相比于一大堆复杂的 JVM 调优过程,本文介绍的排查步骤还是挺简单的,可以帮助各位小伙伴排查一些简单问题,面试官问起来也好过啥也不会(这个 CPU 打满如何排查我被问过好多次......)。
模拟高 CPU 场景
这里就不麻烦地建 Web 项目了,用一个最原始的 Java 项目来模拟高 CPU 场景。打开 IDEA,创建一个 Java 项目,里面写一个死循环,循环里面不断地创建对象:

然后打成 jar 包,这个没啥难度,懒得敲命令的话直接 IDEA 中点几下就可以,File -> Project Settings -> Artifacts:

执行成功后可以在 /out/artifacts/highCpuTest.jar 文件夹下找到 jar 包:

将这个 jar 包上传到服务器中并运行(我是上传到 /home/test 目录下了)。为了防止把服务器搞崩,我选择利用 Docker 运行,并限制了最大内存 200M。具体步骤如下:
这块不是重点哈,可以直接忽略
首先拉取 JDK 镜像并创建一个名为 high-cpu-test 的容器:
然后将 /home/test/hightCpuTest.jar 复制到 high-cpu-test 容器中的 home 目录下:
这样就可以在 Docker 中执行这个 jar 包了:
排查步骤
你可以选择另开一个终端然后进入 high-cpu-test 容器内部执行以下步骤
1. 找到占用 CPU 最高的进程
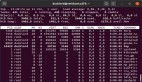
首先第一步,利用 top 命令监控 CPU 运行状态,显示进程运行信息,看看到底是哪些进程占用了大量 CPU:
可以键入大写的 P,使得进程按照 CPU 使用率排序:

可以看到目前占用 CPU 最多的进程的 PID 是 85,遥遥领先于其他进程。
2. 找到占用 CPU 最高的线程
虽然找到了占用 CPU 最高的进程 PID 是 85,但并不能直接就开始定位代码了,因为一个进程中有很多线程,不可能所有线程都占用了大量 CPU,所以我们现在要做的就是找出 PID 85 这个进程中占用 CPU 最高的线程。
执行 top -Hp pid 命令,pid 就是上面我们排查出来的进程 PID:
然后同样的,键入大写 P,使得线程按照 CPU 使用率排序:

可以看到目前占用 CPU 最多的进程的 PID 是 95,遥遥领先于其他线程。
3. 打印线程堆栈信息
接下来我们要做的就是打印出 PID 95 这个线程的堆栈信息,然后根据堆栈信息定位代码。
首先,需要通过 printf 命令将 PID 95 转化成 16 进制,因为堆栈里的线程 PID 是用 16 进制表示的

得到 16 进制的线程 PID 为 0x5f。这样,就可以通过 jstack 命令查看堆栈信息了:
-C<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容
执行结果如下图所示:

如上图打印出了线程的堆栈信息,可以看到,定位到了 highCpuThread 线程中的 lambda 代码,具体在第 15 行。Over~