的手段,还可以上下线状态、权重等方式。
现有开源注册中心是不是还没有消息总线这种实现方式?消息总线有没有开源实现?
现成MQ也可充当消息总线。
消息总栈类似一个队列,队列表示是递增的数字,注册中心集群的任何一个节点接收到注册请求,都会把服务提供者信息发给消息总栈,消息总栈会像队列以先进先出的原则推送消息给所有注册中心集群节点,集群节点接收到消息后会比较自己内存中的当前版本,保存版本大的,这种方式有很强的实效性,注册中心集群也可以从消息总栈拉取消息,确保数据AP,个人理解这是为了防止消息未接收到导致个别节点数据不准确,因为服务提供者可以向任意一个节点发送注册请求,从而降低了单个注册中心的压力,而注册和注册中心同步是异步的,也解决了集中注册的压力,在Zookeeper中,因为Zookeeper注册集群的强一致性,导致必须所有节点执行完一次同步,才能执行新的同步,这样导致注册处理性能降低,从而高I/O操作宕机。
当集中注册时,消息总栈下发通知给注册中心集群节点,对于单个节点也会不停的收到更新通知,这里也存在高I/O问题,会不会有宕机?event bus可以改造成主从模式保证高可用。
AP实现中“两级缓存,注册中心和消费者的内存缓存,通过异步推拉模式来确保最终一致性的具体实现?
推主要实现callback,拉的动作在客户端。
消息总线策略怎么保证消息总线全局版本递增?最简单的用时间戳。
消息总线构建ap 型注册中心,不是很理解。是多个注册中心独立提供读写,他们之间通过消息队列做数据同步?那么一致性感觉不好保证,比如服务a 先注册,再反注册,但是分别发到两个注册中心节点,最终同步可能是乱序的哇?一般不会出现这种情况,只有连接断开后,那需要重新注册。
消息总线的另一个应用case:配置中心。