目前最流行的大数据查询引擎非hive莫属,它是基于MR的类SQL查询工具,会把输入的查询SQL解释为MapReduce,能极大的降低使用大数据查询的门槛, 让一般的业务人员也可以直接对大数据进行查询。但因其基于MR,运行速度是一个弊端,通常运行一个查询需等待很久才会有结果。对于此情况,创造了hive的facebook不负众望,创造了新神器---presto,其查询速度平均比hive快10倍,现在就来部署体验一下吧。
一、 准备工作
操作系统: centos7
JAVA: JDK8(155版本及以上),我使用的是jdk1.8.0_191
presto server:presto-server-0.221.tar.gz
presto client: presto-cli-0.221-executable.jar
注:
1、本次是基于hive来进行部署使用,因此相关节点已部署hadoop、hive。
2、presto官网地址为https://prestodb.github.io presto server、client及jdbc jar均可以从官网下载。
二、 部署阶段
1、 将jdk、 presto server presto client 上传至各服务器上
jdk包我上传至/usr/local 目录,并解压、配置软链接,配置环境变量,如不配置环境变量,也可在launcher里修改。
presto server及client上传至 /opt/presto下,同时解压server包。

2、各节点信息如下
其中包含一个Coordinator节点及8个worker节点。
ip | 节点角色 | 节点名 |
192.168.11.22 | Coordinator | node22 |
192.168.11.50 | Worker | node50 |
192.168.11.51 | Worker | node51 |
192.168.11.52 | Worker | node52 |
192.168.11.53 | Worker | node53 |
192.168.11.54 | Worker | node54 |
192.168.11.55 | Worker | node55 |
192.168.11.56 | Worker | node56 |
192.168.11.57 | Worker | node57 |
3、创建presto数据及日志目录
以下操作各节点均相同,只有配置文件处需根据各节点情况,对应修改。
4、创建etc目录
cd /opt/presto/presto-server-0.221
mkdir etc
5、创建所需的配置文件
(1)创建并配置 config.properties
如果是Coordinator节点,建议如下配置(内存大小根据实际情况修改)
vim config.properties
## 添加如下内容
coordinator=true
datasources=hive
node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=80GB
query.max-memory-per-node=10GB
query.max-total-memory-per-node=10GB
discovery-server.enabled=true
discovery.uri=http://192.168.11.22:8080
如果是worker 节点:
vim config.properties ## 添加如下内容
coordinator=false
#datasources=hive
#node-scheduler.include-coordinator=false
http-server.http.port=8080
query.max-memory=80GB
query.max-memory-per-node=10GB
query.max-total-memory-per-node=10GB
#discovery-server.enabled=true
discovery.uri=http://192.168.11.22:8080
参数说明:
coordinator:是否运行该实例为coordinator(接受client的查询和管理查询执行)。
node-scheduler.include-coordinator:coordinator是否也作为work。对于大型集群来说,在coordinator里做worker的工作会影响查询性能。
