1背景
在日常Flink使用过程中,我们经常遇到Flink任务中某些Slot或者TM负载过重的问题,对日常的资源调配、运维以及降本都带来了很大的影响,所以我们对Flink的task部署机制进行了梳理和调研,准备在后续的工作中进行优化。由于jobGraph的生成以及任务提交流程因任务部署方式而不同,对我们后续的分析也没有影响,这里忽略前置流程,直接从Dispatcher出发,重点关注submit后executionGraph构建以及后续的任务部署过程。
2Flink Scheduling Components 构成
2.1 SchedulerNG
在Dispatcher收到submit请求后,先是启动了JobManagerRunner,再启动JobMaster,在初始化jobMaster的过程中,我们注意到这里开始了整个作业的Scheduling第一步,创建SchedulerNG。
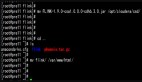
我们看下SchedulerNG的职责,可以看到调度的发起,作业状态的跟踪以及我们熟悉的cp,sp的trigger都是在这里:

我们这次主要跟踪构建executionGraph,然后根据Scheduling策略发起的整个部署过程。
2.2 ExecutionGraph
现阶段(1.13)SchedulerNG默认实现是DefaultScheduler,初始化过程中就会开始构建我们的ExecutionGraph,ExecutionGraph中有几个重要元素
- ExecutionJobVertex: 代表jobGraph中的一个JobVertex,是所有并行Task的集合
- ExecutionVertex: 代表ExecutionJobVertex中并行task中的一个,一个ExecutionJobVertex可能同时有很多并行运行的ExecutionVertex
- Execution: 代表ExecutionVertex的一次部署/执行,一个ExecutionVertex可能会有很多次Execution
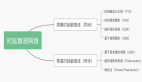
这里executionGraph通过jobGraph的拓扑图构建了自己的核心结构,看下从JobVertex到ExecutionJobVertex 的转换流程:
2.3 执行层拓扑结构
我们知道Flink引擎在不停的致力于批流一体建设,调度层的统一也是其中核心的一层。为了提高failover后recovery速度,减少对Flink任务的影响,现在Flink对于批、流的任务task调度都是以pipeline region为基础。
Pipeline region的构建内嵌在executionGraph的初始化过程中,我们知道Flink中各个节点之间的链接都会有IntermediateDataSet这一种逻辑结构,用来表示JobVertex的输出,即该JobVertex中包含的算子会产生的数据集。这个数据集的ResultPartitionType有几种类型:
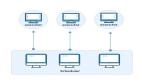
接下来我们看看executionGraph的核心拓扑结构ExecutionTopology是如何构建的:
2.4 Scheduling 策略
SchedulerNG Scheduling策略默认为PipelinedRegionSchedulingStrategy,在executionGraph完成之后,就可以根据生成的刚刚executionTopology来初步构建初步的Scheduling策略了。这里看下startScheduling代码,可以看到Scheduling过程就是我们常说的基于pipeline region的Scheduling。
2.5 Execution Slot 分配器
默认实现是SlotSharingExecutionSlotAllocator,在schedulerNG完成executionGraph构建完成后,需要进一步构建Execution Slot 分配器。用于将physical shared slots分配到我们的logical slots 上,并将logical slot 分配给我们executionGraph中的execution(task)。通过代码我们可以看到ExecutionSlotAllocator的职责非常简单,只有简单的allocate和cancel。

但在实现上这里有几个重要元素需要了解:
LocalInputPreferredSlotSharingStrategy :在Flink内部,所有的slot分配都是基于sharingslot来操作的,在满足co-location的基础上,Flink期望将producer和consumeNode task尽可能的分布在一起,以减少数据传输成本。
SlotProfile:slot的资源信息,对task -> logical slot -> physical slot的mapping有非常重要的作用,包含了task的资源信息,slot的物理资源信息,倾向的location(TaskManagerLocation),倾向的allocation以及整个executionGraph之前分配过的allocation(用于黑名单,重启后尽量避免分配在之前的slot里)。
ResourceProfileRetriever: 用于获取executionVertex的实际资源信息。默认是unknown,如果有明细配置会用于后续的executionSlotSharingGroup资源构建。
ExecutionSlotSharingGroup:Flink task资源申请的最终逻辑载体,用于将sharing到一起的task(execution group)组合成一个group用于生成资源,后续部署也会绑定对应的task。
3Scheduling 主要过程
在JobMaster完成自身构建之后,就委托SchedulerNG来开始了整个job的Scheduling:
可以看到这里是由schedulingStrategy来负责整个调度过程的,也就是我们的PipelinedRegionSchedulingStrategy,
one by one将pipeline region进行部署
遍历region中的ExecutionVertex依次进行部署
将vertexDeployment交给SlotSharingExecutionSlotAllocator处理
通过SlotSharingStrategy拿到每个execution对应的ExecutionSlotSharingGroup
- 先从 corresponding co-location constraint 去mapping中寻找是否有存在的slot sharing group
- 接着从producer 的角度来逐一检查是否可以合并到同一个slot sharing group.
