在遇到跨库或者异库数据同步时,我们一般都会借助ETL工具来实现数据同步功能。比如目前大家较为熟知的Kettle和Datax。但是,这两个需要定时去查询数据库的数据,会存在一定的延迟,而且,默认采用全量同步的方式,想要增量,需要自己做特殊的处理。那么,有没有开源的工具,既能满足全量和增量,又能达到相对比较实时的呢?接下来,我们继续往下看。
Kettle
在ETL行列中,kettle算是人气比较旺的一款工具,功能多且强大,开源,可视化。使用方便、简洁,但是,体量越来越大,性能一般。
可以自己下载源码编译,要求Maven 3+、Java JDK 11。
https://github.com/pentaho/pentaho-kettle.git
DataX
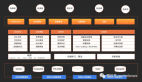
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
Oracle | √ | √ | 读 、写 | |
OceanBase | √ | √ | 读 、写 | |
SQLServer | √ | √ | 读 、写 | |
PostgreSQL | √ | √ | 读 、写 | |
DRDS | √ | √ | 读 、写 | |
Kingbase | √ | √ | 读 、写 | |
通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
ADB | √ | 写 | ||
ADS | √ | 写 | ||
OSS | √ | √ | 读 、写 | |
OCS | √ | 写 | ||
Hologres | √ | 写 | ||
AnalyticDB For PostgreSQL | √ | 写 | ||
阿里云中间件 | datahub | √ | √ | 读 、写 |
SLS | √ | √ | 读 、写 | |
阿里云图数据库 | GDB | √ | √ | 读 、写 |
NoSQL数据存储 | OTS | √ | √ | 读 、写 |
Hbase0.94 | √ | √ | 读 、写 | |
Hbase1.1 | √ | √ | 读 、写 | |
Phoenix4.x | √ | √ | 读 、写 | |
Phoenix5.x | √ | √ | 读 、写 | |
MongoDB | √ | √ | 读 、写 | |
Cassandra | √ | √ | 读 、写 | |
数仓数据存储 | StarRocks | √ | √ | 读 、写 |
ApacheDoris | √ | 写 | ||
