CFS 原理
CFS(Completely Fair Scheduler), 也即是完全公平调度器。
CFS 的产生就是为了在真实的硬件上模拟“理想的多任务处理器”,使每个进程都能够公平的获得 CPU。
CFS 调度器没有时间片的概念,CFS 的理念就是让每个进程拥有相同的使用 CPU 的时间。比如有 n 个可运行的进程,那么每个进程将能获取的处理时间为 1/n。
在 CFS 调度器中引用权重来代表进程的优先级。各个进程按照权重的比例来分配使用 CPU 的时间。比如2个进程 A 和 B, A 的权重为 100, B 的权重为200,那么 A 获得的 CPU 的时间为 100/(100+200) = 33%, B 进程获得的CPU 的时间为 200/(100+200) = 67%。
在引入权重之后,在一个调度周期中分配给进程的运行时间计算公式如下:
实际运行时间 = 调度周期 * 进程权重 / 所有进程权重之和
可以看到,权重越大,分到的运行时间越多。
- 调度周期:在某个时间长度可以保证运行队列中的每个进程至少运行一次,我们把这个时间长度称为调度周期。也称为调度延迟,因为一个进程等待被调度的延迟时间是一个调度周期。
- 调度最小粒度:为了防止进程切换太频繁,进程被调度后应该至少运行一小段时间,我们把这个时间长度称为调度最小粒度。
调度周期的默认值是20毫秒,调度最小粒度的默认值是4毫秒,如下所示,两者的单位都是纳秒。
//默认调度周期 20ms
unsigned int sysctl_sched_latency = 20000000ULL;
//默认调度最小粒度 4ms
unsigned int sysctl_sched_min_granularity = 4000000ULL;
// 默认一个调度周期内的进程数:sysctl_sched_latency / sysctl_sched_min_granularity
static unsigned int sched_nr_latency = 5;
如果运行队列中的进程数量太多,导致把调度周期 sysctl_sched_latency 平分给进程时的时间片小于调度最小粒度,那么调度周期取 “调度最小粒度 × 进程数量”。
CFS 调度器中使用 nice 值(取值范围为[-20 ~ 19])作为进程获取处理器运行比的权重:nice 值越高(优先级越低)的进程获得的 CPU使用的权重越低。
在用户态进程的优先级 nice 值与 CFS 调度器中的权重又有什么关系?
在内核中通过 prio_to_weight 数组进行 nice 值和权重的转换。
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};从 nice 和权重的对应值可知,nice 值为 0 的权重为 1024(默认权重), nice 值为1的权重为 820,nice 值为 15 的权重值为 36,nice 值为19的权重值为 15。
例如:假设调度周期为12ms,2个相同nice的进程其权重也相同,那么2个进程各自的运行时间为 6ms。
假设进程 A 和 B 的 nice 值分别为0、1,那么权重也就分别为 1024、820。因此,A 实际运行时间为 12 * 1024/(1024+820)= 6.66ms ,B 实际运行时间为 12 * 820/(1024+820)= 5.34ms。
从结果来看,2个进程运行时间时不一样的。由于A的权重高,优先级大,会出现 A 一直被调度,而 B 最后被调度,这就失去了公平性,所以 CFS 的存在就是为了解决 这种不公平性。
因此为了让每个进程完全公平调度,因此就引入了一个 vruntime (虚拟运行时间,virtual runtime)的概念, 每个调度实体都有一个 vruntime,该vruntime 根据调度实体的调度而不停的累加,CFS 根据 vruntime 的大小来选择调度实体。
调度实体的结构如下:
struct sched_entity {
struct load_weight load; // 调度实体的负载权重值
struct rb_node run_node; //用于添加到CFS运行队列的红黑树中的节点
unsigned int on_rq;//用于表示是否在运行队列中
u64 exec_start;//当前调度实体的开始运行时间
u64 sum_exec_runtime;//调度实体执行的总时间
/*虚拟运行时间,在时间中断或者任务状态发生改变时会更新
其会不停的增长,增长速度与load权重成反比,load越高,增长速度越慢,就越可能处于红黑树最左边被调度
每次时钟中断都会修改其值。注意其值为单调递增,在每个调度器的时钟中断时当前进程的虚拟运行时间都会累加。
单纯的说就是进程们都在比谁的vruntime最小,最小的将被调度
*/
u64 vruntime;//虚拟运行时间,这个时间用于在CFS运行队列中排队
u64 prev_sum_exec_runtime;//上一个调度实体运行的总时间
...
