针对不同类型的ast节点根据节点的含义执行word/space/token/newline等方法生成代码,这些方法里都会执行append方法添加要生成的字符串代码。
SourceMap的用途
前端工程打包后代码会与源码产生不一致,当代码运行出错时控制台会定位出错代码的位置。SourceMap的用途是可以将转换后的代码映射回源码,如果你部署了js文件对应的map文件资源,那么在控制台里调试时可以直接定位到源码的位置。
SourceMap的格式
我们可以生成一个SouceMap文件看看里面的字段分别都对应什么意思,这里使用webpack打包举例。
源码:
//src/index.js
function a() {
for (let i = 0; i < 3; i++) {
console.log('s');
}
}
a();
打包后的代码:
//dist/main-145900df.js
!function(){for(let o=0;o<3;o++)console.log("s")}();
//# sourceMappingURL=main-145900df.js.map
.map文件:
//dist/main-145900df.js.map
{
"version": 3,
"file": "main-145900df.js",
"mappings": "CAAA,WACE,IAAK,IAAIA,
EAAI,EAAGA,EAAI,EAAGA,IACrBC,QAAQC,IAAI,KAGhBC",
"sources": ["webpack://source-map-webpack-demo/./src/index.js"],
"sourcesContent": ["function a() {\n for (let i = 0; i < 3; i++) {\n console.log('s');\n }\n}\na();"],
"names": ["i", "console", "log", "a"],
"sourceRoot": ""
}
- version:目前source map标准的版本为3;
- file:生成的文件名;
- mappings:记录位置信息的字符串;
- sources:源文件地址列表;
- sourcesContent:源文件的内容,一个可选的源文件内容列表;
- names:转换前的所有变量名和属性名;
- sourceRoot:源文件目录地址,可以用于重新定位服务器上的源文件。
这些字段里大部分都很好理解,接下来主要解读mappings这个字段是通过什么规则来记录位置信息的。
mappings字段的定义规则
"mappings": "CAAA,WACE,IAAK,IAAIA,
EAAI,EAAGA,EAAI,EAAGA,IACrBC,QAAQC,IAAI,KAGhBC",
为了尽可能减少存储空间但同时要达到记录原始位置和目标位置映射关系的目的,mappings字段按照了一些特殊的规则来生成。
- 生成文件中的一行作为一组,用“;”隔开。
- 连续的字母共同表示一个位置信息,用逗号分隔每个位置信息。
- 一个位置信息由1、4或5个可变长度的字段组成。
- // generatedColumn, [sourceIndex, originalLine, orignalColumn, [nameIndex]]
- 第一位,表示这个位置在转换后的代码第几列,使用的是相对于上一个的相对位置,除非这是这个字段的第一次出现。
- 第二位(可选),表示所在的文件是属于sources属性中的第几个文件,这个字段使用的是相对位置。
- 第三位(可选),表示对应转换前代码的第几行,这个字段使用的是相对位置。
- 第四位(可选),表示对应转换前代码的第几列,这个字段使用的是相对位置。
- 第五位(可选),表示属于names属性中的第几个变量,这个字段使用的是相对位置。
- 字段的生成原理是将数值通过vlq-base64编码转换成字母。
vlq原理
vlq是Variable-length quantity的缩写,是一种通用的,使用任意位数的二进制来表示一个任意大的数字的一种编码方式。
SourceMap中的编码流程是将位置从十进制数值—>二进制数值—>vlq编码—>base64编码最终生成字母。
// Continuation
// | Sign
// | |
// V V
// 101011
vlq编码的规则:
- 一个数值可能由多个字符组成
- 对于每个字符使用6个2进制位表示
如果是表示数值的第一个字符中的最后一个位置,则为符号位。
否则用于实际有效值的一位。
0为正,1为负(SourceMap的符号固定为0),
第一个位置是连续位,如果是1,代表下一个字符也属于同一个数值;如果是0,表示这个字符是表示这个数值的最后一个字符。
最后一个位置
- 至少含有4个有效值,所以数值范围为(1111到-1111)即-15到15的可以由一个字符表示。
数值的第一个字符有4个有效值
之后的字符有5个有效值
最后将6个2进制位转换成base64编码的字母,如图。

举例编码数值29
数值29(十进制)=11101(二进制)
1|1101
先取低四位,数值的第一个字符有四个有效值1101
11010-----------最后加上符号位
111010----------开头加上连续位1(后面还有字符表示同一个数值)
6---------------转换为base64编码对应是6
数值的第二个字符
00001----------补充有效位
000001--------开头加上连续位0(表示是数值的最后一个字符)
B---------------转换为base64编码
29=》6B
我们将上述转换的规则通过代码方式呈现:
代码实现vlq编码
先在最后添加一个符号位,从低位开始截取5位作为一个字符,截取完若还有数值则在截取的5位前添加连续位1,即生成好一个字符;最后一个字符的数值直接与011111进行与运算即可。
//https://github.com/mozilla/source-map/blob/HEAD/lib/base64-vlq.js
const base64 = require("./base64");
//移动位数
const VLQ_BASE_SHIFT = 5;
// binary: 100000
const VLQ_BASE = 1 << VLQ_BASE_SHIFT;
//1左移5位:100000=32
// binary: 011111
const VLQ_BASE_MASK = VLQ_BASE - 1;
// binary: 100000
const VLQ_CONTINUATION_BIT = VLQ_BASE;
//符号位在最低位
//1.1左移一位并在最后加一个符号位
function toVLQSigned(aValue) {
return aValue < 0 ? (-aValue << 1) + 1 : (aValue << 1) + 0;
}
/**
* Returns the base 64 VLQ encoded value.