ClickHouse | √ | 写 | ||
Databend | √ | 写 | ||
Hive | √ | √ | 读 、写 | |
kudu | √ | 写 | ||
无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
FTP | √ | √ | 读 、写 | |
HDFS | √ | √ | 读 、写 | |
Elasticsearch | √ | 写 | ||
时间序列数据库 | OpenTSDB | √ | 读 | |
TSDB | √ | √ | 读 、写 | |
TDengine | √ | √ | 读 、写 |
https://github.com/alibaba/DataX.git
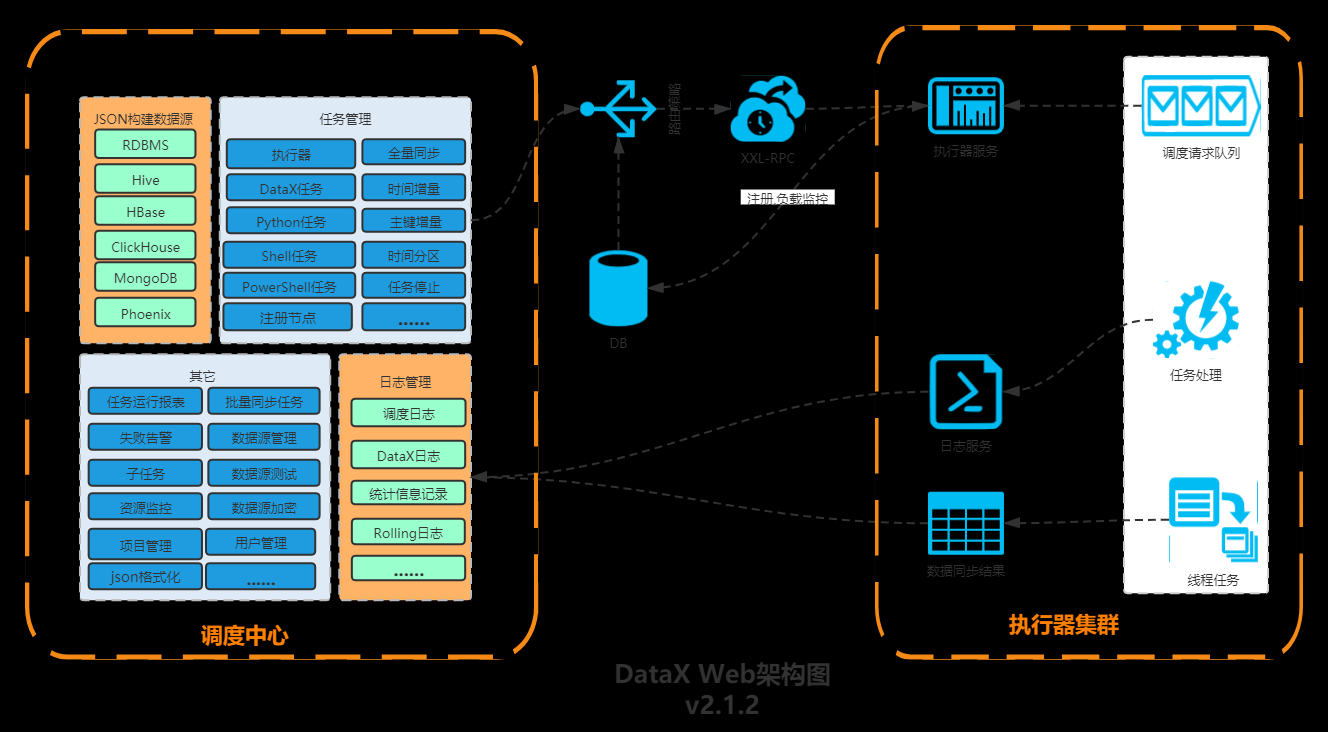
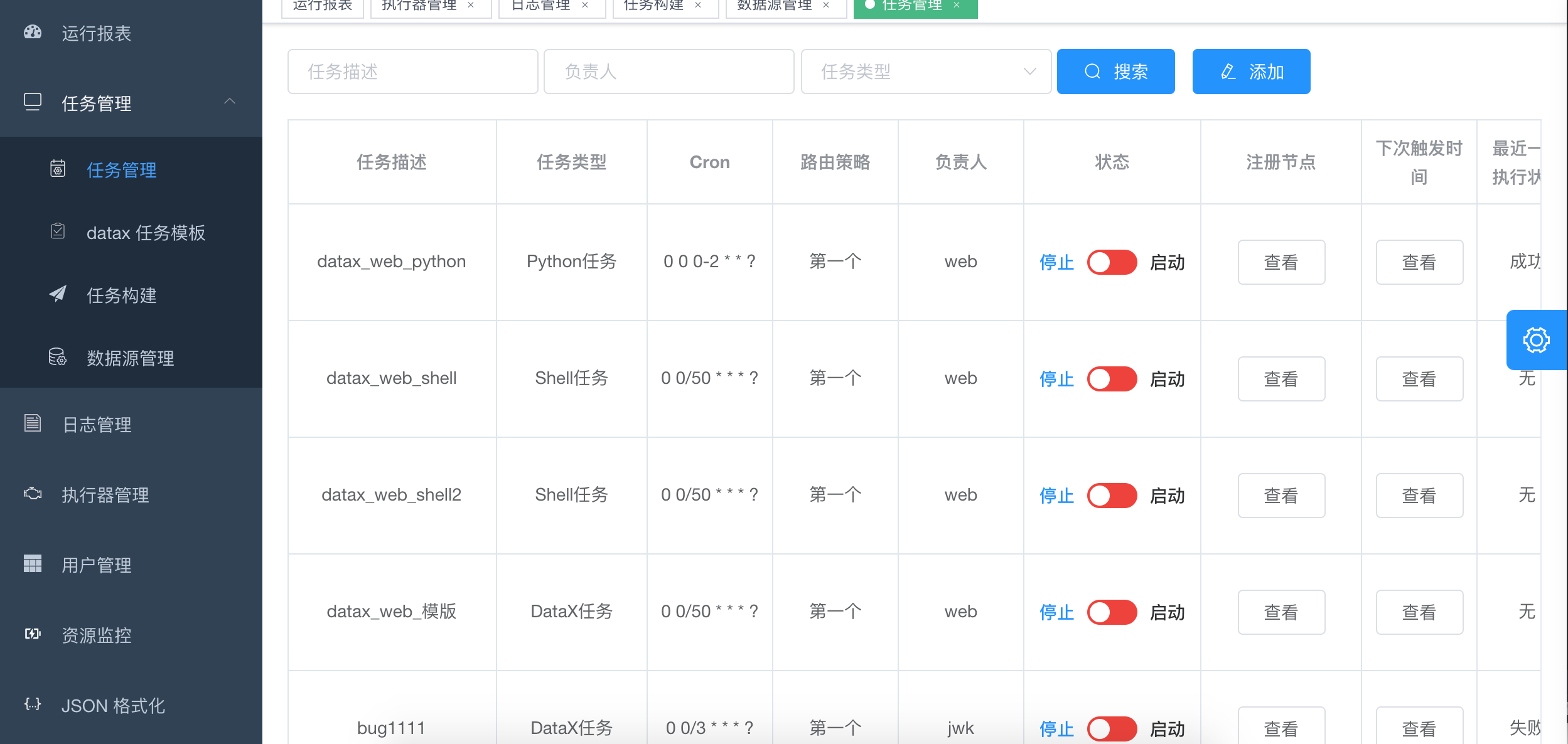
DataX-Web
前面提到DataX,那么就不得不提一下DataX-Web,DataX没有可视化界面,不过目前,已经有热心开基于DataX开发了对应的Web界面。DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的 操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可通过页面选择数据源即可创建数据同步任务,支持RDBMS、Hive、HBase、ClickHouse、MongoDB等数据源,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发xxl-job可根据时间、自增主键增量同步数据。
任务”执行器”支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU.内存.负载的监控等等。后续还将提供更多的数据源支持、数据转换UDF、表结构同步、数据同步血缘等更为复杂的业务场景。
https://github.com/WeiYe-Jing/datax-web.git
Airbyte
一款开源的可视化ETL功能,支持很多数据源,并且支持全量及增量同步。
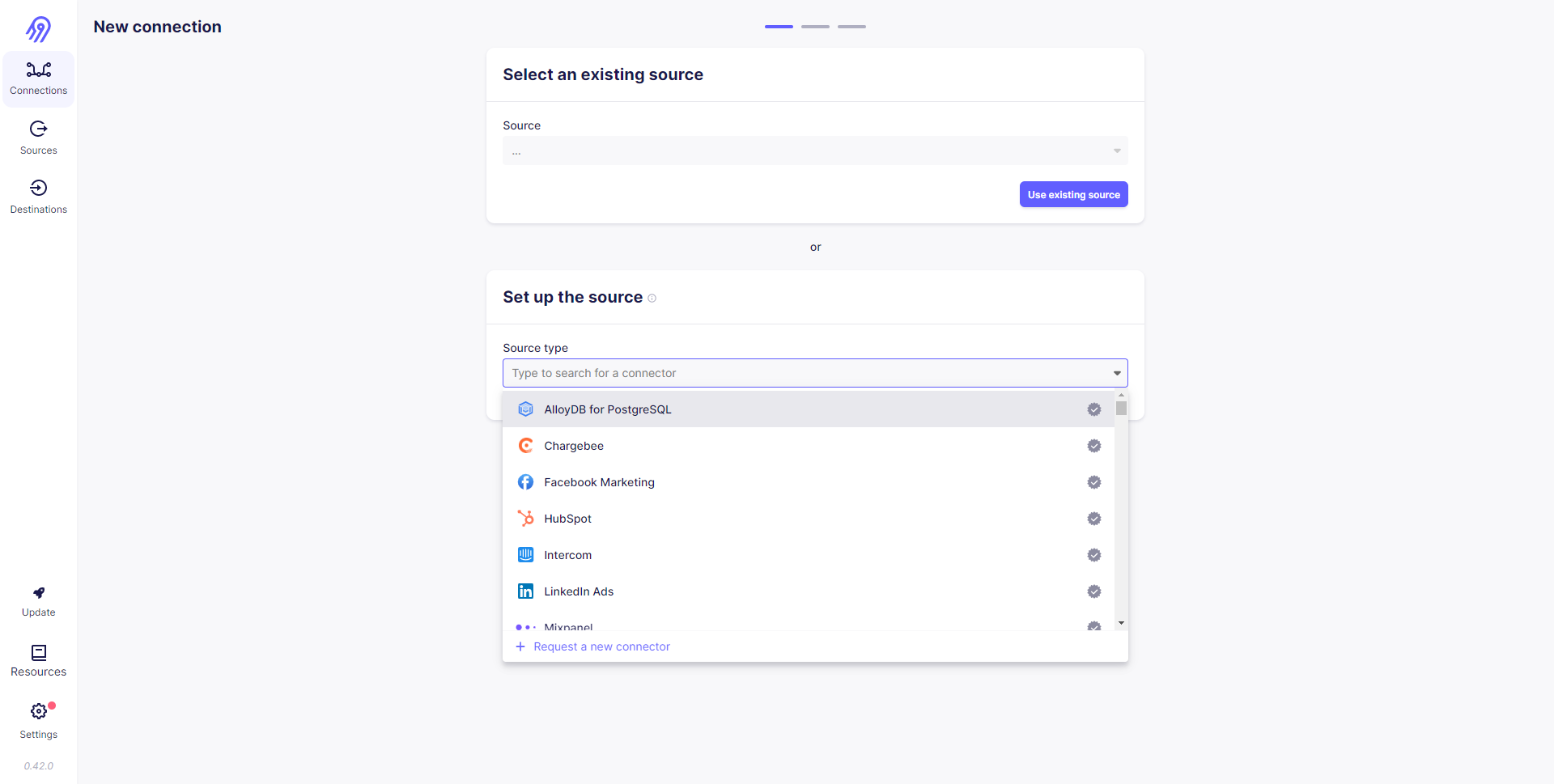
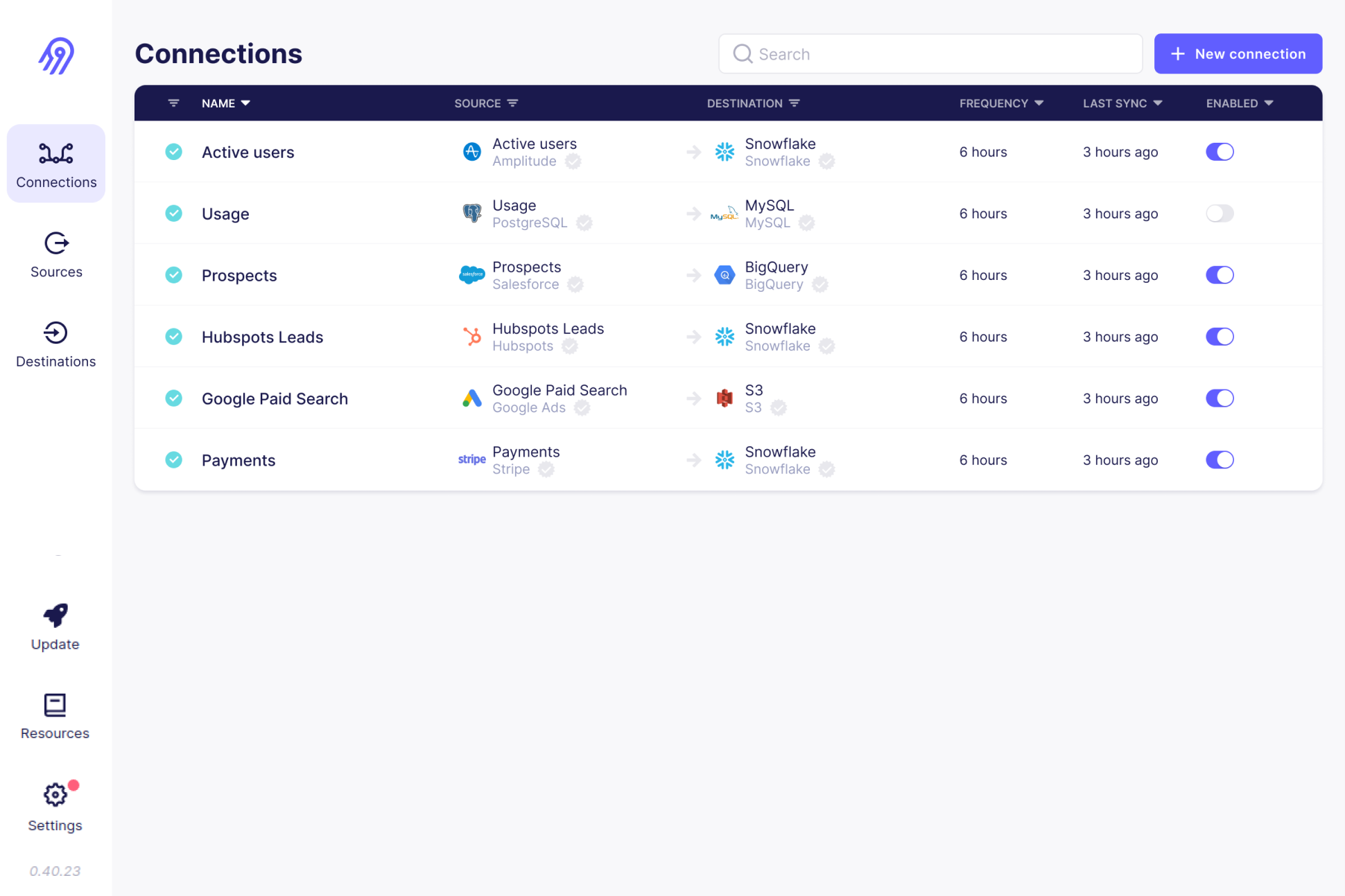
https://github.com/airbytehq/airbyte.git
benthos
Benthos 是一个开源的、高性能和弹性的数据流处理器,支持多种方式的数据接入、加工、转换。