#ifdef CONFIG_FAIR_GROUP_SCHED
struct sched_entity *parent; //指向调度实体的父对象
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq; //指向调度实体归属的CFS队列,也就是需要入列的CFS队列
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;//指向归属于当前调度实体的CFS队列
#endif
};
虚拟时间和实际时间的关系如下:
虚拟运行时间 = 实际运行时间 *(NICE_0_LOAD / 进程权重)
其中,NICE_0_LOAD 是 nice为0时的权重(默认),也即是 1024。也就是说,nice 值为0的进程实际运行时间和虚拟运行时间相同。
虚拟运行时间一方面跟进程运行时间有关,另一方面跟进程优先级有关。
进程权重越大, 运行同样的实际时间, vruntime 增长的越慢。
一个进程在一个调度周期内的虚拟运行时间大小为:
vruntime = 进程在一个调度周期内的实际运行时间 * 1024 / 进程权重= (调度周期 * 进程权重 / 所有进程总权重) * 1024 / 进程权重= 调度周期 * 1024 / 所有进程总权重。
可以看到, 一个进程在一个调度周期内的 vruntime 值大小是不和该进程自己的权重相关的, 所以所有进程的 vruntime 值大小都是一样的。
接着上述的例子,通过虚拟运行时间公式可得:
A 虚拟运行时间为 6.66 * (1024/1024) = 6.66ms,
B 虚拟运行时间为 5.34* (1024/820) = 6.66ms,
在一个调度周期过程中,各个调度实体的 vruntime 都是累加的过程,保证了在一个调度周期结束后,每个调度实体的 vruntime 值大小都是一样的。
由于权重越高,应该优先的得到运行,因此 CFS 采用虚拟运行时间越小,越先调度。
当权重越高的进程随着调度的次数多,其 vruntime 的累加也就越多。当其 vruntime 的累加大于其他低优先级进程的 vruntime 时,低优先级的进程得以调度。这就保证了每个进程都可以调度而不会出现高优先级的一直得到调度,而优先级低的进程得不到调度而产生饥饿。
一言以蔽之:在CFS中,不管权重高低,根据 vruntime 大小比较,大家都轮着使用 CPU。
当然,根据一个调度周期中分配给进程的实际运行时间计算公式可知,在一个调度周期内,虽然大家都轮着使用 CPU,但是实际运行时间的多少和权重也是有关的,权重越高,总的实际运行的时间也就越多。在一个调度周期结束后,各个调度实体的 vruntime 最终还是相等的。
那么在 CFS 中 vruntime 是怎么使用的呢?
