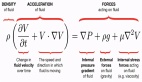
大家都已经使用机器学习了,尤其是基于神经网络的深度学习,chatGPT甚嚣尘上,还需要深入理解微分方程么?不论答案是啥,都会涉及到二者的对比,那么,机器学习与微分方程的区别又是什么呢?
从爱情模型的微分方程说起

这两个方程预测了夫妻恋爱关系的长久性,基于心理学家 John Gottman 的开创性工作,该模型预测持续的积极情绪是婚姻成功的有力因素。关于模型的更多解读,可以参考《幸福的婚姻》一书,作者还给出了维护婚姻幸福的7个法则:
- 完善你的爱情地图
- 培养你对配偶的喜爱和赞美
- 彼此靠近而不是远离
- 让配偶影响你的决定
- 以温和开场,用妥协收场
- 学会和问题和谐相处
- 创造共同意义
疫情三年,大家亲身经历,冷暖自知。那么,如何用微分方程描述患者与传染者的关系呢?

SIR 模型假设病毒是通过感染者和未感染者之间的直接接触传播的,患病者自动以某种固定的速率恢复。
这些微分方程都包含了一些未知函数的导数(即变化率),这些未知函数,例如 SIR 模型中的 S (t) ,I (t)和 R (t) ,称为该微分方程的解。基于这些方程的机制,我们可以得到模型的设计方式,而数据稍后将用于验证我们的假设。
数学模型的分类
类似微分方程这样的数学模型是预先对系统的基本机制进行假设,建模始于物理学,实际上,整个数学建模领域都始于17世纪对解开行星运动背后的基本动力学的探索。从那时起,基于数学的机制模型开启了许多现象的关键见解,从生物学和工程学到经济学以及社会科学。这样的机制模型可以分为基于方程的模型 ,如微分方程,或基于Agent的模型。

基于经验或数据驱动的建模,例如机器学习,是通过丰富的数据来了解系统的结构。机器学习对于复杂的系统特别有用,因为我们真的不知道如何从噪声中分离出信号,这时候,只要训练一个聪明的算法就可以帮助解决难题。
机器学习任务可大致分为以下几类:
- 监督式学习(例如,回归和分类) ;
- 非监督式学习(例如,聚类及降维) ;
- 强化学习

先进的机器学习和人工智能系统如今在我们的日常生活中无处不在,从基于智能音箱的会话助手(例如 小度)到 各种推荐引擎,再到人脸识别技术,甚至特斯拉(Tesla)的自动驾驶汽车。所有这些都是由嵌入在堆积如山的代码下的数学和统计建模驱动的。
进一步,可以将这些模型分为“确定性”(预测是固定的)或“随机性”(预测包括随机性)的。
确定性模型忽略随机变量,在相同的起始条件下总是预测相同的结果。一般的,机器学习和基于方程的模型都是确定性的,输出总是可预测的。换句话说,输出完全由输入决定。
随机模型通过在模型中引入概率来考虑总体的随机变化。捕捉这些变化的一种方法是让每个实体成为模型中一个单独的Agent,并为这些Agent定义允许的行为和机制,这些行为和机制具有一定的概率。这些是基于Agent的模型。
然而,对个体行为者进行建模的可实现性是有代价的,而基于代理的模型则更为现实。由于计算代价的高昂以模型的可解释性,这激发了数学建模中的一个关键概念: 模型复杂度。

模型复杂度
模型复杂度的困境是所有建模者都要面对的现实,我们的目标是构建并优化既不太简单也不太复杂的模型。简单的模型容易分析,但往往缺乏预测能力。复杂的模型可能是超现实的,但有可能试图了解复杂问题的背后真相。
我们需要在简单性和易于分析性之间进行权衡。复杂的机器学习模型在努力学习信号(即系统的真实结构)的同时排除噪音(即干扰)。这导致模型在新数据上表现不佳。换句话说,机器学习模型的普遍性较差。
平衡模型复杂度的微妙行为是一种“艺术”,试图寻找一个既不太简单也不太复杂的最佳位置。这个理想的模型可以冲刷掉噪音,捕捉到正在发生的事情的潜在动态,并且是可以合理解释的。
需要注意的是,这意味着一个好的数学模型并不总是正确的。不过没关系。可推广性是目标,可以向受众解释模型为什么这么做,无论他们是学者、工程师还是商业领袖。
所有的模型都是错误的,但有些是有用的。——乔治•博克斯(George Box),1976
在机器学习和统计学中,模型复杂度称为偏差-方差的折衷。高偏差模型过于简单,导致拟合不足,而高方差模型记忆噪声而不是信号,导致过度拟合。数据科学家努力通过精心选择训练算法和调整相关的超参数来达到这种微妙的平衡。
微分方程与机器学习的对比
在机制建模中,我们在对系统的潜在机制做出假设之前,会仔细地观察和审查一种现象,然后用数据验证模型。我们的假设正确吗?如果是这样,既然是亲自挑选的机制,完全可以向任何人解释是什么模型的这种行为。如果假设是错误的,那也没关系,只是浪费了一些时间,没什么大不了的。建模毕竟是反复试验。修补这些假设,甚至从头开始。机制模型,通常是微分方程等形式的方程,甚至是基于主体的模型。
在数据驱动建模中,我们是先让数据开始工作,为我们构建系统的全景。我们要做的就是满足那台机器的数据质量,希望有足够的数据。这便是机器学习。如果普通人很难搞清楚一个现象,可以调整一台机器来筛选噪音,为我们学习那难以捉摸的信号。标准的机器学习任务包括回归和分类,它们使用一系列度量标准进行评估。神经网络和强化学习也已经流行了起来,它们能够创建模型并学习令人惊叹的复杂信号。
尽管机器学习从20世纪50年代就已经存在,但随着计算机变得越来越强大,数据在爆炸式增长,使得人们如何利用人工智能获得竞争优势、提高洞察力和增长利润展开了广泛的实践。对于不同的应用场景,机器学习与微分方程都有着广泛的场景。