译者 | 朱先忠
审校 | 孙淑娟
在我之前的博客中,我们已经了解了如何使用因果树来评估政策的异质处理效应。如果你还没有阅读过,我建议你在阅读本文前先读一遍,因为我们在本文中认为你已经了解了此文中的部分与本文相关的内容。
为什么是异质处理效应(HTE:heterogenous treatment effects)呢?首先,对异质处理效应的估计允许我们根据它们的预期结果(疾病、公司收入、客户满意度等)选择提供处理(药物、广告、产品等)的用户(患者、用户、客户等)。换句话说,估计HTE有助于我们进行目标定位。事实上,正如我们将在文章后面所看到的那样,一种处理方法在给一部分用户带来积极益处的同时,平均来说可能无效甚至适得其反。相反的情况也可能是这样的:一种药物平均来说是有效的,但是如果我们明确它对其有副作用的使用者信息的话,此药物的有效性就会进一步提高。
在本文中,我们将探讨因果树的一个扩展——因果森林。正如随机森林通过将多个自助树平均在一起来扩展回归树一样,因果森林也扩展了因果树。主要的区别来自于推理的角度,它不那么直接。我们还将了解如何比较不同HTE估计算法的输出,以及如何将其用于政策目标。
在线折扣案例
在本文的其余部分,我们继续使用我上一篇有关因果树文章中使用的玩具示例:我们假设我们是一家在线商店,我们有兴趣了解向新客户提供折扣是否会增加他们在商店中的支出。
为了了解折扣是否划算,我们进行了以下随机实验或A/B测试:每次新客户浏览我们的在线商店时,我们都会将其随机分配给一个处理条件。我们为受处理的用户提供折扣;而为控制用户,我们不提供折扣。我从文件src.dgp导入数据生成过程dgp_online_discounts()。我还从src.utils库导入一些绘图函数和库。为了不仅包括代码,还包括数据和表等内容,我使用了Deepnote框架,这是一个类似Jupyter的基于Web的协作笔记本环境。
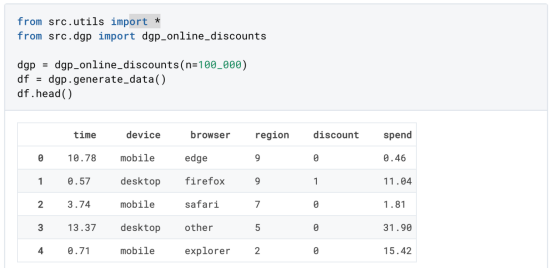
我们有100000名在线cstore访问者的数据,我们观察他们访问网站的时间、使用的设备、浏览器和地理区域。我们还会观察到他们是否得到了折扣,我们的处理方式,他们的花费是多少,以及其他一些感兴趣的结果。
由于实验是随机分配的,我们可以使用简单的均值差估计来估计实验效果。我们期望实验组和对照组相似,但折扣除外,因此我们可以将支出的任何差异归因于折扣。
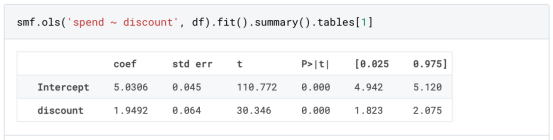
折扣看起来似乎是有效的:实验组的平均花费增加了1.95美元。但是所有的顾客都受到同样的影响吗?