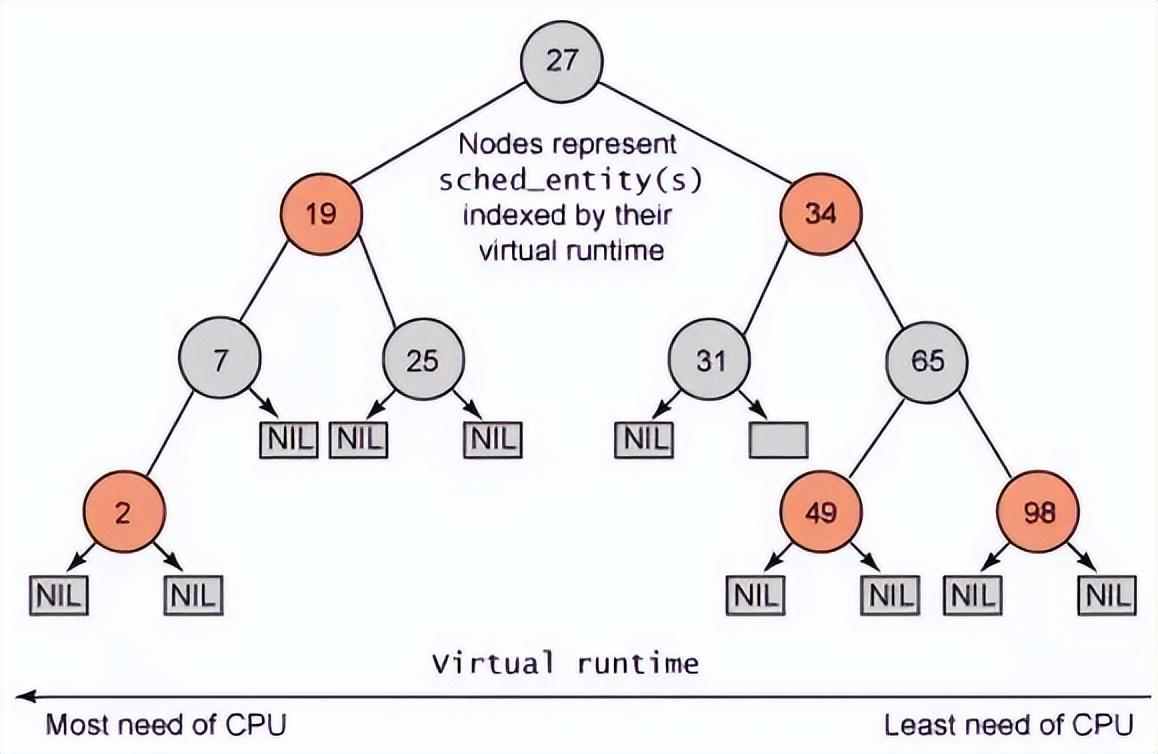
CFS 中的就绪队列是一棵以 vruntime 为键值的红黑树,虚拟时间越小的进程越靠近整个红黑树的最左端。因此,调度器每次选择位于红黑树最左端的那个进程,该进程的 vruntime 最小,也就最应该优先调度。
实际获取最左叶子节点时并不会遍历树,而是 vruntime 最小的节点已经缓存在了 rb_leftmost 字段中了,因此 CFS 很快可以获取 vruntime 最小的节点。
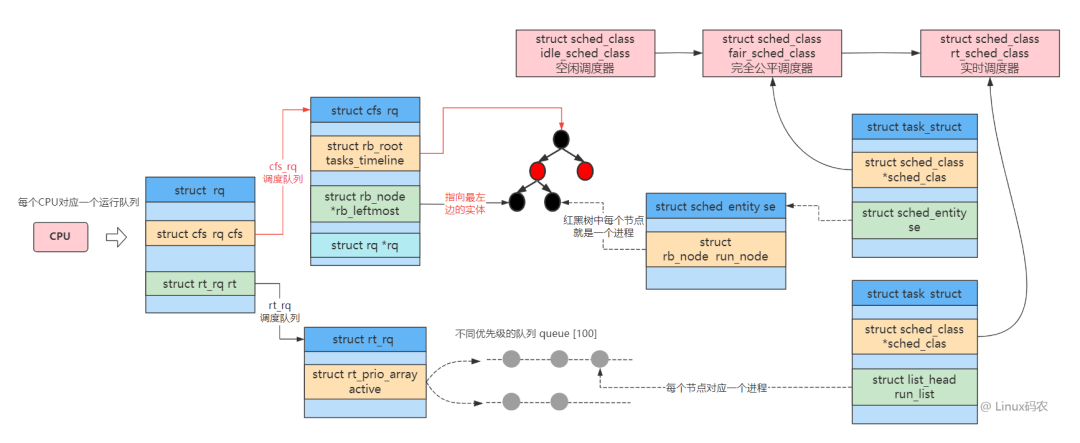
其中红黑树的结构如下:
CFS 调度时机
与 CFS 相关的有如下几个过程:
- 创建新进程: 创建新进程时, 需要设置新进程的 vruntime 值以及将新进程加入红黑树中. 并判断是否需要抢占当前进程。
- 进程的调度: 进程调度时, 需要把当前进程加入红黑树中, 还要从红黑树中挑选出下一个要运行的进程。
- 进程唤醒: 唤醒进程时, 需要调整睡眠进程的 vruntime 值, 并且将睡眠进程加入红黑树中. 并判断是否需要抢占当前进程。
- 时钟周期中断: 在时钟中断周期函数中, 需要更新当前运行进程的 vruntime 值, 并判断是否需要抢占当前进程。
创建新进程
创建新进程的系统调用 fork, vfork, clone. 这三个系统调用最终都是调用do_fork() 函数.在 do_fork() 函数中, 主要就是设置新进程的 vruntime 值, 将新进程加入到红黑树中, 判断新进程是否可以抢占当前进程.
do_fork
--> wake_up_new_task
--> task_new_fair //设置新进程的vruntime值,并将其加入就绪队列中
--> check_preempt_curr //检查新进程是否可以抢占当前进程
task_new_fair 实现如下:
static void task_new_fair(struct rq *rq, struct task_struct *p)
{
struct cfs_rq *cfs_rq = task_cfs_rq(p);
struct sched_entity *se = &p->se, *curr = cfs_rq->curr;
int this_cpu = smp_processor_id();
