












一、业务背景
最近遇到这样一个场景:在业务正式开始前1-2天,需要导入一批来自合作渠道的数据,在业务周期结束后,再将同一批数据导出,交付给渠道方;
简单理解,就是数据的「导入」和「导出」;
但是场景复杂度的高低与否,与实现流程和逻辑的复杂度并无什么必然联系,数据在「导入」和「导出」之间,通常还会横着复杂的「业务逻辑」;
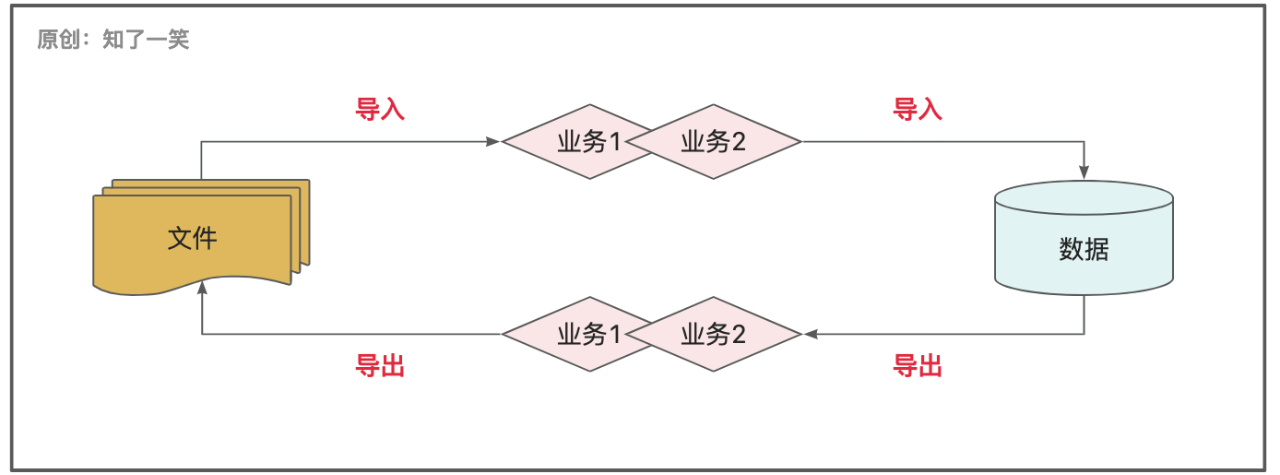
数据如果只是在文件和单表直接来回捣腾,解决的方案简直花里胡哨,然而在应用中数据导入导出,更多还是要集成业务需求,自然也就绕不开业务的处理逻辑;
二、场景分析
1、文件特征
文件:「Excel」类型,并且表头是固定格式,字段内容虽然有要求,但是难免存在细微的误差问题;
内容:条数「1000」以内,单条数据「150+」个字段,业务结束后导出,会添加业务结果和明细相关字段,最终在「200」个字段左右;
2、业务特征
文件导入后,数据在业务之间流转时,需要构建相应的主体结构,比如基础的「客户档案」,「业务档案」,业务处理过程中会生成「明细」,处理完成后会生成「结果」;
3、数据规则
【客户档案】
数据在入库的过程中,需要校验「客户归属」问题,库内已有的客户基于「跟进时间」执行「更新逻辑」,库内没有的客户需要「新增」并「分配跟进人员」;
【业务档案】
跟随「客户档案」的逻辑,如果客户更新,则「业务档案」更新,如果客户不更新,则「业务档案」不更新,如果客户新增,则「业务档案」直接新增即可;
【数据校验】