为了回答这个问题,我们想估计异质处理效应,可能是在个体层面。
因果森林
计算异质处理效应有许多不同的选择。最简单的方法是以异质性的维度与感兴趣的结果进行交互。这种方法的问题在于选择哪个变量。有时,我们拥有可能指导我们行动事先的信息;例如,我们可能知道移动用户的平均花费比桌面用户多。其他时候,出于商业原因,我们可能对某个维度感兴趣;例如,我们可能希望在某个地区投资更多。然而,当我们没有额外的信息时,我们希望这个过程是数据驱动的。
在上一篇文章中,我们探索了一种数据驱动的方法来估计异质处理效应——因果树。我们现在将把它们扩展到因果森林。然而,在我们开始之前,我们必须介绍一下它的非因果表亲——随机森林。

随机森林,顾名思义,是回归树的延伸,在其上增加了两个独立的随机性来源。特别是,随机森林算法能够对许多不同的回归树进行预测,每个树都在数据的自助样本上进行训练,并将它们平均在一起。该过程通常称为引导聚集算法,又称装袋算法,可以应用于任何预测算法,而不是随机森林特有的。随机性的额外来源来自特征选择,因为在每次分割时,只有所有特征X的随机子集被考虑用于最优分割。
这两个额外的随机性来源非常重要,有助于提高随机森林的性能。首先,装袋算法允许随机森林通过对多个离散预测进行平均来产生比回归树更平滑的预测。相反,随机特征选择允许随机森林更深入地探索特征空间,允许它们发现比简单回归树更多的交互。事实上,变量之间可能存在相互作用,这些相互作用本身不具有很强的预测性(因此不会产生分裂),但共同作用非常强大。
因果森林相当于随机森林,但用于估计异质处理效应,与因果树和回归树完全相同。正如因果树一样,我们有一个基本问题:我们有兴趣预测一个我们没有观察到的对象:个体处理效果τᵢ。解决方案是创建一个辅助结果变量Y*,其每一次观察的预期值正好是处理效果。
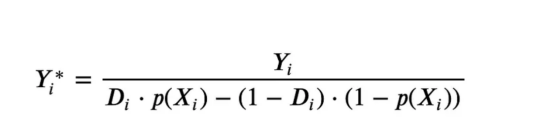
辅助结果变量
如果你想更多地了解为什么这个变量对个体处理效果没有添加偏置的话,请看一下我之前的文章,我在这篇文章中进行了详细的介绍。简而言之,您可以认为Yᵢ*作为单个观测的均值差估计量。
一旦我们有了一个结果变量,为了使用随机森林来估计异质处理效应,我们还需要做一些事情。首先,我们需要建造在每片叶子上具有相同数量的处理单元和控制单元的树。其次,我们需要使用不同的样本来构建树并对其进行评估,即计算每片叶子的平均结果。这个过程通常被称为诚实树(honest trees),因为我们可以将每个叶子的样本视为独立于树结构,所以它对推断非常有用。
在进行评估之前,让我们先为分类变量device、browser和region生成虚拟变量。
现在,我们可以使用随机森林算法来估计异质处理效应。幸运的是,我们不必手动完成所有这些,因为在微软公司的EconML包中已经提供了一个很好的因果树和森林实现。我们将使用其中的CausalForestML函数。