sched_info_queued(p);
update_curr(cfs_rq); //更新当前进程的vruntime值
place_entity(cfs_rq, se, 1); //设置新进程的vruntime值, 1表示是新进程
/* 'curr' will be NULL if the child belongs to a different group */
//sysctl_sched_child_runs_first值表示是否设置了让子进程先运行
if (sysctl_sched_child_runs_first && this_cpu == task_cpu(p) &&
curr && curr->vruntime < se->vruntime) {
/*
• Upon rescheduling, sched_class::put_prev_task() will place
• 'current' within the tree based on its new key value.
*/
swap(curr->vruntime, se->vruntime); //当子进程的vruntime值大于父进程的vruntime时, 交换两个进程的vruntime值
}
enqueue_task_fair(rq, p, 0);//将新任务加入到就绪队列中
//设置TIF_NEED_RESCHED标志值,该标记标志进程是否需要重新调度,如果设置了,就会发生调度
resched_task(rq->curr);
}
该函数给新进程设置一个新的 vruntime,然后加入到就绪队列中,等待调度。
check_preempt_curr 在 CFS 中 对应的为 check_preempt_wakeup 函数,其实现如下:
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p)
{
struct task_struct *curr = rq->curr;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
struct sched_entity *se = &curr->se, *pse = &p->se;
unsigned long gran;
...