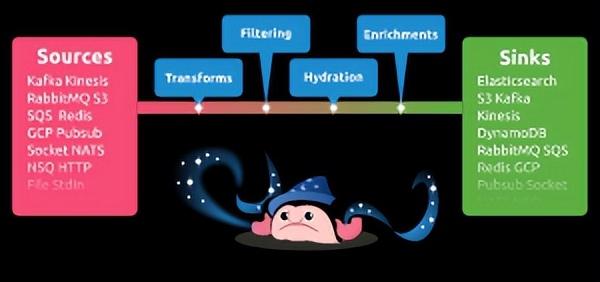
https://github.com/benthosdev/benthos.git
canal
阿里巴巴开源的MySQL binlog 增量订阅&消费组件,基于日志只能做增量同步,很多工作需要自己处理。
https://github.com/alibaba/canal.git
Maxwell
也是监听MySQL binlog,并将数据更解析为JSON写入到Kafka等其他流媒体平台。
https://github.com/zendesk/maxwell.git
debezium
Debezium是一个捕获数据更改(CDC)平台,并且利用Kafka和Kafka Connect实现了自己的持久性、可靠性和容错性。每一个部署在Kafka Connect分布式的、可扩展的、容错性的服务中的connector监控一个上游数据库服务器,捕获所有的数据库更改,然后记录到一个或者多个Kafka topic(通常一个数据库表对应一个kafka topic)。Kafka确保所有这些数据更改事件都能够多副本并且总体上有序(Kafka只能保证一个topic的单个分区内有序),这样,更多的客户端可以独立消费同样的数据更改事件而对上游数据库系统造成的影