优化器选择先对两个小表c,b进行关联,然后得到的结果集再与大表a进行关联,因为语句中c,b两个表没有字段进行直接关联,所以这两个表连接后的结果集是一个笛卡尔积25 *100=2500,因为大表的关联字段上没有索引,所以需要对最内层的大表全表扫描2500次。
背景
接到客户诉求说一条SQL长时间运行不出结果,让给看看怎么回事,SQL不复杂,优化措施也不复杂,但是要想SQL达到最优状态,也是需要经过一番考量并做出选择的。下面借实验还原一下此SQL优化过程。
实验:
数据库环境:MySQL5.7.39
测试表结构如下:
mysql> show create table t_1\G
*************************** 1. row ***************************
Table: t_1
Create Table: CREATE TABLE `t_1` (
`w_id` int(11) DEFAULT NULL,
`w_name` varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
mysql> show create table t_2\G
*************************** 1. row ***************************
Table: t_2
Create Table: CREATE TABLE `t_2` (
`i_id` int(11) NOT NULL,
`i_name` varchar(24) DEFAULT NULL,
`i_price` decimal(5,2) DEFAULT NULL,
`i_data` varchar(50) DEFAULT NULL,
`i_im_id` int(11) NOT NULL,
PRIMARY KEY (`i_im_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
mysql> show create table t_3\G
*************************** 1. row ***************************
Table: t_3
Create Table: CREATE TABLE `t_3` (
`s_w_id` int(11) NOT NULL,
`s_i_id` int(11) NOT NULL,
`s_quantity` int(11) DEFAULT NULL,
`s_ytd` int(11) DEFAULT NULL,
`s_order_cnt` int(11) DEFAULT NULL,
`s_remote_cnt` int(11) DEFAULT NULL,
`s_data` varchar(50) DEFAULT NULL,
`s_dist_01` char(24) DEFAULT NULL,
`s_dist_02` char(24) DEFAULT NULL,
`s_dist_03` char(24) DEFAULT NULL,
`s_dist_04` char(24) DEFAULT NULL,
`s_dist_05` char(24) DEFAULT NULL,
`s_dist_06` char(24) DEFAULT NULL,
`s_dist_07` char(24) DEFAULT NULL,
`s_dist_08` char(24) DEFAULT NULL,
`s_dist_09` char(24) DEFAULT NULL,
`s_dist_10` char(24) DEFAULT NULL,
`t_2_id` int(11) DEFAULT NULL,
`t_1_id` int(11) DEFAULT NULL,
PRIMARY KEY (`s_w_id`,`s_i_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
1 row in set (0.00 sec)
Create Table: CREATE TABLE `t_4` (
`w_name` varchar(10) DEFAULT NULL,
`s_i_id` int(11) NOT NULL,
`s_quantity` int(11) DEFAULT NULL,
`s_ytd` int(11) DEFAULT NULL,
`s_order_cnt` int(11) DEFAULT NULL,
`s_remote_cnt` int(11) DEFAULT NULL,
`s_data` varchar(50) DEFAULT NULL,
`t_2_id` int(11) DEFAULT NULL,
`i_name` varchar(24) DEFAULT NULL,
`i_price` decimal(5,2) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
其中t_1表25条记录,t_2表100条记录,t_3表500万条数据。我这里实验数据量少些,客户实际业务表数据量分别是(30,150,2700万)。t_4表为一个历史数据归档表,用于插入数据。
SQL文本展示如下:
insert into t_4
SELECT
c.w_name,
a.s_i_id,
a.s_quantity,
a.s_ytd,
a.s_order_cnt,
a.s_remote_cnt,
a.s_data,
a.t_2_id,
b.i_name,
b.i_price
FROM
t_3 a,
t_2 b,
t_1 c
WHERE
a.t_2_id = b.i_id
and a.t_1_id = c.w_id
and a.s_ytd = 0;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
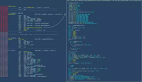
查看语句中select部分的执行计划如下图所示:
看到这个计划,就想对数据库说一句:"您辛苦了!"。
优化器选择先对两个小表c,b进行关联,然后得到的结果集再与大表a进行关联,因为语句中c,b两个表没有字段进行直接关联,所以这两个表连接后的结果集是一个笛卡尔积25 *100=2500,因为大表的关联字段上没有索引,所以需要对最内层的大表全表扫描2500次。
这是不是一个大工程呢?数据库任劳任怨,你让它干,它就干,只要你等得起就可以。事实上我们是没有耐心等的。我本来还想看看数据库到底用多久才能给出结果,等了10分钟,实在没有耐心继续等下去了。
这条SQL不复杂吧,就是三张表进行关联,但是关联字段上都没有索引,都进行了全表扫描。那么解决措施就是加索引,但是索引怎么加就需要做出选择了。
有同事就提出这个SQL在大表上全表扫描2500次,在大表的关联字段上加上索引就可以了,看到这里,你有没有认同这个见解呢?我想应该有很多小伙伴是认同的。
不错,给大表加上索引就不用全表扫描了,首先大表加索引,会锁表很长时间,这个索引在客户的生产环境须等到变更窗口才能加,客户等不及,其次你有考虑过这真的是最好的办法吗?
因为我这是实验环境,可以随时给大表加索引,那接下来我们就给大表加上索引试试效果。
mysql> alter table t_3 add key(t_1_id,t_2_id);
Query OK, 0 rows affected (28.35 sec)
Records: 0 Duplicates: 0 Warnings: 0
索引加好之后,执行计划如下:

可以看出优化器并没有选择走索引,依然是使用BNL优化策略,进行全表扫描,为什么不走索引呢?应该是优化器认为索引扫描的成本高于全表扫描的成本,因为这条语句最终结果要返回大表的90%以上的数据,走索引后回表代价是很高的。这一点我们是不认同优化器的,怎么着2500次全表扫描也比每次通过索引范围扫描的代价要高呀,好吧,既然不认同,那么使用force index来干涉优化器决策,让它使用索引。
执行计划如下图所示:

执行计划中显示索引用上了,那实际执行效果如何呢?
mysql> insert into t_4
-> SELECT
-> c.w_name,
-> a.s_i_id,
-> a.s_quantity,
-> a.s_ytd,
-> a.s_order_cnt,
-> a.s_remote_cnt,
-> a.s_data,
-> a.t_2_id,
-> b.i_name,
-> b.i_price
-> FROM
-> t_3 a force index(t_1_id),
-> t_2 b,
-> t_1 c
-> WHERE
-> a.t_2_id = b.i_id
-> and a.t_1_id = c.w_id
-> and a.s_ytd = 0;
Query OK, 4800000 rows affected (4 min 43.57 sec)
Records: 4800000 Duplicates: 0 Warnings: 0
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
确实效率不错,500万数据需要4 min 43.57 sec,生产环境的2700万数据大概需要半个小时左右。
但这是不是效率最高的办法呢,因为最终结果集会返回大表的90%以上的数据,所以需要对大量的索引数据回表,因为回表是会产生随机IO的,这个回表代价确实比较高,优化器默认也没有选择这种执行计划。如果我们给小表的关联字段上加索引会是什么效果呢?
接下来我给两个小表的关联字段上加了索引。
mysql> alter table t_2 add key(i_id);
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table t_1 add key(w_id);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
我们去掉大表的force index,不干涉优化器,让优化器自己做决策。执行计划如下:

上图的执行计划显示,优化器选择了对大表全表扫描,大表做驱动表,驱动两个小表。那这样的实际效果如何呢?
mysql> insert into t_4
-> SELECT
-> c.w_name,
-> a.s_i_id,
-> a.s_quantity,
-> a.s_ytd,
-> a.s_order_cnt,
-> a.s_remote_cnt,
-> a.s_data,
-> a.t_2_id,
-> b.i_name,
-> b.i_price
-> FROM
-> t_3 a,
-> t_2 b,
-> t_1 c
-> WHERE
-> a.t_2_id = b.i_id
-> and a.t_1_id = c.w_id
-> and a.s_ytd = 0;
Query OK, 4800000 rows affected (1 min 59.06 sec)
Records: 4800000 Duplicates: 0 Warnings: 0
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
这种方式耗时1min 59.06sec ,效率提高1倍多,生产环境的大数据量,效率提升应该更明显。果然采用大表驱动小表这种方式效率提高了,优化器的选择是对的。
选择这种方式的好处:
1.SQL的执行效率高一倍
2.节省空间,因为大表的索引会占用很大的磁盘空间。
3.响应及时,避免了必须等到变更窗口才能加索引的麻烦。
4.不用修改SQL语句
该如何选择是不是很清楚了呢?
到这里似乎优化就结束了,但是如果想要精益求精,追求极致的话,小表上的索引可以建成覆盖索引,防止小表回表取数据。
mysql> alter table t_1 drop key w_id;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table t_2 drop key i_id;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table t_2 add key(i_id,i_name,i_price);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table t_1 add key(w_id,w_name);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
执行效果如下:
mysql> insert into t_4
-> SELECT
-> c.w_name,
-> a.s_i_id,
-> a.s_quantity,
-> a.s_ytd,
-> a.s_order_cnt,
-> a.s_remote_cnt,
-> a.s_data,
-> a.t_2_id,
-> b.i_name,
-> b.i_price
-> FROM
-> t_3 a,
-> t_2 b,
-> t_1 c
-> WHERE
-> a.t_2_id = b.i_id
-> and a.t_1_id = c.w_id
-> and a.s_ytd = 0;
Query OK, 4800000 rows affected (1 min 38.99 sec)
Records: 4800000 Duplicates: 0 Warnings: 0
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
可以看出,小表上的索引建成覆盖索引,耗时又缩短了20秒,执行效率更高了。
至此该条SQL的优化结束。
总结
1.本条SQL的最终执行计划是大表驱动小表,这也算是给上篇文章《NL连接一定是小表驱动大表效率高吗》提供了一个案例。
2.优化措施可能有很多不同的选择,要根据实际情况选择最优的,不要草率做出决定。
3.精益求精是优化的极致,但是有时候也是需要做出折中选择的,达到业务运行的要求是目的,这点以后遇到案例再说。