- 最后尝试所有剩下的slot sharing group看是否符合execution 的要求(如同属于一个job vertex的task不能分配到同一个 slot sharing group).
- 如果以上都没有满足条件的就创建一个新的slot sharing group
- 检查ExecutionSlotSharingGroup是否已经有了对应的sharedSlot
- 遍历尚未得到分配的ExecutionSlotSharingGroup
- 计算对应的SlotProfile
- 向PhysicalSlotProvider申请新的physical slot
rm侧会先检查是否已经有满足条件的excess slot
如果没有尝试会申请新的woker以提供资源
由sharedSlotProfileRetriever来创建对应的slotProfile并构建PhysicalSlotRequest
PhysicalSlotProvider向slotPool申请新的slot
slotPool会向rm侧申请新的slot
利用physical slot future提前创建sharedSlotFutrue
将sharedSlotFutrue 分配给所有相关的executions
最后生成所有的SlotExecutionVertexAssignments
在完成所有的SlotExecutionVertexAssignment之后,生成对应的DeploymentHandle并等待所有的assignedSlot创建完毕,正式开始部署对应的任务。
4问题思考
我们对整个Flink task的部署过程完成梳理后,重新对我们一开始的问题进行思考:
4.1 为什么会出现slot负载过重的情况?如何避免?
问题的产生在于大量的task集中分配到了统一个sharedSlot,这个我们可以发现其实是在ExecutionSlotSharingGroup的构建过程中产生的。我们看下源码,可以很直接的看到整个group的分配是一个roundRobin过程,而executionVertices来自于有序拓扑结构,中间传递过程也保证了有序性,所以最终会导致大量的task分配的index靠前的group中,最后落到了同一个slot。
为了避免这种情况,我们的做法其实有比较多,一种是在保证各种constraint的同时添加随机性,以打散各个不均匀的task;还有一种就是构建基于load-balance的分配过程,以尽可能的将task分布均匀。
附Flink部分源码:
这个问题主要是在于说有一些过重的task对应的slot都分配在了同一个tm上,导致整个tm压力过大,资源难以协调。在整个过程中其实我们有看到tm信息的交互,在co-location constraint上。我们看下该hint职责:
The co-location group is used to make sure that the i-th subtasks for iteration head and iteration tail are scheduled on the same TaskManager.
也就是说其实是为了解决算子间相同index的task数据传递之类的问题,但对于task的均衡负载无法介入。对此我们尝试去做的事情:
在当前不使用细粒度资源配置的情况下,考虑task-slot之间均衡分布的同事,task-tm也能做到一定的负载均衡。这种情况可以通过tm单slot来解决,也可以在保证task-slotSharingGroup足够随机性的同时,保证slotSharingGroup-tm的足够随机性。
在后续使用使用细粒度资源配置的情况下,不使用slotsharing,且将相同jobVertex对应的task尽量分布在同一个task当中。这个我们后续准备在slotProfile中加入jobVertex相关的tag,SlotAllocator做slot matching的时候加入jobVertex constraint来保证task的位置分配。
5写在最后
Flink开源社区较活跃,Task侧的部署链路也一直在演进中,持续跟进并深入了解内部实现逻辑能更好的支持我们解决Flink个性化调度策略上的一些问题。后续我们也准备进一步完善Flink在operator级别的细粒度资源配置能力,降低资源使用率的同时进一步提高Flink作业稳定性。