响降到很小(如果N个应用都直接去监控数据库更改,对数据库的压力为N,而用debezium汇报数据库更改事件到kafka,所有的应用都去消费kafka中的消息,可以把对数据库的压力降到1)。另外,客户端可以随时停止消费,然后重启,从上次停止消费的地方接着消费。每个客户端可以自行决定他们是否需要exactly-once或者at-least-once消息交付语义保证,并且所有的数据库或者表的更改事件是按照上游数据库发生的顺序被交付的。
https://github.com/debezium/debezium.git
Flink CDC
Apache Flink®的CDC连接器集成了Debezium作为捕获数据更改的引擎。虽然功能强大,但是比较重。
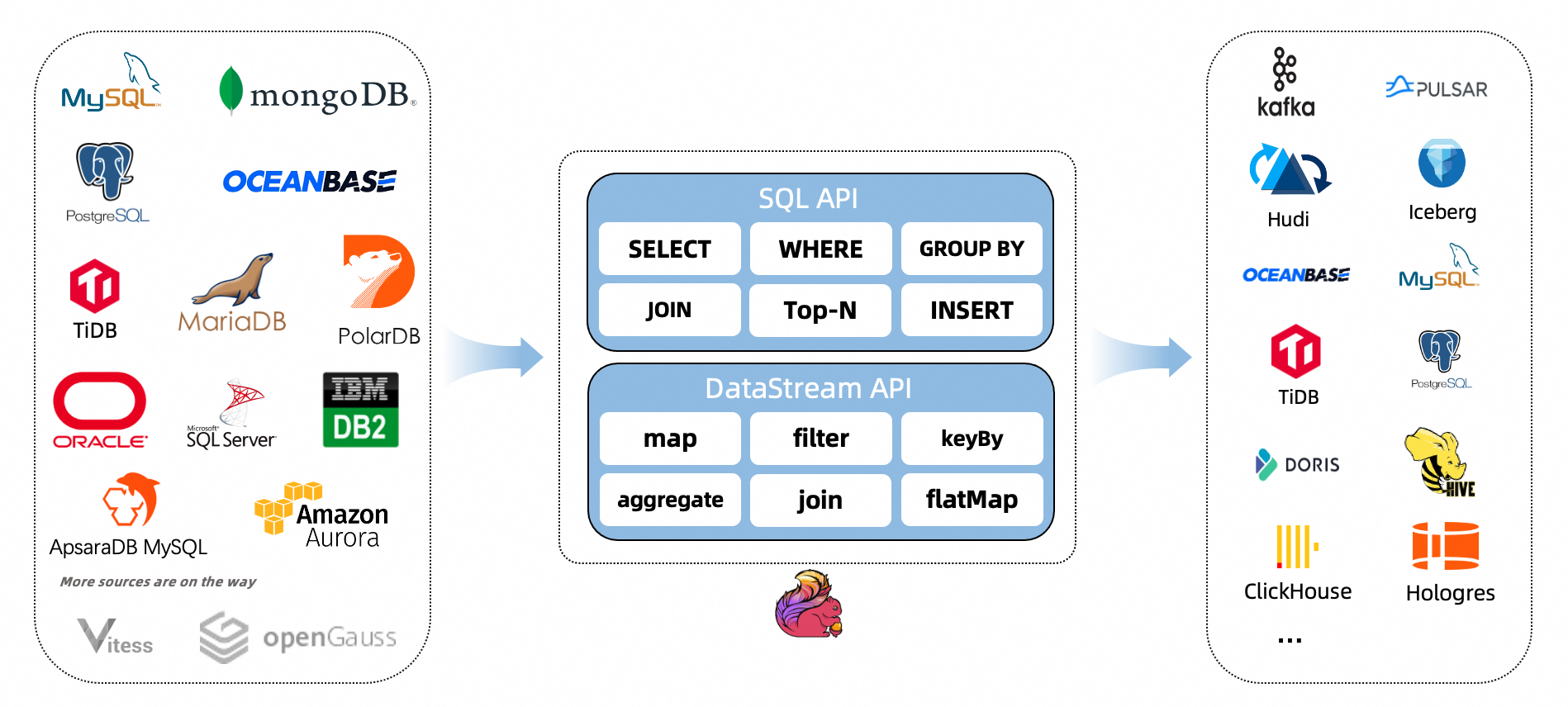
https://github.com/ververica/flink-cdc-connectors.git
目前,异构数据ETL同步,一般基于两种方式:查询和日志,基于查询做全量同步,基于日志做增量同步,日志方式延迟会比较小,查询来做增量,延迟会比较大,查询频率越高,对数据库性能也会有影响。随着各种热门技术的兴起,在Github中也有越来越多的解决方案,我们可以根据自己的实际情况选择合适自己的工具。