与因果树不同,因果森林更难解释,因为我们无法可视化每一棵树。我们可以使用SingleTreeateInterpreter函数来绘制因果森林算法的等效表示。
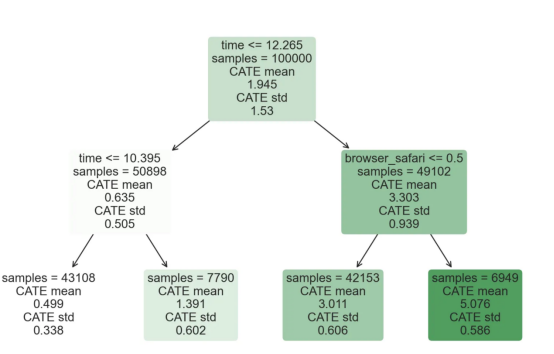
因果森林模型表示
我们可以像因果树模型一样解释树形图。在顶部,我们可以看到数据中的平均$Y^*$的值为1.917$。从那里开始,根据每个节点顶部突出显示的规则,数据被拆分为不同的分支。例如,根据时间是否晚于11.295,第一节点将数据分成大小为46878$和53122$的两组。在底部,我们得到了带有预测值的最终分区。例如,最左边的叶子包含40191$的观察值(时间早于11.295,在非Safari浏览器环境下),我们预测其花费为0.264$。较深的节点颜色表示预测值较高。
这种表示的问题在于,与因果树的情况不同,它只是对模型的解释。由于因果森林是由许多自助树组成的,因此无法直接检查每个决策树。了解在确定树分割时哪个特征最重要的一种方法是所谓的特征重要性。

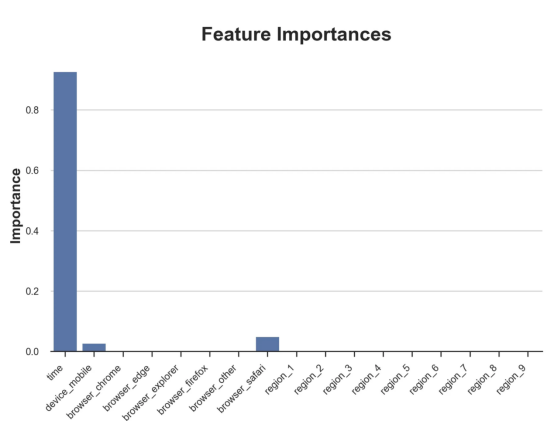
显然,时间是异质性的第一个维度,其次是设备(特别是移动设备)和浏览器(特别是Safari)。其他维度无关紧要。
现在,让我们检查一下模型性能如何。
性能
通常,我们无法直接评估模型性能,因为与标准的机器学习设置不同,我们没有观察到实际情况。因此,我们不能使用测试集来计算模型精度的度量。然而,在我们的案例中,我们控制了数据生成过程,因此我们可以获得基本的真相。让我们从分析模型如何沿着数据、设备、浏览器和区域的分类维度估计异质处理效应开始。
对于每个分类变量,我们绘制了实际和估计的平均处理效果。
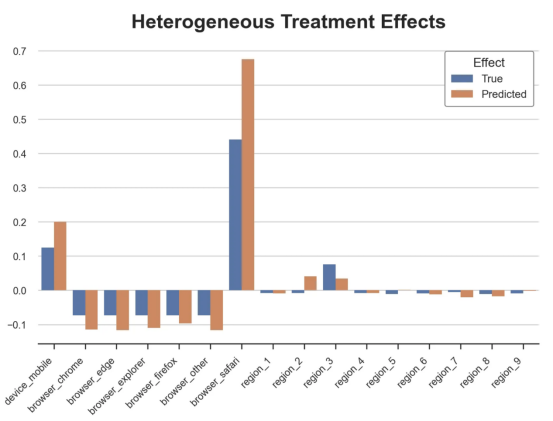
作者提供的每个分类值的真实和估计处理效果
因果森林算法非常善于预测与分类变量相关的处理效果。至于因果树,这是预期的,因为算法具有非常离散的性质。然而,与因果树不同的是,预测更加微妙。
我们现在可以做一个更相关的测试:算法在时间等连续变量下的表现如何?首先,让我们再次隔离预测的处理效果,并忽略其他协变量。
def compute_time_effect(df, hte_model, avg_effect_notime):
我们现在可以复制之前的数字,但时间维度除外。我们绘制了一天中每个时间的平均真实和估计处理效果。
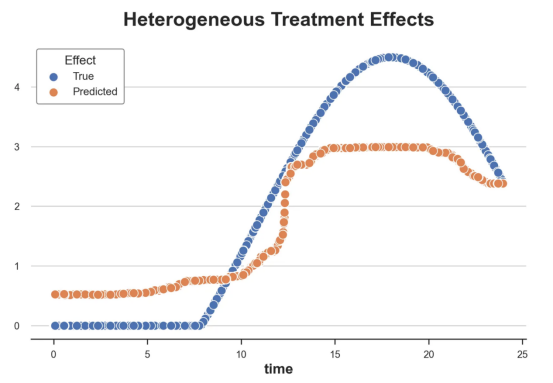
沿时间维度绘制的真实和估计的处理效果
我们现在可以充分理解因果树和森林之间的区别:虽然在因果树的情况下,估计基本上是一个非常粗略的阶跃函数,但我们现在可以看到因果树如何产生更平滑的估计。
我们现在已经探索了该模型,是时候使用它了!