客户的「基础档案」和「业务档案」的入库逻辑,完全遵守产品体系现有的限制规则,在逻辑拦截时尽量输出全面的拦截原因,方便商务人员对文件数据进行修改调整;
三、流程设计
1、业务流程
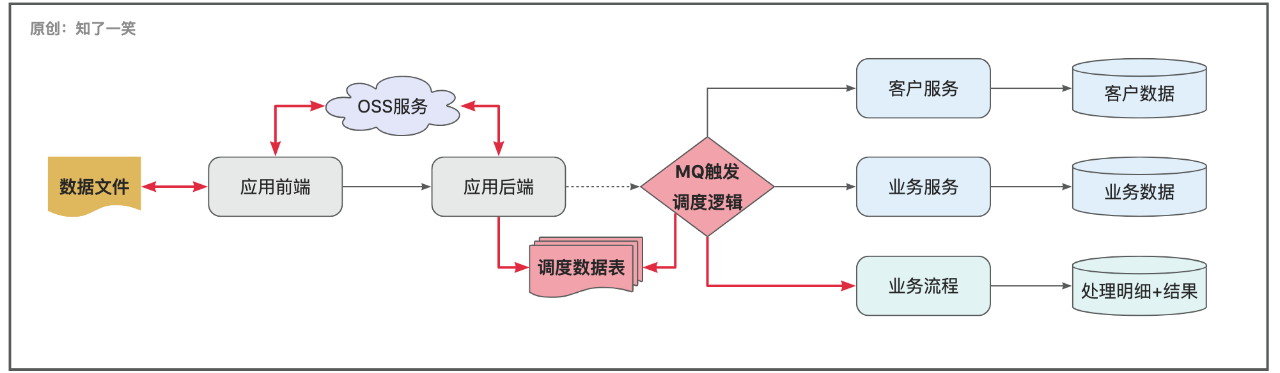
业务流程从整体上可以拆分四段来看:动作确认、动作监听、数据处理、业务处理;
【动作确认】
- 「导入」应用前端完成文件上传OSS的处理,向应用后端提交数据导入的请求,接收请求后会异步处理;
- 「异常记录下载」会实时响应,功能上看就是一个单表导出,需要返回业务拦截和异常信息;
- 「导出」因为交付时间不确定性,所以由商务人员手动触发导出,后端组装完成后提交OSS文件服务器,等待下载;
【动作监听】
- 「导入」和「导出」的动作监听,进而触发相应的流程逻辑;
【数据处理】
- 「客户档案」提交给客户服务处理,如果处理失败,无法围绕客户构建业务流,直接中断全部流程;
- 「业务档案」提交给业务服务处理,这里指业务属性的资料信息,并非场景流程;
【业务处理】
- 「数据导入」的真正目的,依赖系统的处理能力,从而实现相应的业务流程,在过程中会生成关键明细和结果数据;
2、导入流程
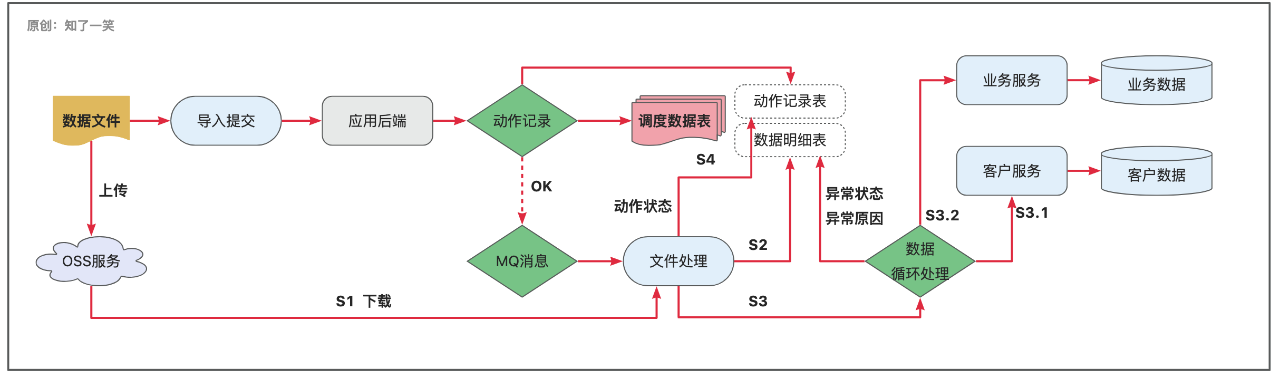
- 【1】应用后端接收用户提交的「导入」请求,动作接收成功后立即响应;
- 【2】完成「导入」记录的存储之后,通过MQ消息队列,解耦文件数据的处理流程;
- 【3】对文件进行解析,读取源数据并存储到明细表;
- 【4】遍历明细数据分别实现「客户」和「业务」的档案存储,此处会把失败原因最大限度回写到明细记录中,方便商务二次导入;