*/
function base64VLQ_encode(aValue) {
let encoded = "";
let digit;
let vlq = toVLQSigned(aValue);//第一步:左移一位,最后添加符号位
do {
digit = vlq & VLQ_BASE_MASK;
//第二步:vlq和011111进行与运算,获取字符中已经生成好的后5位
//从低位的5位开始作为第一个字符
vlq >>>= VLQ_BASE_SHIFT;//vlq=vlq>>>5
//第三步:vlq右移5位用于截取低位的5位,对剩下的数值继续进行操作
if (vlq > 0) {
//说明后面还有数值,则要在现在这个字符开头加上连续位1
digit |= VLQ_CONTINUATION_BIT;//digit=digit|100000,与100000进行或运算
}
encoded = encoded+base64.encode(digit);//第四步:生成的vlq字符进行base64编码并拼接
} while (vlq > 0);
return encoded;
};
exports.encode = base64VLQ_encode;
举例解码字符6B
6B
第一个字符
6=>111010--------base64解码并转换为二进制
111010------------符号位
110110------------连续位(表示后面有字符表示同一个数值)
第一个字符有效值value=1101
第二个字符
B=>000001------base64解码并转换为二进制
000001----------有效值
000001----------连续位(表示后面没有字符表示同一个数值)
第二个字符的有效值value=00001
合并value=000011101转为十进制29
代码实现vlq解码
从左到右开始遍历字符,对每个字符都先去除连续位剩下后5位数值,将每个字符的5位数值从低到高拼接,最后去除处在最低一位的符号位。
//https://github.com/Rich-Harris/vlq/blob/HEAD/src/index.js
/** @param {string} string */
export function decode(string) {
/** @type {number[]} */
let result = [];
let shift = 0;
let value = 0;
for (let i = 0; i < string.length; i += 1) {//从左到右遍历字母
let integer = char_to_integer[string[i]];//1.base64解码
if (integer === undefined) {
throw new Error('Invalid character (' + string[i] + ')');
}
const has_continuation_bit = integer & 100000;//2.获取连续位标识
integer =integer & 11111;//3.移除符号位获取后5位
value = value + (integer << shift);
//4.从低到高拼接有效值
if (has_continuation_bit) {
//5.有连续位
shift += 5;//移动位数
} else {
//6.没有连续位,处理获取到的有效值value
const should_negate = value & 1;//获取符号位
value =value >>>1;//7.右移一位去除符号位,获取最终有效值
if (should_negate) {
result.push(value === 0 ? -0x80000000 : -value);
} else {
result.push(value);
}
// reset
value = shift = 0;
}
}
return result;
}
整个转换流程举例
源码:
//src/index.js
function a() {
for (let i = 0; i < 3; i++) {
console.log('s');
}
}
a();打包后的代码:
//dist/main-145900df.js
!function(){for(let o=0;o<3;o++)console.log("s")}();
//# sourceMappingURL=main-145900df.js.map.map文件:
//dist/main-145900df.js.map
{
"version": 3,
"file": "main-145900df.js",
"mappings": "CAAA,WACE,IAAK,IAAIA,
EAAI,EAAGA,EAAI,EAAGA,IACrBC,QAAQC,IAAI,KAGhBC",
"sources": ["webpack://source-map-webpack-demo/./src/index.js"],
"sourcesContent": ["function a() {\n for (let i = 0; i < 3; i++) {\n console.log('s');\n }\n}\na();"],
"names": ["i", "console", "log", "a"],
"sourceRoot": ""
}
CAAA
[1,0,0,0]
转换后的代码的第1列
sources属性中的第0个文件
转换前代码的第0行。
转换前代码的第0列。
对应function
WACE
[11,0,1,2]
转换后的代码的第12(11+1)列
sources属性中的第0个文件
转换前代码的第1行。
转换前代码的第2列。
对应for
IAAK
[4,0,0,5]
转换后的代码的第16(12+4)列
sources属性中的第0个文件
转换前代码的第1行。
转换前代码的第7(2+5)列。
对应let
SourceMap使用的规则是如何优化存储位置信息空间的?