// gran 为进程调度粒度
gran = sysctl_sched_wakeup_granularity; // 10 ms
if (unlikely(se->load.weight != NICE_0_LOAD))
gran = calc_delta_fair(gran, &se->load); //计算调度粒度
/*
调度粒度的设置, 是为了防止这么一个情况: 新进程的vruntime值只比当前进程的vruntime小一点点, 如果此时发生重新调度,则新进程只运行一点点时间后,其vruntime值就会大于前面被抢占的进程的vruntime值, 这样又会发生抢占,所以这样的情况下,系统会发生频繁的切换。故, 只有当新进程的vruntime值比当前进程的vruntime值小于调度粒度之外,才发生抢占。
所以,当前进程的虚拟运行时间se->vruntime 比 下一个进程 pse->vruntime 大于一个调度粒度,说明当前进程应该被抢占,应该切换出去让别vruntime小的进程进行运行,因此给当前进程设置是一个重新调度标记TIF_NEED_RESCHED,当某个时机根据该标记进行调用schedule(),这时会重新选择一个进程进行切换。
*/
if (pse->vruntime + gran < se->vruntime)
resched_task(curr);
}
该功能就是根据调度粒度,判断是否需要设置被抢占标记,若需要,这调用resched_task 把当前进程设置成被抢占标记TIF_NEED_RESCHED,该标记说明当前进程运行的时间够多的了,应该切换出去,让出 CPU 让让别的进程运行。
static void resched_task(struct task_struct *p)
{
int cpu;
assert_spin_locked(&task_rq(p)->lock);
if (unlikely(test_tsk_thread_flag(p, TIF_NEED_RESCHED)))
return;
//设置被被抢占标记
set_tsk_thread_flag(p, TIF_NEED_RESCHED);
cpu = task_cpu(p);
if (cpu == smp_processor_id())
return;
/* NEED_RESCHED must be visible before we test polling */
smp_mb();
if (!tsk_is_polling(p))
smp_send_reschedule(cpu);
}
设置完TIF_NEED_RESCHED 不代表当前进程立马就切换出去了,而是等待一定时机,然后会根据TIF_NEED_RESCHED 标记调用schedule()进行调度切换。
进程的调度
进程调度的主要入口点是 schedule 函数,它正是内核其他部分用于调用进程调度器的入口:选择哪个进程可以运行,何时投入运行。
schedule 通常要和一个具体的调度类相关联,也即是,它会找到最高优先级的调度类,然后从就绪队列中选择下一个该运行的进程。
当调用 schedule() 进行任务切换的时候,调度器调用 pick_next_task 函数选择下一个将要执行的任务,这是相对默认 nice 值进程的进程而言的。
asmlinkage void __sched schedule(void)
{
/*prev 表示调度之前的进程, next 表示调度之后的进程 */
struct task_struct *prev, *next;
long *switch_count;
struct rq *rq;
int cpu;
need_resched:
preempt_disable(); //关闭内核抢占
cpu = smp_processor_id(); //获取所在的cpu
rq = cpu_rq(cpu); //获取cpu对应的运行队列
rcu_qsctr_inc(cpu);
prev = rq->curr; /*让prev 成为当前进程 */
switch_count = &prev->nivcsw;
/释放全局内核锁,并开this_cpu 的中断/
release_kernel_lock(prev);
need_resched_nonpreemptible:
__update_rq_clock(rq); //更新运行队列的时钟值
...
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
// 对应到CFS,则为 put_prev_task_fair
prev->sched_class->put_prev_task(rq, prev); //通知调度器类当前运行进程要被另一个进程取代
/*pick_next_task以优先级从高到底依次检查每个调度类,从最高优先级的调度类中选择最高优先级的进程作为
下一个应执行进程(若其余都睡眠,则只有当前进程可运行,就跳过下面了)*/
next = pick_next_task(rq, prev); //选择需要进行切换的task
...