策略定位
假设我们正在考虑向访问我们在线商店的新客户提供4美元的折扣。
折扣对哪些客户有效?我们估计平均处理效果为1.9492美元。这意味着,平均而言折扣并不真正有利可图。然而,现在可以针对单个客户,我们只能向一部分新客户提供折扣。我们现在将探讨如何进行政策目标定位,为了更好地了解目标定位的质量,我们将使用因果树模型作为参考点。
我们使用相同的CauselForestML函数构建因果树,但将估计数和森林大小限制为1。
接下来,我们将数据集分成一个训练集和一个测试集。这一想法与交叉验证非常相似:我们使用训练集来训练模型——在我们的案例中是异质处理效应的估计器——并使用测试集来评估其质量。主要区别在于,我们没有观察到测试数据集中的真实结果。但是我们仍然可以使用训练测试分割来比较样本内预测和样本外预测。
我们将所有观察结果的80%放在训练集中,20%放在测试集中。
首先,让我们仅在训练样本上重新训练模型。
现在,我们可以确定目标策略,即决定我们向哪些客户提供折扣。答案似乎很简单:我们向所有预期处理效果大于成本(4美元)的客户提供折扣。
借助于一个可视化工具,它可以让我们了解处理对谁有效以及如何有效,这就是所谓的处理操作特征(TOC)曲线。这个名字可以看作是基于另一个更著名的接收器操作特性(ROC)曲线的修正,该曲线描绘了二元分类器的不同阈值的真阳性率与假阳性率。这两种曲线的想法类似:我们绘制不同比例受处理人群的平均处理效果。在一个极端情况下,当所有客户都被处理时,曲线的值等于平均处理效果;而在另一个极端情况下,当只有一个客户被处理时曲线的值则等于最大处理效果。
现在让我们计算曲线。
现在,我们可以绘制两个CATE估算器的处理操作特征(TOC)曲线。
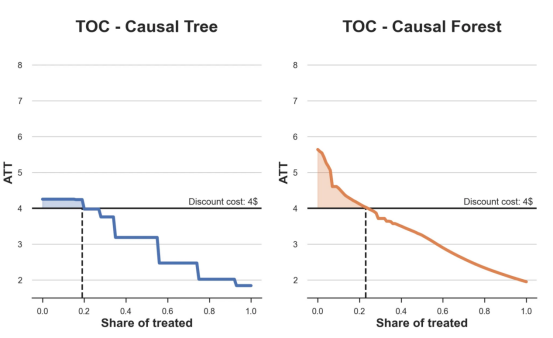
处理操作特性曲线
正如预期的那样,两种估算器的TOC曲线都在下降,因为平均效应随着我们处理客户份额的增加而降低。换言之,我们在发布折扣时越有选择,每个客户的优惠券效果就越高。我还画了一条带有折扣成本的水平线,以便我们可以将TOC曲线下方和成本线上方的阴影区域解释为预期利润。
这两种算法预测的处理份额相似,约为20%,因果森林算法针对的客户略多一些。然而,他们预测的利润结果却大相径庭。因果树算法预测的边际较小且恒定,而因果林算法预测的是更大且更陡的边际。那么,哪一种算法更准确呢?
