当前,很多自然语言处理(NLP)应用需要高质量的标注数据来支撑,特别是当这些数据被用于训练分类器或评估无监督模型的性能等任务中。
例如,人工智能研究人员通常希望过滤嘈杂的社交媒体数据的相关性,将文本分配到不同的主题或概念类别,或衡量其情绪或立场。
而且,无论这些任务使用什么具体方法(监督、半监督或无监督),都需要标注好的数据来建立一个训练集或黄金标准。
然而,在大多数情况下,要完成高质量的数据标注(data annotation)工作,依然离不开数据标注平台上的众包工作者或诸如研究助理等训练有素的标注者来手动进行。
通常情况下,训练有素的标注者先创建一个相对较小的黄金标准数据集,然后雇用众包工作者来增加标注数据的数量,进行重复性工作。根据规模大小和复杂程度,数据标注任务有时会非常费时费力,不仅需要花费一定的人力成本,而且也不能保证数据标注的质量。
那么,能否让机器帮助人类完成这一基础任务呢?
在以往的认知中,机器并不擅长这类「慢工出细活」的任务,但出乎意料的是,「数据标注」这件事已经让 ChatGPT 完成了,而且比大多数人做得还更好。

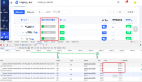
在一项今天发表的新研究中,来自苏黎世大学的研究团队使用由 2382 条推文组成的样本,证明了 ChatGPT 在相关性、主题和框架检测等标多个注任务上优于众包工作者。
相关研究论文以「ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks」为题,已发表在预印本网站 arXiv 上。
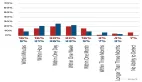
具体来说,ChatGPT 在五项任务的四项中的零样本(zero-shot)准确率超过了众包工作者;在所有任务中表现出的编码者间一致性(intercoder agreement)方面,ChatGPT 不仅超过了众包工作者,也同样超过了训练有素的标注者。

ChatGPT 零样本文本数据标注表现
值得一提的是,ChatGPT 的每个标注成本只有不到 0.003 美元,而比数据标注平台便宜约 20 倍。
研究团队认为,虽然需要进一步的研究来更好地了解 ChatGPT 和其他 LLMs 在更广泛的背景下的表现,但该研究结果表明,它们有可能改变研究人员进行数据注释的方式,极大地提高文本分类的效率,并破坏数据标注平台的部分商业模式。
至少,从目前来看,这些发现表明了更深入地研究 LLMs 的文本标注特性和能力的重要性。
未来,研究团队将在 ChatGPT 在多种语言中的表现、ChatGPT 在多种类型的文本(社会媒体、新闻媒体、立法、演讲等)中的表现、使用思维链(CoT)提示和其他策略来提高零样本推理的性能等方面继续努力。
值得一提的是,研究团队在进行这项工作时,OpenAI 还没有发布 GPT-4,如果让 GPT-4 来完成数据标注任务,又会是怎样的结果呢?