}
在选择下一个进程前,先调用 put_prev_task (对应到 CFS 为put_prev_task_fair),计算下当前进程的运行时间,根据当前运行时间计算出虚拟运行时间,并累加到 vruntime,然后把当前进程根据 vruntime 重新加入到就绪队列红黑树中,等待下一次被调度。
put_prev_task_fair
--> put_prev_entity
--> update_curr
--> __update_curr //更新当前调度实体的实际运行时间和虚拟运行时间
--> __enqueue_entity //把当前调度实体重新加入到就绪队列红黑树中等待下一次调度
/*
cfs_rq:可运行队列对象。
curr:当前进程调度实体。
delta_exec:实际运行的时间。
__update_curr() 函数主要完成以下几个工作:
更新进程调度实体的总实际运行时间。
根据进程调度实体的权重值,计算其使用的虚拟运行时间。
把计算虚拟运行时间的结果添加到进程调度实体的 vruntime 字段。
*/
static inline void
__update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr,
unsigned long delta_exec)
{
unsigned long delta_exec_weighted;
u64 vruntime;
schedstat_set(curr->exec_max, max((u64)delta_exec, curr->exec_max));
//// 增加当前进程总实际运行的时间
curr->sum_exec_runtime += delta_exec;
// 更新cfs_rq的实际执行时间cfs_rq->exec_clock
schedstat_add(cfs_rq, exec_clock, delta_exec);
//根据实际运行时间计算虚拟运行时间并累加到当前进程的虚拟运行时间
delta_exec_weighted = delta_exec;
//// 根据实际运行时间计算其使用的虚拟运行时间
if (unlikely(curr->load.weight != NICE_0_LOAD)) {
delta_exec_weighted = calc_delta_fair(delta_exec_weighted,
&curr->load);
}
curr->vruntime += delta_exec_weighted; // 更新进程的虚拟运行时间
/*
• maintain cfs_rq->min_vruntime to be a monotonic increasing
• value tracking the leftmost vruntime in the tree.
*/
if (first_fair(cfs_rq)) {
vruntime = min_vruntime(curr->vruntime,
__pick_next_entity(cfs_rq)->vruntime);
} else
vruntime = curr->vruntime;
/*min_vruntime记录CFS运行队列上vruntime最小值,但是实际上min_vruntime只能单调递增,
所以,如果当前进程vruntime比min_vruntime小,是不会更新min_vruntime的。
那么min_vruntime的作用的是什么呢?试想一下如果一个进程睡眠了很长时间,则它的vruntime非常小,
一旦它被唤醒,将持续占用CPU,很容易引发进程饥饿。
CFS调度器会根据min_vruntime设置一个合适的vruntime值给被唤醒的进程,
既要保证它能优先被调度,又要保证其他进程也能得到合理调度。
*/
cfs_rq->min_vruntime =
max_vruntime(cfs_rq->min_vruntime, vruntime);
}
该函数的功能如下:
- 更新进程调度实体的总实际运行时间。
- 根据进程调度实体的权重值,计算其虚拟运行时间。
- 把计算虚拟运行时间的结果添加到进程调度实体的 vruntime 字段。
将调度实体加入红黑树中
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
struct rb_node **link = &cfs_rq->tasks_timeline.rb_node; // 红黑树根节点
struct rb_node *parent = NULL;
struct sched_entity *entry;
s64 key = entity_key(cfs_rq, se);// 当前进程调度实体的虚拟运行时间
int leftmost = 1;
/*
• Find the right place in the rbtree:
*/
while (*link) { // 把当前调度实体插入到运行队列的红黑树中
parent = *link;
entry = rb_entry(parent, struct sched_entity, run_node);
/*
• We dont care about collisions. Nodes with
• the same key stay together.