http-server.http.port:指定HTTP端口。Presto使用HTTP来与外部和内部进行交流。
query.max-memory: 查询能用到的最大总内存
query.max-memory-per-node: 查询能用到的最大单结点内存
discovery-server.enabled: Presto使用Discovery服务去找到集群中的所有结点。每个Presto实例在启动时都会在Discovery服务里注册。这样可以简化部署, 不需要额外的服务,Presto的coordinator内置一个Discovery服务。也是使用HTTP端口。
discovery.uri: Discovery服务的URI。将192.168.11.22:8080替换为coordinator的host和端口。这个URI不能以斜杠结尾,这个错误需特别注意,不然会报404错误。
另外还有以下属性:
jmx.rmiregistry.port: 指定JMX RMI的注册。JMX client可以连接此端口
jmx.rmiserver.port: 指定JXM RMI的服务器。可通过JMX监听。
(2)配置 jvm.config
vim jvm.config
# 添加如下内容
-server
-Xmx20G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p
JVM配置文件包含启动Java虚拟机时的命令行选项。格式是每一行是一个命令行选项。此文件数据是由shell解析,所以选项中包含空格或特殊字符会被忽略。
(3)配置log.properties
vim log.properties
# 添加如下内容
com.facebook.presto=INFO
日志级别有四种,DEBUG, INFO, WARN and ERROR。
(4)配置node.properties
vim node.properties
## 添加如下内容
node.environment=presto_ocean
node.id=node22
node.data-dir=/data/presto
参数说明:
node.environment: 环境名字,Presto集群中的结点的环境名字都必须是一样的。
node.id: 唯一标识,每个结点的标识都必须是为一的。就算重启或升级Presto都必须还保持原来的标识。
node.data-dir: 数据目录,Presto用它来保存log和其他数据
(5)配置catalog及hive.properties
创建 catalog目录,因本次使用的hive,因此在此目录下创建hive.properties 并配置对应参数
mkdir catalog
vim hive.properties
# 添加如下内容
connector.name=hive-hadoop2
hive.metastore.uri=thrift://192.168.11.22:9083
hive.config.resources=/opt/hadoop/hadoop-3.2.0/etc/hadoop/core-site.xml,/opt/hadoop/hadoop-3.2.0/etc/hadoop/hdfs-site.xml
hive.allow-drop-table=true
至此 相关配置文件配置完成。
三、 启动presto-server并连接
进入/opt/presto/presto-server-0.221/bin,有launcher命令。

如果需要配置JAVA等环境变量也可以在此文件里修改。在此处修改的好处在于可以与不同版本的jdk共存 而不影响原有业务。
1、启动presto-server
此时如果/data/presto/var日志生成,且无报错信息,代表启动正常。
2、presto-cli 连接
把下载的jar包:
presto-cli-0.221-executable.jar 重命名为:presto 并且赋予权限。
ln -s presto-cli-0.221-executable.jar presto
chmod +x presto
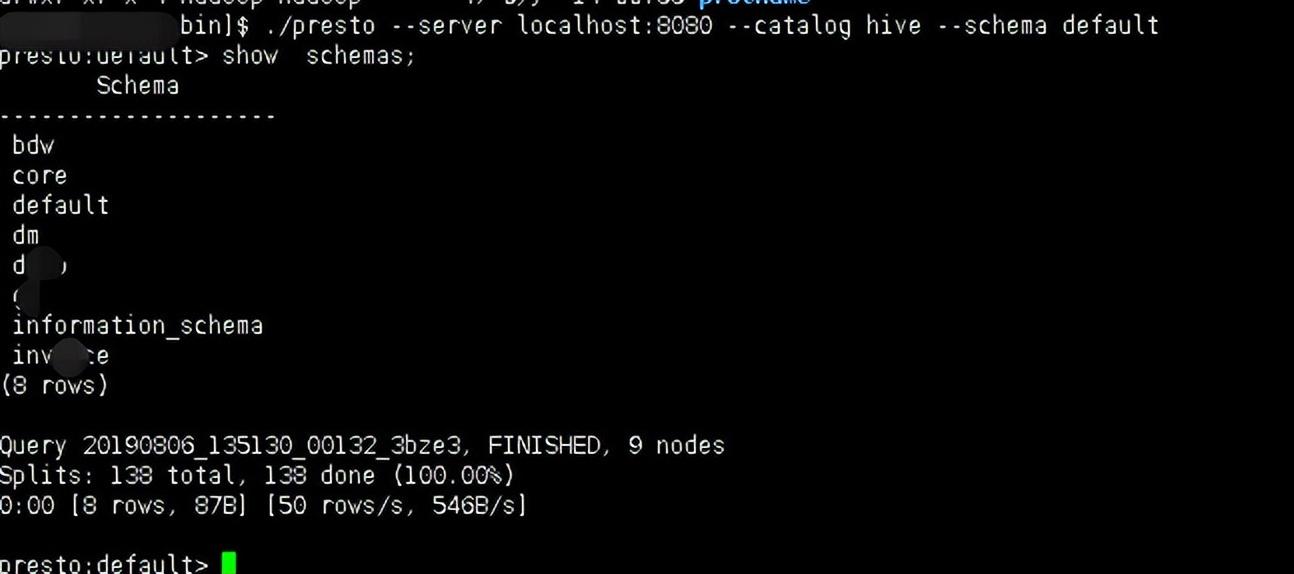
./presto --server localhost:8080 --catalog hive --schema default
此时可以查看到hive里的库及表。
3、查看web界面
登录http://192.168.11.22:8080/ui/可查看整体状态。
至此,presto部署就完成了。其与hive的性能对比、工作原理及使用建议等后续有机会再介绍。