- 【5】完成数据入库后,更新「导入」动作的状态,最核心的是提供失败记录的明细和下载功能;
3、导出流程
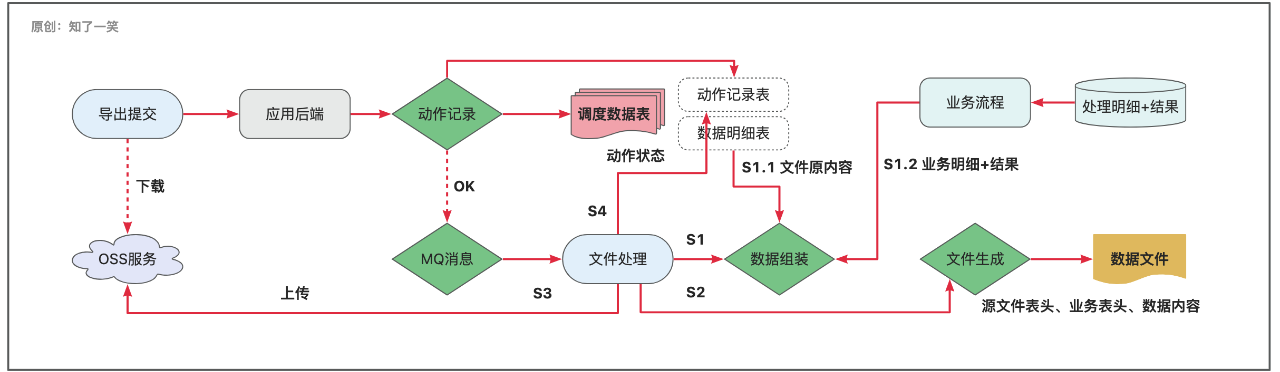
- 【1】应用后端接收用户提交的「导出」请求,动作接收成功后立即响应,初始状态为:「处理中」;
- 【2】完成「导出」记录的存储之后,通过MQ消息队列,解耦文件的「创建」和「上传」流程;
- 【3】文件数据分为两部分,文件原内容和业务处理结果,组装为新的数据结构;
- 【4】创建新的文件,涉及数据表头的合并,数据内容的合并,以及「Excel」的格式构建,从而完成文件的生成过程;
- 【5】将生成的文件上传到文件服务器,由商务人员自行下载并导出,然后交付给渠道方;
四、结构设计
数据导入的表结构,是由具体业务场景决定的,此处就不做展示了;这里只看一看导入导出的调度表结构,即操作记录和状态以及数据明细的存储;
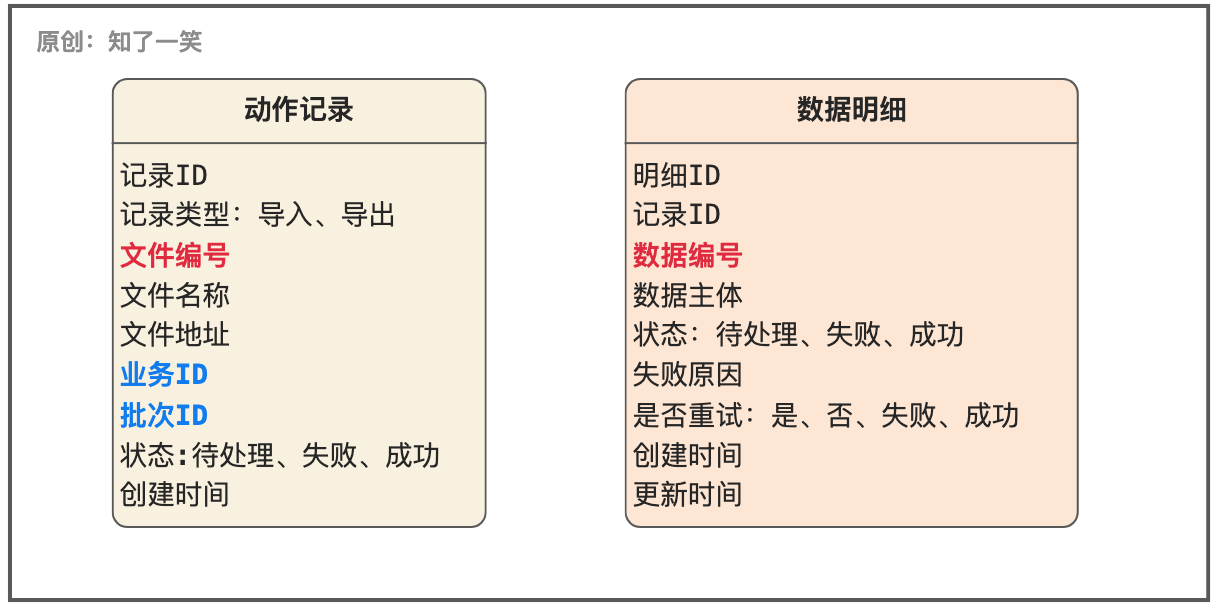
【动作记录】
存储「导入」和「导出」的请求记录,都涉及文件信息的管理,至于「业务ID」和「批次ID」是指集成业务的处理流程,同时也可以基于该「ID」限制同批次下的重复动作,降低不必要的资源占用;
【数据明细】
在「导入」的时候,对文件数据的临时记录表,方便对数据的多次读取和处理,避免流程中断导致文件的重复解析;
在「导出」的时候,需要依赖原数据的构建新的「Excel」文件,在交付渠道方时保证原内容的不变,只新增系统中业务的处理明细和结果;
五、实践总结
虽然对于「Excel」或者其他文件的「导入」和「导出」的参考案例很多;
