为了更好地了解智能机器人项目的需求和改进方向,我们常常需要研发一些工具。在我参与的多个机器人项目中,大多数都能够成功地满足产品需求。通过这些实践,我们深刻认识到,如果要不断进步和提高,就必须对现有的机器人定义语言进行重大的改进。
- 简化需要复杂对话流程的机器人的创建过程。
- 最大限度地提高可重用性,通过重用过去已经定义过的模块和对话路径来创建机器人
在传统的做法中,完成这些并不容易,因为意图定义与部分排序约束混合在一起,限制了对话路径的自由度。这对于处理“开放式”机器人(常见于FAQ样式的机器人),其中大多数问题是独立的且始终可用的,这已经足够了。但对于更“封闭”的机器人来说,潜在的对话限制要多得多(比如用于从在线订票机器人)。
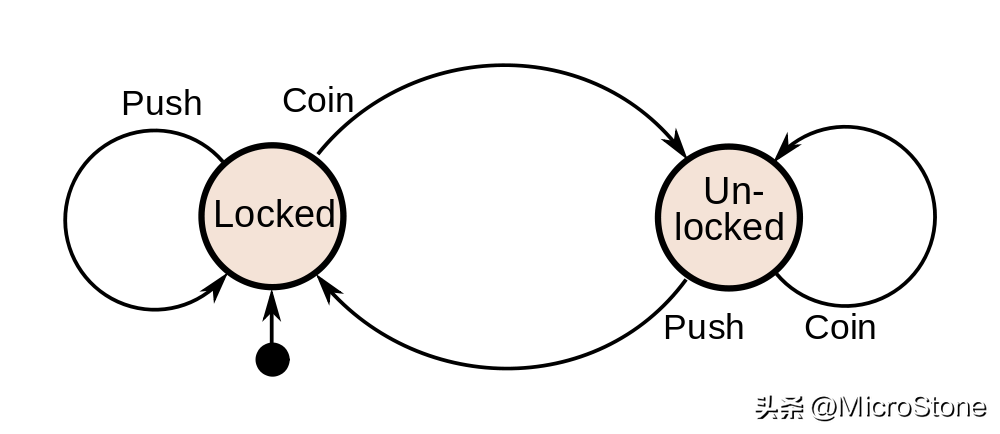
为了将聊天机器人定义语言的功能提升到一个新的水平,在一些项目中我们引进了更接近状态机语义的DSL,并完全将意图定义与控制机器人执行定点可用意图的转换规则分离,这么做有以下优势:
- 新机器人中可以复用以前的意图,即使设置的对话路径不同。
- 可以使用状态机定义复杂的对话流,让机器人保持清晰和精确的语义。
- 可以创建复杂的状态守护来控制转换。根据用户输入、即将发生的事件以及之前的数据、对话参数等,将机器人移动到新状态。
- 可以使用状态主体来存储复杂的对话逻辑,以响应用户请求。
- 可以将机器人模块化,以便在其他机器人中重用部分状态机。
- 可以将本地回退定义为状态行为的一部分。除了默认的全局回退,还可以将本地回退与状态相关联,以便在状态上下文中处理错误,比如显示一条消息,帮助用户回答机器人在对话中的特定状态下提出的问题。
意图定义语言
意图定义现在与执行部分解耦,但仍然是一个单独的子语言。对于每个意图,我们只需提供一些训练句子,让机器人能够识别出用户话语的意图,并从中提取所需的参数。
举个例子,我们有一个简单的机器人,它只能理解两种类型的用户话语:问候和陈述姓名。我们可以为每种话语类型提供几个示例句子,让机器人学会如何识别它们。当用户输入一个话语时,机器人会根据它的意图执行相应的操作,并从中提取所需的参数。
我们为每种意图提供一些样本句子,来训练机器人如何识别它们。此外,在某些情况下,我们还会在上下文中收集一些参数(例如,用户的姓名),以便以后能够更个性化地回答用户。
我们还没有具体说明机器人应该先尝试匹配哪种意图,这是执行部分语言的内容。这种方法使我们能够重复利用这些意图(例如,在另一个机器人中,我们可能需要询问用户的姓名,而不仅仅是在问候意图之后)。
执行定义语言
使用执行文件来定义一个状态机,描述机器人如何响应意图/事件,并且可以进行转换。这使得机器人的设计者可以查看执行文件,了解整个对话流程。
执行语言中的每个状态包含 3 个部分
- Body (可选):机器人在进入状态时执行的反应。
- Next (必选):定义了出站转换,表示为 condition –> State。 当接收到事件/意图时,会评估条件,如果满足转换,则执行引擎会移动到指定的状态并执行其相应的反应。需要注意的是,转换条件可以非常复杂。 它们是真正的守卫,这意味着如果整个条件不为真,则转换不可导航,引擎将保持当前状态。
- Fallback (可选):此部分可以包含任意代码(就像 Body 部分一样),如果引擎无法找到可导航的转换,则会执行这些代码。
执行模型还包含 2 个特殊状态:
- Init:是创建用户会话时进入的常规状态。它可以包含 Body、_Next_和 Fallback 部分。
- Default_Fallback:它只能包含 Body 部分,并且不能作为转换的目标状态。该状态表示在当前状态中未定义本地回退时执行的默认回退代码。该状态可用于打印通用错误消息(例如,“抱歉,我没明白您的意思”),而本地回退则可以打印针对当前状态的定制消息(例如,“请回答是或否”)。
最后,一个状态可以定义一个单一的通配符转换(使用保留字符___作为转换条件),当计算状态主体时将自动导航。这使我们能够在多个地方重用相同的代码并模块化执行逻辑。下面是一个简单的机器人示例,它只回复问候意图,询问用户名并向用户问好。这个机器人的回复可以通过我们基于 React 的聊天小部件显示。