
很多时候需要用到连续的id进行数据对比,如判断是否连续等问题。那么,生成连续整数的方式有多种,首先容易想到的是逐步循环,如果想生成1kw条记录,则需要循环1kw次进行插入,那么有没有其他方式呢,效率相对于逐步加一有多少提升呢。带此疑问,我们进行一番测试。
提前创建一张存放记录的表。
CREATE TABLE nums(id INT);
1、使用逐步+1递增的循环方式
DELIMITER $$
CREATE PROCEDURE sp_createNum1 (cnt INT)
BEGIN
DECLARE i INT DEFAULT 1 ;
TRUNCATE TABLE nums ;WHILE i <= cnt DO
BEGIN
INSERT INTO nums SELECT i;
SET i = i+1 ;
END ;
END WHILE ;
END $$
DELIMITER ;
生成20W数据用时达到14min,不是一般的慢。

2、 二的N次方法插入
此方法借鉴于姜老师的书上,不过对此进行了改造,解决输入值与最终获得的记录不一致的情况。
DELIMITER $$
CREATE PROCEDURE `sp_createNum`(cnt INT )
BEGIN
DECLARE i INT DEFAULT 1;
TRUNCATE TABLE nums;
INSERT INTO nums SELECT i;
WHILE i < cnt DO
BEGIN
INSERT INTO nums SELECT id + i FROM nums WHERE id + i<=cnt;
SET i = i*2;
END;
END WHILE;
END$$
DELIMITER ;
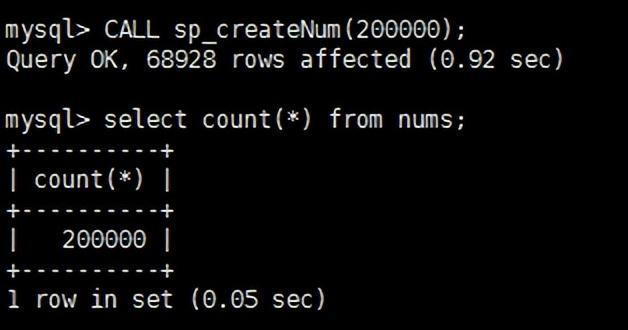
相同的数据库下,本次只需要0.05s,感兴趣的小伙伴可以亲自测一下。
Tips:
性能提升的原因在于方法1需要执行20W次insert,而方法2是按照2的指数级插入,20W数据只需要不到20次的插入即可完成。




