SourceMap规范进行了版本迭代,最初,规范对所有映射都有非常详细的输出,导致SourceMap大约是生成代码的10倍。第二个版本减少了50% 左右,第三个版本又减少了50% 。
因为如果生成的位置信息内容比源码还多未免有些得不偿失,所以这样的规则是在尽可能的减小存储空间。
我们可以来总结一下这个规则里使用到的优化点:
- 使用相对位置,使位置数值尽可能小,在后续计算中获取真实的位置数值,从而减少存储空间;
- 使用vlq-base64编码减少存储空间,如32000=》ggxT,通过计算减少存储空间;
- 行数信息直接用;分割来表示。
解析babel生成SourceMap的实现方式
我们日常的各种转译/打包工具是如何生成SourceMap的,这里来解析一下babel生成SourceMap的实现方式。
我们大概需要以下三个步骤来生成SourceMap:
- 获取源码的行列信息
- 获取生成代码的行列信息
- 将前后一一对应起来,然后进行vlq-base64编码并按照规则生成sourcemap文件。
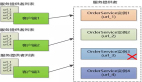
babel流程
babel主要执行了三个流程:解析(parse),转换(transform),生成(generate)。
parse解析阶段(获得源码对应的ast)=》transform(plugin插件执行转换ast)=》generate通过ast生成代码
parse和transform阶段
在解析和转换的阶段,源码对应的ast经过一些plugin的执行后节点的类型或者值会发生改变,但节点中有一个loc属性(类型为SourceLocation)会一直记录着源码最开始的行列位置,所以获取到源码的ast就能够得到源码中的行列信息。
generate阶段生成SourceMap
generator阶段通过ast生成转译后的代码,在这个阶段会对ast树进行遍历。
针对不同类型的ast节点根据节点的含义执行word/space/token/newline等方法生成代码,这些方法里都会执行append方法添加要生成的字符串代码。
在此之中有一个记录生成代码的行列信息属性会按照添加的字符串长度进行不断的累加,从而得到转译前后行列信息的对应。
//packages/babel-generator/src/index.ts
export default function generate(
ast: t.Node,
opts?: GeneratorOptions,
code?: string | { [filename: string]: string },
) {
const gen = new Generator(ast, opts, code);
//1.传递ast新建一个Generator对象
return gen.generate();
}
class Generator extends Printer {
generate() {
return super.generate(this.ast);
}
}
//packages/babel-generator/src/printer.ts
class Printer {
generate(ast) {
this.print(ast);
//2.通过ast生成代码
this._maybeAddAuxComment();
return this._buf.get();
}
print(node, parent?) {
if (!node) return;
const oldConcise = this.format.concise;
if (node._compact) {
this.format.concise = true;
}
const printMethod = this[node.type];
//获取不同节点类型对应的生成方法
//....
