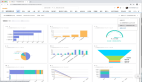
对于一个快速的网络仪表盘来报告指标和数字,你可以考虑使用Streamlit,这是一个相对较新的网络框架,是为ML从业者和数据科学团队建立的。它使用起来非常简单和直观。
这将为我们的团队节省每天重复的数据处理时间......

简介
如果你目前在一个数据或商业智能团队工作,你的任务之一可能是制作一些每日、每周或每月的报告。
虽然获得这些报告并不困难,但还是需要花费不少时间。我们的宝贵时间应该花在更困难的任务上,如训练神经网络或建立数据管道架构。
因此,对于这些平凡的重复性报告,节省我们时间的最好方法是建立一个网络应用程序,其他团队可以自己访问和下载报告。
我说的不是Tableau或PowerBI这样的付费工具(如果公司预算充足的话,你可以使用它们)。有一些高级的网络框架,比如Flask和Django,通常用于建立一个正常运作的网站。
但是,对于一个快速的网络仪表盘来报告指标和数字,你可以考虑使用Streamlit,这是一个相对较新的网络框架,是为ML从业者和数据科学团队建立的。它使用起来非常简单和直观。
内容
我将通过使用一个群组分析的例子来指导你如何构建和部署它。
对于每个部分,我将介绍一个代码模板(你可以在你自己的项目中重新使用)和我的代码(用于本文中使用的队列分析例子)。
- 创建一个Python文件
- 在终端上运行该文件,在本地机器上看到仪表板
- 部署给其他团队使用
1.创建一个Python文件
我们必须创建一个Python文件,以后我们可以从终端调用该文件,在浏览器上显示结果。
你可以给这个文件取任何你想要的名字。这里我把它叫做cohort-demo.py。
代码模板
# 这些数据可以在公众号后台回复【云朵君】,联系作者获取。
# 1.导入必要的库
import pandas as pd
import numpy as np
import streamlit as st
# 2.设置页面配置
st.set_page_config(
page_title="This is my title", # 页面的标题
page_icnotallow="📈", # favicon
layout="wide",
)
# 3.定义你的项目中使用的所有函数
# 4.对于每一个函数,在其前面添加"@st.experimental_memo"。这就是
# 来记忆每个函数的执行。这将使应用程序运行得更快。
# 特别是当用户与仪表盘上的一些元素互动时
@st.experimental_memo
def function(x):
return y
组群分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
from datetime import date, datetime
import streamlit as st
st.set_page_config(
page_title="Cohorts Dashboard",
page_icnotallow="📈",
layout="wide",
)
@st.experimental_memo
def purchase_rate(customer_id):
purchase_rate = [1]
counter = 1
for i in range(1,len(customer_id)):
if customer_id[i] != customer_id[i-1]:
purchase_rate.append(1)
counter = 1
else:
counter += 1
purchase_rate.append(counter)
return purchase_rate
@st.experimental_memo
def join_date(date, purchase_rate):
join_date = list(range(len(date)))
for i in range(len(purchase_rate)):
if purchase_rate[i] == 1:
join_date[i] = date[i]
else:
join_date[i] = join_date[i-1]
return join_date
# 我没有在这里定义所有的函数,因为这将延长文章的篇幅。
# 我将在文章的最后提供完整的代码。
现在我们建立第一个屏幕,如下所示。这将首先让用户上传文件,然后运行以产生输出。

代码模板:你可以用任何名字替换 "my_company"。
st.title("Cohort Interactive Dashboard Demo")
st.markdown("""
This webapp performs cohort analysis of my_company data!
* **Python libraries used:** base64, pandas, streamlit, numpy, matplotlib, seaborn
* **Data source:** [Shopify](https://company_name.myshopify.com/admin)
* You need to select the data file first to proceed.
""")
uploaded_file = st.file_uploader("Choose a file") # 来上传文件一旦用户上传了一个文件,下一个屏幕将看起来像这样。

为了建立这个,我们需要。
- 选择群组的类型:这是一个单一的选择。它可以是独特的客户保留率,或百分比或AOV(平均订单价值)方面的。
- 选择队列:这是多选择。人们可以看一个特定的队列或更多。

