据说,ChatGPT用了5000块GPU,而对于普通工程师而言,看看过去,或许可以帮助望见未来。那么,GPU是什么呢?
图形处理器(GPU,Graphic Processing Unit)是面向吞吐率设计、片上集成大量并行计算部件的处理器。2006年采用统一架构的GPU和使用高级语言编程的开发平台的出现,引发了GPU通用计算领域的迅猛发展。
1. GPU 溯源
早在计算机图形学发展初期,图形显示受硬件条件的限制,仅作为计算机输出的一种手段。图形处理计算基本由软件实现,也称为“软解压”,硬件负责输出计算结果。随着游戏市场和图形计算领域的应用需求迅速发展,其发展速度甚至超过了摩尔定律的限制。GPU的功能性越来越丰富,计算能力也越来越强大。每一代GPU的推出都会带来新的变革,都深刻影响着其应用领域。
第一代GPU出现在1998年,主要处理光栅化以及多纹理操作,但硬件不支持坐标变换和光照变换。主要代表为NVIDIA TNT2等。
第二代GPU出现在1999年,增加了对坐标变换和光照变换计算的硬件支持,可以使用硬件来完成光影处理以及几何变换等特效,为CPU减轻了大量的计算任务,但不具备可编程性。主要代表为NVIDIA GeForce256和ATI Radeon 7500等。
第三代GPU出现在2001年,实现了完全可编程的完整3D图形处理流程。在顶点级上支持可编程性,在像素级上实现了有限的可编程性。主要代表为NVIDIA GeForce3/4和ATI Radeon 8500等。
第四代GPU出现在2003年,像素和顶点的可编程性更通用化,GPU进入了完全可编程时代。同时,GPU还配备了浮点计算功能。主要代表为NVIDIA GeForce FX和ATI Radeon 9700/9800。
第五代GPU出现在2004年,增加了更多的着色器功能。顶点着色器可以访问纹理,支持动态分支操作。像素着色器支持分支操作、子函数调用、64位浮点纹理滤波和融合以及多目标渲染等。主要代表有NVIDIA GeForce 6800 等。
新一代的GPU出现在2006年,采用完全统一渲染架构设计,将分离的可编程流水阶段映射到统一的处理器阵列上,从而使得计算资源在顶点着色、几何处理以及像素处理等任务之间动态配置,取得良好的负载平衡。主要代表有NVIDIA Geforce 8800等。统一架构GPU的出现带来了革命性的变革,伴随着相应开发平台的推出,GPU不再限于传统的图形计算和游戏领域,开始更广泛地应用于通用计算领域,推进了高性能计算以及科学计算领域的快速发展。
2.GPU的处理流水线
2.1 固定功能流水线
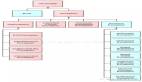
在图形流水线引入可编程性之前,GPU一直采用固定功能流水线,使用固定功能单元处理计算的各个步骤。应用程序通过API库(如微软的DirectX和开放性标准OpenGL)提供的接口函数,实现应用程序功能。固定功能图形流水线中的主要步骤如下图所示。

主机接口一般负责GPU和主机之间的数据传输。图形处理之前图像中物体表面被分解为三角形图元的集合,顶点是指三角形图元的角。顶点控制部件负责接收参数化的三角形图元数据,执行数据转化,存入顶点缓存中。顶点着色、变换和光照部件对顶点进行坐标变换、光照计算后,图元装配和光栅化操作对几何图元进行纹理和颜色的插值,生成和窗口屏幕像素相对应的片元(Fragment)。片元具有窗口坐标、颜色、纹理坐标、雾化坐标等属性。着色(Shader)阶段则对片元实施纹理映射、颜色插值以及光照反射等操作,计算出三角形图元中每个像素的最终颜色。最后,光栅操作部件(ROP,Raster OPeration)对像素执行颜色混合、透明以及反锯齿操作。帧缓冲区接口(FBI,Frame Buffer Interface)负责管理显示的读写操作。
2.2 可编程流水线
尽管GPU的硬件功能和图形API不断扩展,但仍然满足不了应用快速变化的新需求。2001年3月,NVIDIA公司推出了具有着色器可编程能力的GeForce 3系列,相关图形API升级到DirectX 8和顶点着色器扩展OpenGL。之后,为了与DirectX 9匹配,GPU又扩展了像素着色阶段的通用可编程性和浮点计算功能。GPU的可编程流水线如下图所示——