*/
if (key < entity_key(cfs_rq, entry)) { // 比较虚拟运行时间
link = &parent->rb_left;
} else {
link = &parent->rb_right;
leftmost = 0;
}
}
/*
• Maintain a cache of leftmost tree entries (it is frequently
• used):
*/
if (leftmost) //缓存最左叶子节点
cfs_rq->rb_leftmost = &se->run_node;
rb_link_node(&se->run_node, parent, link);
//把节点插入到红黑树中
rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
}
__enqueue_entity() 函数的主要工作如下:
- 获取运行队列红黑树的根节点。
- 获取当前进程调度实体的虚拟运行时间。
- 把当前进程调度实体添加到红黑树中。
- 缓存红黑树最左端节点。
- 对红黑树进行平衡操作。
获取下一个合适的调度实体
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev)
{
const struct sched_class *class;
struct task_struct *p;
/*
• Optimization: we know that if all tasks are in
• the fair class we can call that function directly:
*/
/选择时并不是想象中的直接按照调度器的优先级对所有调度器类进行遍历,而是假设下一个运行的进程属于 cfs 调度器类,毕竟,系统中绝大多数的进程都是由 cfs 调度器进行管理,这样做可以从整体上提高执行效率./
if (likely(rq->nr_running == rq->cfs.nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
class = sched_class_highest; // #define sched_class_highest (&rt_sched_class)
for ( ; ; ) {
p = class->pick_next_task(rq);
if (p)
return p;
/*
• Will never be NULL as the idle class always
• returns a non-NULL p:
*/
class = class->next;
}
}
在 pick_next_task 中会遍历所有的调度类,然后从就绪队列中选取一个最合适的调度实体进行调度。
对于完全公平调度算法(CFS),会调用fair_sched_class.pick_next_task() 函数,从 fair_sched_class 中可知,也即是调用 pick_next_task_fair。
static const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
#ifdef CONFIG_SMP
.load_balance = load_balance_fair,
.move_one_task = move_one_task_fair,
#endif
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_new = task_new_fair,
};pick_next_task_fair 调用过程如下:
pick_next_task_fair
---> pick_next_entity
---> __pick_next_entity 从就绪队列中选取一个最合适的调度实体(虚拟时间最小的调度实体)
---> set_next_entity 把选中的进程从红黑树中移除,并更新红黑树
从 schedule 调用可知,其在选择下一个运行任务前,先计算当前进程(待切换出去的进程)的时间运行时间,然后根据实际运行时间计算虚拟运行时间,在根据虚拟运行时间把当前进程加入到就绪队列中的红黑树中等待下一次调度。
其次,从就绪队列的红黑树中选择虚拟运行时间最小的任务作为即将运行的任务。
进程唤醒
进程的默认唤醒函数是 try_to_wake_up(), 该函数主要是调整睡眠进程的 vruntime值, 以及把睡眠进程加入红黑树中, 并判断是否可以发生抢占。
调用关系如下:
try_to_wake_up
--> activate_task
--> enqueue_task
--> check_preempt_curr
时钟周期中断
周期性调度器是基于 scheduler_tick 函数实现。系统都是以tick(节拍)来执行各种调度与统计,节拍可以通过 CONFIG_HZ 宏来控制。内核会以 1/HZ ms 为周期来执行周期性调度,这也是 CFS 实现的关键。CFS调度类会根据这个节拍来对所有进程进行记账。每个 CPU 都会拥有自己的周期性调度器。周期性调度器可以把当前进程设置为 need resched 状态,等待合适的时机当前的进程就会被重新调度。
时钟周期中断函数的调用过程:
tick_periodic
--> update_process_times
--> scheduler_tick
--> task_tick_fair
-->entity_tick
--> update_curr
--> check_preempt_tick
在 CFS 中,scheduler_tick 会调用 具体实现 task_tick_fair,在task_tick_fair 中会从当前进程开始获取每个调度实体,对每个调度实体进行调用 entity_tick,在 entity_tick 中更新调度实体的实际运行时间和虚拟运行时间,同时检查是否需要重新调度。
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
// ideal_runtime 为一个调度周期内理想的运行时间,也即是为 调度周期 * 进程权重 / 所有进程权重之和
ideal_runtime = sched_slice(cfs_rq, curr);
// sum_exec_runtime 指进程总共执行的实际时间;
// prev_sum_exec_runtime 指上次该进程被调度时已经占用的实际时间。
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
// delta_exec 这次调度占用实际时间,如果大于 ideal_runtime,则应该被抢占了
if (delta_exec > ideal_runtime)
resched_task(rq_of(cfs_rq)->curr);
}
若当前进程运行的时间超过时间限制,
则把当前进程设置为 被抢占重新调度标记 TIF_NEED_RESCHED,待一定时机后会根据 TIF_NEED_RESCHED 标记调用 schedule() 进行调度切换。关于“一定的时机”,后续文章进行分析。