但是在研发实践中,这依旧是一个不容易实现的过程,在数据和文件互相搬运的过程中,如何与「业务场景」进行平稳的集成,才是真正的复杂逻辑;
从开始工作直到现在,关于「导入」和「导出」的实现方案参考或者落地过很多个,整体可以从两个方向考虑;
【应用系统】
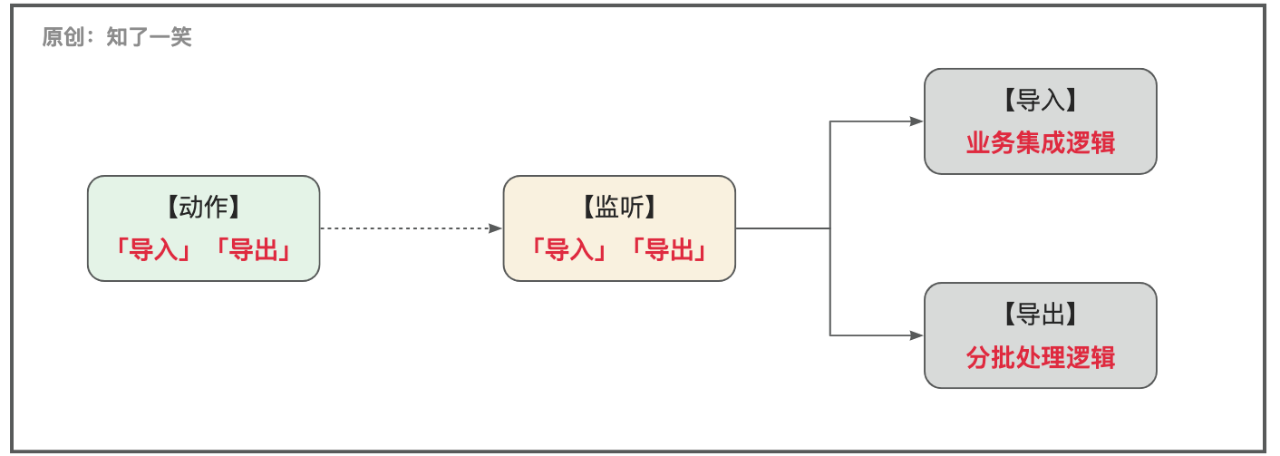
通常文件格式是「Excel」、「Word」、「Pdf」等,并且涉及的数据体量并不大,采取「异步」的方式解耦即可;
对于文件的「导入」来说,需要重点考虑的逻辑,在于如何与业务平稳集成,在出现问题时,能够给产品页面准确的信息反馈,从而提高文件的二次处理效率;
对于数据的「导出」来说,是一个「高危」的操作,通常是不分配大量数据的导出「权限」,如果有需求则要对数据进行计算分「批次」导出;
【数据系统】
数据体量较大的情况下,不推荐从应用系统考虑「优化」的策略;
如何确定「数据体量较大」的临界值,需要测试系统的处理能力,系统业务流量高峰时,去「并发」执行导入和导出,从而得出合理的数值,不过大部分产品都是限制单文件最大「5000」条;
从分布式架构中组装大量的数据并「导出」文件,其资源占用过高,并非主流的实践方案;
当下比较常见的方式,直接从「数据层面」入手,搭建「传输」或「转换」的通道,以「API」或者「页面入口」的方式,触发流程即可;

在数据体量超过应用系统的处理能力时,会搭建专用的「数据传输通道」来处理;
这种模式在数据型业务中很常用,可以隔离大量数据的「IO流」操作,确保应用系统运行的安全稳定,也可以极大提升数据和文件互相搬运的处理效率;