GPU的可编程性主要体现在两个部分:顶点处理器(VP,Vertex Processor/Engine)和片元处理器(FP,Fragment Processor/Engine)。可编程顶点处理器主要负责执行顶点着色程序,执行几何变换和光照计算等操作。可编程片元处理器主要负责执行像素着色程序,执行纹理混合等操作。可编程性的引入带来了图形处理的多样化和可变性。而固定功能顶点处理器只能实现固定的光照模型和坐标转换,固定功能片元处理器只能实现有限的颜色混合和纹理映射。使用灵活的程序设计代替流水线中的固定操作,不但促进了图形计算领域和游戏市场的飞跃性发展,同时还引发了GPU在通用计算领域中的广泛应用。
2.3 统一架构图形流水线
虽然GPU引入了可编程性,但仍采用功能部件的分离设计。由于应用特征决定了各流水线阶段的负载不同,计算任务分离的功能单元设计会导致应用性能受限于各阶段计算量比例与功能单元配置之间的不匹配,从而导致计算资源的闲置。而实现不同任务的不同类型着色程序之间具有数据不相关和执行独立的特征,促使了GPU设计从可编程流水线阶段向大规模并行统一架构处理器的结构变迁,下图给出了GPU设计从分离设计到统一架构的示意。

AMD于2005年初在Xenos中实现了统一处理架构,并于2006年率先宣布了面向高性能计算的流处理器(Stream Processor)。NVIDIA也于2006发布了采用统一架构G80,并于同年11月引入了统一架构计算平台(CUDA,Compute Unified Device Architecture)。G80架构严格遵守了微软Direct X10统一渲染架构的规范,使用统一计算阵列以及采用多线程并行执行模式处理顶点着色器(VS,Vertex Shader)、像素着色器(PS,Pixel Shader)以及新引入的几何着色器(GS,Geometry Shader)的计算任务。统一计算阵列在进行顶点着色、几何计算以及像素处理时,能够动态划分计算资源。由于不同的渲染算法在三个处理阶段存在不同的负载,因此统一架构能够充分利用计算资源,取得很好的负载平衡。
3.基于GPU的通用计算
直到2006年统一架构计算平台的出现,GPU在通用计算领域中的研究才成为业界的研究热点。
3.1 可编程GPU
可编程GPU中的顶点处理器和片元处理器都是典型的流处理器,没有大容量的存储器以供读写,只是在芯片上利用临时寄存器执行流数据相关的操作。在GPU,流数据即为顶点图元和光栅化后的像素。GPU处理的流数据元素为4单元向量,用以表示四维坐标、三维空间齐次向量以及颜色等。顶点处理器和片元处理器都采用SIMD执行模式并行执行不同的流数据元素。因此,GPU兼具流处理器和向量处理器的特征。

这种流处理并行结构为通用计算提供了并行计算的平台。顶点处理器比较适用于除图形绘制以外的几何操作类应用,而片元处理器由于拥有大容量的“纹理”存储空间,因此可以更广泛地用于各种通用计算。将可编程GPU应用于通用计算领域,必须采用图形绘制语言或流编程语言来编写程序,如OpenGL着色语言等。
GPU计算是基于矢量的运算,一般先将待解决问题转化为能够用矢量表示的问题,强制转化、分解为图形操作。使用图形绘制语言编写程序,调用DirectX或OpenGL等图形API启动计算过程。输入的数据集合必须存储在纹理图像中,再以三角形图元的形式提交给GPU处理,光栅化操作的结果数据强制转化为像素集的形式输出。这种间接的实现方式极大地限制着GPU在通用计算领域中的应用。同时,GPU本身固有的访存模式也限制了GPU领域发展的主要因素。计算之间传递数据需要通过像素帧缓冲区,作为纹理映射输入,再把帧缓冲区用于其它计算。
3.2 基于统一架构的GPU
NVIDIA G80统一架构如下图所示:

由于G80统一架构采用多线程并行执行模式处理顶点着色器、像素着色器以及几何着色器的计算任务,因此体系结构中的线程管理器实际上由顶点处理线程逻辑、像素处理线程逻辑以及几何处理线程逻辑等三个指令分派单元构成,分别负责顶点指令、像素指令和几何处理指令的译码和分发。
目前,统一架构GPU已广泛应用于高性能计算、科学计算和工程计算等领域,具体的应用领域包括:医学成像、分子动力、生物医药、视频转换、金融分析、线性代数、天体物理、基因排序、天气预报、石油勘探以 及地震探测等。
4. GPU 硬件架构
G80系列是NVIDIA公司最早推出的统一架构GPU,总体上看,G80由两部分组成,分别为流处理器阵列(SPA,Stream Processor Array)和存储系统,这两部分由一个片上交叉互连网络连接,因此系统 具有良好的扩展性。NVIDIA将统一结构中的基本计算单元称为流多处理器(SM,Streaming Multiprocessors)
AMD-ATI的第一代统一架构RV670架构与NVIDIA统一架构设计理念不同的是,R600的设计思想兼顾线程级并行和指令级并行。早期的R600架构具备64个5D VLIW线程处理器(TP,Thread Processor),每16个线程处理器构成一个SIMD引擎(SE,SIMD Engine),采用SIMD执行模式执行VLIW指令。每个线程处理器中有5个异构流核心(SC,Stream Core),负责执行编译器打包的VLIW指令。
而NVIDIA统一架构中一个SM中的8个流核心完全对称,采用SIMD执行模式在不同数据上执行相同指令。线程处理器中的T-Stream Core功能最强,负责执行超越函数;另外四个称为x、y、z和w的通用流核心则是完全相同,负责执行基本的32位整数和浮点操作。线程处理器以VLIW模式来控制5个核心同时执行运算操作。除计算阵列之外,AMD GPU统一架构中还包括了一些主要控制模块,如命令处理器(Command Processor)、存储控制器(Memory Controller)以及超线程管理调度器(Ultra-Threaded Dispatch Processor)。
NVIDIA于2010年推出的基于Fermi架构的GTX480,采用40nm制造工艺,片上集成30亿个晶体管,双精度浮点计算性能达到768 GFLOPS。Fermi架构在全芯片架构上进行了全新的设计,在面向通用计算的架构设计上实现了飞跃。

