AI模型与人脑在数学机制上并没有什么区别。
只要模型够大、样本够多,AI就可以变得更智能!
chatGPT的出现,实际上已经证明了这点。
1,AI和人脑的底层细节都是基于if else语句
逻辑运算,是产生智能的基础运算。
编程语言的基本逻辑是if else,它会根据条件表达式把代码分成两个分支。
在这个基础上,程序员可以写出非常复杂的代码,实现各种各样的业务逻辑。
人脑的基本逻辑也是if else,if else这两个词就来自英语,对应的中文词汇是如果...否则...
人脑在思考问题时也是这么一个逻辑思路,这点上跟电脑没有区别。
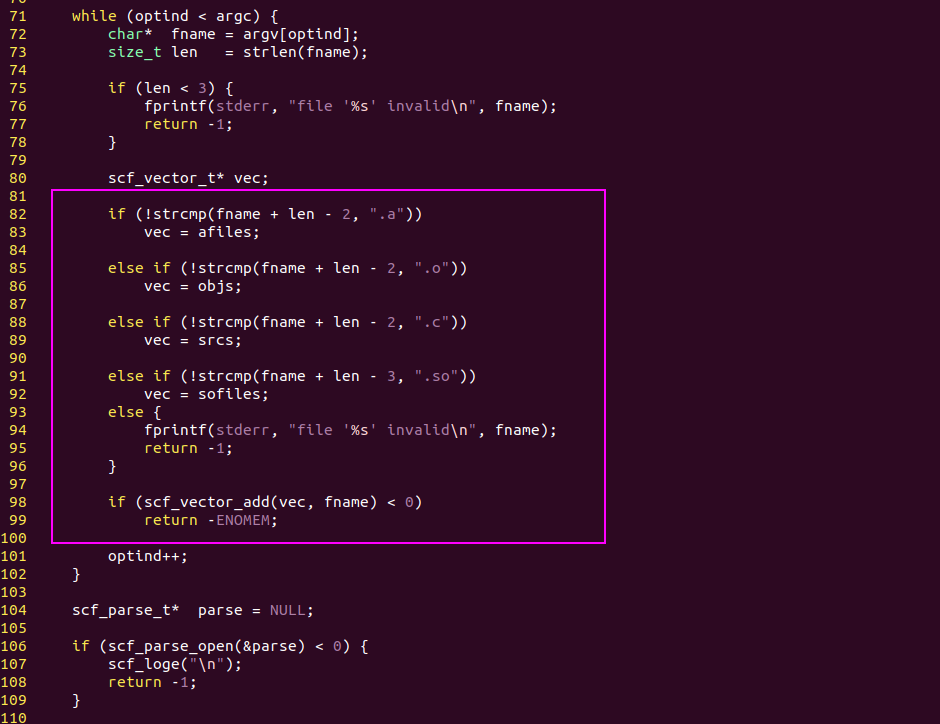
if else语句,逻辑的核心
AI模型的“if else语句”就是激活函数!
AI模型的一个运算节点,我们也可以叫它“神经元”。
它有一个输入向量X,一个权值矩阵W,一个偏置向量b,还有一个激活函数。
激活函数的作用实际就是if else语句,而WX + b这个线性运算就是条件表达式。
在激活之后,AI模型的代码相当于运行在 if分支,而不激活时相当于运行在else分支。
多层神经网络的不同激活状态,实际上也是对样本信息的二进制编码。
深度学习也是对样本信息的二进制编码
AI模型对样本信息的编码是动态的、并行的,而不是和CPU代码一样是静态的、串行的,但它们的底层基础都是if else。
在电路层面要实现if else并不难,一个三极管就可以实现。
2,人脑比电脑聪明,是因为人类获得的信息更多
人脑每时每刻都在获取外界的信息,每时每刻都在更新自己的“样本数据库”,但程序代码没法自我更新,这是很多人能做到的事而电脑做不到的原因。
人脑的代码是活的,电脑的代码是死的。
“死代码”当然不可能比“活代码”更聪明,因为“活代码”可以主动查找“死代码”的BUG。
而根据实数的连续性,只要“死代码”编码的信息是可数的,那么它就总存在编码不到的BUG点。
这在数学上可以用康托三分集来佐证。
不管我们用多少位的三进制小数去编码[0, 1]区间上的实数,总有至少1个点是没法编码进去的。
所以当两个人抬杠的时候,总是能找到可抬杠的点
但是电脑的代码一旦写好就没法主动更新了,所以程序员可以想出各种办法去欺骗CPU。
例如,intel的CPU本来要求在进程切换时要切换任务门的,但Linux就想出了一个办法只切换页目录和RSP寄存器
在intel CPU看来,Linux系统一直在运行同一个进程,但实际上不是。这就是所谓的进程软切换。
所以,只要CPU的电路固定了,那么CPU编码的信息也就固定了。
CPU编码的信息固定了,那么它编码不到的信息就是无限的,就是可以被程序员利用的。
而程序员之所以可以利用这种信息,是因为程序员的大脑是活的,可以动态的更新样本。
3,神经网络的出现改变了这种情况
神经网络真是一个伟大的发明,它在固定的电路上实现了动态的信息更新。
所有写好的程序能处理的信息都是固定的,包括CPU电路,也包括各种系统的代码。
但神经网络不是这样,它的代码虽然是写好的,但它只需要更新权值数据,就可以改变模型的逻辑脉络。
实际上只要不断地输入新样本,AI模型就可以不断地用BP算法(梯度下降算法)更新权值数据,从而适应新的业务场景。
AI模型的更新不需要修改代码,而只需要修改数据,所以同样的CNN模型用不同的样本训练,它就可以识别不同的物体。
在这个过程中,不管是tensorflow框架的代码,还是AI模型的网络结构都是不变的,变的是每个节点的权值数据。
理论上来说,只要AI模型可以通过网络抓取数据,它就可以变得更智能。
这跟人们通过浏览器看东西(从而变得更聪明),有本质的区别吗?好像也没有。
4,只要模型够大、样本够多,或许ChatGPT真可以挑战人脑
人脑有150亿个神经元,而且人的眼睛和耳朵每时每刻都在给它提供新的数据,AI模型当然也可以做到这点。
或许比起AI来,人类的优势在于“产业链”更短
一个婴儿的出生只需要Ta父母,但一个AI模型的诞生显然不是一两个程序员可以做到的。
仅仅是GPU的制造就不止几万人。
GPU上的CUDA程序并不难写,但GPU制造的产业链太长了,远不如人类的出生和成长。
这或许是AI相对于人的真正劣势。