为了比较它们,我们可以在测试集中对它们进行评估。我们采用训练集上训练的模型,预测处理效果,并将其与测试集上训练模型的预测进行比较。注意,与机器学习标准测试程序不同,有一个实质性的区别:在我们的案例中,我们无法根据实际情况评估我们的预测,因为没有观察到处理效果。我们只能将两个预测相互比较。
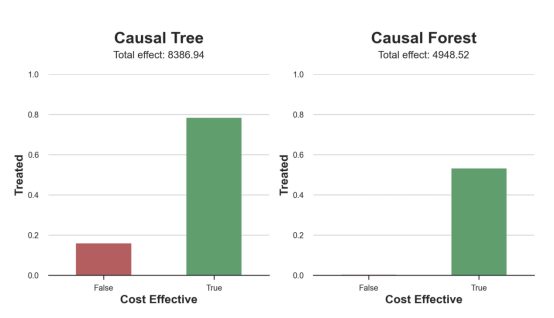
因果树模型似乎比因果森林模型表现得更好一些,总净效应为8386美元——相对于4948美元。从图中,我们也可以了解差异的来源。因果森林算法往往限制性更强,处理的客户更少,没有误报的阳性,但也有很多误报的阴性。另一方面,因果树算法看起来更加“慷慨”,并将折扣分配给更多的新客户。这既转化为更多的真阳性,也转化为假阳性。总之,净效应似乎有利于因果树算法。
通常,我们讨论到这里就可以停止了,因为我们可以做的事情不多了。然而,在我们的案例情形中,我们还可以访问真正的数据生成过程。因此,接下来我们不妨检查一下这两种算法的真实精度。
首先,让我们根据处理效果的预测误差来比较它们。对于每个算法,我们计算处理效果的均方误差。
结果是,随机森林模型更好地预测了平均处理效果,均方误差为0.5555美元,而不是0.9035美元。
那么,这是否意味着更好的目标定位呢?我们现在可以复制上面所做的相同的柱状图,以了解这两种算法在策略目标方面的表现。
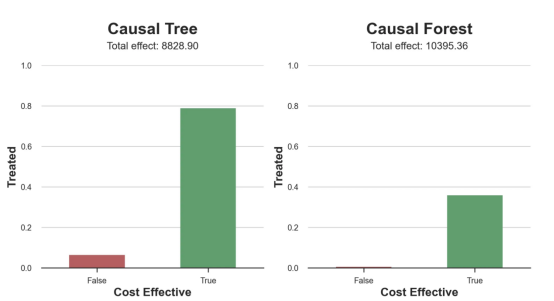
这两幅图非常相似,但结果却大相径庭。事实上,因果森林算法现在优于因果树算法,总效果为10395美元,而非8828美元。为什么会出现这种突然的差异呢?
为了更好地理解差异的来源,让我们根据实际情况绘制TOC。
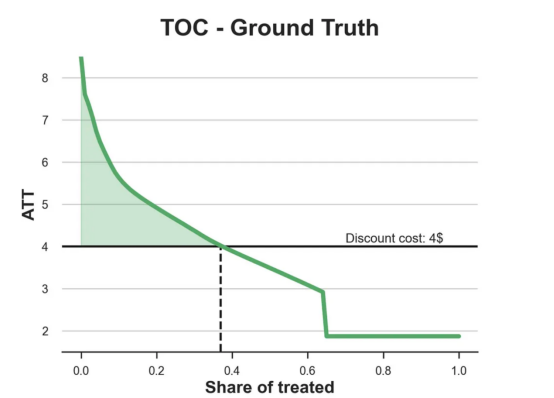
处理操作特性曲线。
正如我们所看到的,TOC是倾斜度非常大的,存在一些平均处理效果非常高的客户。随机森林算法能够更好地识别它们,因此总体上更有效,尽管目标客户较少些。
结论
在这篇文章中,我们学习了一个功能非常强大的估计异质处理效应的算法——因果森林。因果森林建立在与因果树相同的原则上,但受益于对参数空间和装袋算法的更深入探索。
此外,我们还了解了如何使用异质处理效应的估计来执行政策定位。通过识别具有最高处理效果的用户,我们能够确保一项政策有利可图。我们还看到了政策目标与异质处理效应评估目标的不同,因为分布的尾部可能比平均值具有更强的相关性。
参考文献
- S. Athey, G. Imbens, Recursive partitioning for heterogeneous causal effects (2016), PNAS.
- S. Wager, S. Athey, Estimation and Inference of Heterogeneous Treatment Effects using Random Forests (2018), Journal of the American Statistical Association.
- S. Athey, J. Tibshirani, S. Wager, Generalized Random Forests (2019). The Annals of Statistics.
- M. Oprescu, V. Syrgkanis, Z. Wu, Orthogonal Random Forest for Causal Inference (2019). Proceedings of the 36th International Conference on Machine Learning.
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:From Causal Trees to Forests,作者:Matteo Courthoud