GPU在持续演进与发展,2020年,NVIDIA推出了基于Ampere架构的GPU A100。Ampere架构仍然沿用了成熟的GPC-TPC-SM多级架构,GA100内部包含8组GPC,每组GPC包含8组TPC,每组TPC又包含8组SM。主要的区别点在于,中间的L2缓存不再是统一的一组,而是被分割成了两组。实际上,GA100的L2缓存相比起前代的GV100要大上近7倍——从原本的6MB直接跳到了40MB。大容量的L2缓存会在一定程度上减轻计算单元对显存带宽的依赖,不过为了避免访问远端L2缓存时出现延迟过高的问题,它被分成了两块,保证延迟不过高。这种大容量特性和分割结构让GA100的L2缓存带宽提升了2.3倍,同时硬件的缓存一致性保证应用程序可以自动利用大容量的L2缓存提升性能。

基于NVIDIA Ampere架构的NVIDIA A100 GPU旨在通过其许多新的架构功能和优化提供尽可能多的AI和HPC计算能力。A100基于台积电 7nm N7 FinFET制造工艺,与特斯拉V100中使用的12nm FFN工艺相比,该工艺提供了更高的晶体管密度、改进的性能和更好的功率效率。新的多实例GPU(MIG)功能为多租户和虚拟化GPU提供了增强的客户端/应用程序故障隔离和对云服务提供商特别有利的环境。第三代NVIDIA的NVLink互连速度更快、更具容错能力,为超大规模数据中心提供了改进的多GPU性能扩展。
5. GPU开发平台
CUDA(Compute Unified Device Architecture)是在NVIDIA统一架构GPU上面向通用计算的并行编程开发平台。CUDA开发平台中包含了不同层次的调用接口,其中包括一组运行时API、一组设备驱动API以及CUDA提供的函数库API。CUDA平台的体系结构如图2.13所示。
CUDA驱动API能够直接控制底层硬件结构,CUDA运行时API则是对驱动API的封装。程序设计过程中既可以调用CUDA驱动API实现对硬件更高效的控制,也可以使用CUDA运行时API更便捷、更直观地实现CUDA开发平台提供的计算模式。

开发库是基于 CUDA 技术所提供的应用开发库。其中,CUDA 包含了两个重要的标准数学运算库——CUFFT(离散快速傅立叶变换)和 CUBLAS(离散基本线性计算)。这两个数学运算库所解决的是典型的大规模的并行计算问题,也是在密集数据计算中非常常见的计算类型。
运行时环境提供了应用开发接口和运行时组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。基于 CUDA 开发的程序代码在实际执行中分为两种,一种是运行在 CPU 上的宿主代码(Host Code),一种是运行在GPU上的设备代码(Device Code)。不同类型的代码由于其运行的物理位置不同,能够访问到的资源不同,因此对应的运行期组件也分为公共组件、宿主组件和设备组件三个部分,基本上囊括了所有在 GPGPU 开发中所需要的功能和能够使用到的资源接口,开发人员可以通过运行期环境的编程接口实现各种类型的计算。CUDA 提供的运行时环境是通过驱动来实现各种功能的。
CUDA 支持 Windows、Linux、MacOS 三种主流操作系统,支持 CUDA C 语言和 OpenCL 及 CUDA Fortran 语言。无论使用何种语言或接口,指令最终都会被驱动程序转换成 PTX(Parallel Thread Execution,并行线程执行,CUDA架构中的指令集,类似于汇编语言)代码,交由显示核心计算。
6.小结
本文简要回顾了对GPU流水线和体系结构的变迁,初步了解了NVIDIA及AMD的统一架构,及其设计理 念上的异同,以及GPU开发平台编程模型和执行机制。据说,ChatGPT用了5000块GPU,而对于普通工程师而言,看看过去,或许可以帮助照见未来。
【参考资料】
- Evolution of the Graphics Processing Unit (GPU),https://ieeexplore.ieee.org/document/9623445
- https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/
- https://zhuanlan.zhihu.com/p/521471323
- http://cjc.ict.ac.cn/quanwenjiansuo/2013-4/whf.pdf