//调用
this.withSource("start", loc, () => {
printMethod.call(this, node, parent);
});
// this._printTrailingComments(node);
// if (shouldPrintParens) this.token(")");
// end
this._printStack.pop();
this.format.concise = oldConcise;
this._insideAux = oldInAux;
}
}
例如,遍历到一个SwitchCase类型的ast节点,会在里面调用Printer对象的word/space/print/token等方法,而这些方法内部都会调用append方法用于逐个添加要生成的字符串,并计算得到对应的行列信息。
//packages/babel-generator/src/generators/statements.ts
export function SwitchCase(this: Printer, node: t.SwitchCase) {
if (node.test) {
this.word("case");
this.space();
this.print(node.test, node);//用于遍历,执行节点下的节点的方法
this.token(":");
} else {
this.word("default");
this.token(":");
}
if (node.consequent.length) {
this.newline();
this.printSequence(node.consequent, node, { indent: true });
}
}
Printer对象中声明了word/space/print/token等方法,这些方法都会将字符串添加到Buffer对象中。
//packages/babel-generator/src/printer.ts
class Printer {
constructor(format: Format, map: SourceMap) {
this._buf = new Buffer(map);
}
//...
_append(str: string, queue: boolean = false) {
if (queue) this._buf.queue(str);
else this._buf.append(str);
}
word(str: string): void {
// prevent concatenating words and creating // comment out of division and regex
if (
this._endsWithWord ||
(this.endsWith(charCodes.slash) && str.charCodeAt(0) === charCodes.slash)
) {
this._space();
}
this._maybeAddAuxComment();
this._append(str);
this._endsWithWord = true;
}
token(str: string): void {
// space is mandatory to avoid outputting <!--
// http://javascript.spec.whatwg.org/#comment-syntax
const lastChar = this.getLastChar();
const strFirst = str.charCodeAt(0);
if (
(str === "--" && lastChar === charCodes.exclamationMark) ||
// Need spaces for operators of the same kind to avoid: `a+++b`
(strFirst === charCodes.plusSign && lastChar === charCodes.plusSign) ||
(strFirst === charCodes.dash && lastChar === charCodes.dash) ||
// Needs spaces to avoid changing '34' to '34.', which would still be a valid number.
(strFirst === charCodes.dot && this._endsWithInteger)
) {
this._space();
}
this._maybeAddAuxComment();
this._append(str);
}
}
Buffer对象的append方法会去计算生成代码的行列信息,并将生成代码的行列信息和原始代码的行列信息传递给SourceMap对象,SourceMap对象将前后位置信息对应起来并进行编码从而生成最终的SourceMap。
//packages/babel-generator/src/buffer.ts
class Buffer {
constructor(map?: SourceMap | null) {
this._map = map;
}
//用于记录生成代码的位置
_position = {
line: 1,
column: 0,
};
//第1步:执行内部_append方法
append(str: string): void {
this._flush();
const { line, column, filename, identifierName } = this._sourcePosition;
this._append(str, line, column, identifierName, filename);
}
//第2步:计算传递进来的字符串参数对应的位置
_append(
str: string,
line: number | undefined,
column: number | undefined,
identifierName: string | undefined,
filename: string | undefined,
): void {
this._buf += str;
this._last = str.charCodeAt(str.length - 1);
let i = str.indexOf("\n");//查找换行符位置
let last = 0;
if (i !== 0) {
//排除开头是换行符的情况,其他情况执行标记
this._mark(line, column, identifierName, filename);
}
// Now, find each reamining newline char in the string.
while (i !== -1) {
//2-1.当存在换行符时,改变行数
this._position.line++;
this._position.column = 0;
last = i + 1;//换行符后一位
// We mark the start of each line, which happens directly after this newline char
// unless this is the last char.
if (last < str.length) {
this._mark(++line, 0, identifierName, filename);//改变行数,行数+1
}
i = str.indexOf("\n", last);//寻找下一个换行符
}
//2-2.改变列数,列数加上字符的长度
this._position.column += str.length - last;
}
//第3步:调用sourcemap对象的mark方法
_mark(
line: number | undefined,
column: number | undefined,
identifierName: string | undefined,
filename: string | undefined,
): void {
this._map?.mark(this._position, line, column, identifierName, filename);
}
}
export default class SourceMap {
//第4步:将前后行列信息对应起来后对位置信息进行编码
mark(
generated: { line: number; column: number },
line: number,
column: number,
identifierName?: string | null,
filename?: string | null,
) {
this._rawMappings = undefined;
maybeAddMapping(this._map, {
name: identifierName,
generated,
source:
line == null
? undefined
: filename?.replace(/\/g, "/") || this._sourceFileName,
original:
line == null
? undefined
: {
line: line,
column: column,
},
});
}
}
相关链接
Introduction to JavaScript Source Maps
Source Map Revision 3 Proposal
https://github.com/babel/babel
https://github.com/Rich-Harris/vlq
https://github.com/mozilla/source-map