代码模板
If uploaded_file is not None:# 这很重要,因为没有这个。
# 当没有上传的文件时,会出现
# 一个错误,因为df没有被定义....
df = pd.read_csv(upload_file) # 读取该文件
df_processed = process_df(df) # 清洁数据
# 仪表盘标题
st.header("Live Dashboard")
# 过滤器
first_filter = st.selectbox('Select first filter',['Option 1', 'Option 2', 'Option 3])
second_filter = st.multiselect('Select second filter', ['Option 1','Option 2','Option 3','Option 4'])
output = display_function(data_input,first_filter,second_filter)
st.dataframe(output)
st.download_button(label='Download csv', data=output.to_csv(), mime='text/csv') # 来下载该文件
组群分析
if uploaded_file is not None:
df = pd.read_csv(uploaded_file)
df_processed = process_df(df)
df_cohorts = cohort_numbers(df_processed)
cohorts = cohort_percent(df_cohorts)
# 通过使用f-strings动态标题
st.header(f"Live {cohorts.index[0]} to {cohorts.index[-1]} Cohort Dashboard")
# 过滤器
first_filter= st.selectbox('Select type of cohort',['By unique customers', 'By percentage', 'By AOV'])
second_filter = st.multiselect('Select cohort', list(cohorts.index))
output = select_which_table_to_draw(df_processed,first_filter,second_filter)
st.dataframe(output)
st.download_button(label='Download csv', data=output.to_csv(), mime='text/csv')
最后建立3个指标

代码模板
kpi1, kpi2, kpi3 = st.columns(3) # 创建三个占位符
if uploaded_file is not None:
aov = np.mean(df['total_sales'])
aov_goal = 95.00
kpi1.metric(
# 给这个指标贴上标签
label="AOV",
# 计算度量值
value=f"$ {round(aov,2)}",
# 计算与目标相比的变化(向上/向下箭头)
delta=f"-${round(aov_goal-aov,2)}" if aov_goal>aov else f"${round(aov-aov_goal,2)}",
)
nc = np.mean(df.loc[df['customer_type']=='First-time'].groupby(['day']).count()['customer_id'])
nc_goal = 30
kpi2.metric(
label="New customers/day",
value=int(nc),
delta=f"-{round((nc_goal-nc)/nc_goal*100,2)}%" if nc_goal>nc else f"{round((nc - nc_goal)/nc_goal*100,0)}%",
)
rc = np.mean(df.loc[df['customer_type']=='Returning'].groupby(['day']).count()['customer_id'])
rc_goal = 250
kpi3.metric(
label="Returning customers/day",
value= int(rc),
delta=f"-{round((rc_goal - rc)/rc_goal*100,2)}%" if rc_goal>rc else f"{round((rc-rc_goal)/rc_goal*100,2)}%"
)
2.在终端上运行该文件,在本地机器上显示
streamlit run cohort-demo.py

在右上角,你会看到一个选项,即每当你编辑cohort-demo.py时总是运行。
3.在Heroku上部署仪表板
首先在你的GitHub账户上创建GitHub仓库

创建requirements.txt、setup.sh和Procfile
requirements.txt(这是为了添加你在cohort-demo.py中使用的所有必要库。)
#只是简单地列出所有的库。你也可以包括版本
pandas
numpy
streamlit
matplotlib
seaborn
datetime
plotly
setup.sh
#只要复制和粘贴这个
mkdir -p ~/.streamlit/
echo "\
[server]\n\
headless = true\n\
port = $PORT\n
enableCORS = false\n
\n\
" > ~/.streamlit/config.toml
Procfile
web: sh setup.sh && streamlit run cohort-demo.py
- 将cohort-demo.py上传至资源库
- 打开Heroku(你应该在Heroku上创建一个账户)。
在右上角,点击 "Create new app"

在部署方式下,选择GitHub

然后将GitHub账户连接到Heroku。然后输入仓库的名称(在本例中,它是cohort_analysis_demo)。
一旦连接,在手动部署下,点击部署分支

到这里我们只需要等待它的部署。然后就完成了!URL链接将被创建。
刚刚将仪表盘部署到生产中,团队成员现在可以自己访问和分析数据。
他们可以简单地上传任何符合你定义的格式的数据集。即本例中的客户交易数据。
最终结果

总结
希望能够帮助到大家,仅作为一个demo参考。其实Streamlit可以做很多很酷的事情,如果你像我一样,在不了解Nodejs、Flask和Django等网络开发框架的情况下,可以使用它来快速创建一个仪表盘。
虽然如此,我仍然相信了解JS/HTML/CSS和软件工程概念会更有优势。所以我确实建议你花空闲时间学习这些技术。