译者 | 崔皓
审校 | 孙淑娟
摘要
本文介绍什么是重采样以及如何使用重采样技术提高模型的整体性能。
在使用数据模型时,由于模型的算法不同而导致接受数据时有不同的学习模式。通过这种直观的学习方式,让模型通过给定数据集的学习从而找出其中的规律,这个过程称为训练模型。
然后,将训练完毕的模型在测试数据集上测试,这些测试数据是模型之前没有见过的。实际上,我们希望达到的最佳效果是模型在训练和测试数据集上都能产生准确的输出,也就是模型在训练集和测试集上的表现一致。
你可能也听说过验证集的方式。这种方式是将数据集分成两部分:训练数据集和测试数据集。一部分的数据被用来训练模型,而另一部分的数据被用来测试训练好的模型。
然而,这种验证集的方法有缺点。
该模型将学习训练数据集中的所有模式,由于它从来没有接触过测试集的数据,因此它可能遗漏测试数据集中的相关信息。这导致模型失去了提高整体性能的重要信息。
另一个缺点是,训练数据集可能面临数据中的异常值或错误,而模型将学习这些有问题的数据,并将这些数据作为模型知识库的一部分,然后在第二阶段的测试中应用。
那么,我们如何纠正上述的缺点呢?答案是:重新采样。
什么是重采样?
重采样是一种方法,包括从训练数据集中反复抽取样本。然后,这些样本被用来重新拟合一个特定的模型,以检索更多关于拟合模型的信息。其目的是收集更多关于样本的信息,提高准确性并估计不确定性。
例如,如果你正在研究线性回归拟合,并想检查变异性。就可以重复使用训练数据中的不同样本,并对每个样本进行线性回归拟合。这将使你能够检查结果在不同样本上的不同表现,从而获得新的信息。
重新取样的显著优势是,你可以从同一群体中反复抽取小样本,直到你的模型达到最佳性能。由于能够循环使用同一个数据集,你将节省大量的时间和金钱,而不必去寻找新的数据。
欠采样和过度采样
如果你正在处理高度不平衡的数据集,重采样是可以提升模型准确率的一种技术。
欠采样是指从多数类中移除样本,以提供更多的平衡。
过度采样是指由于收集的数据不足,从少数类别中复制随机样本并充当样本。
然而,上述的两种方法都存在劣势,在取样不足的情况下删除样本会导致信息的损失。从少数类中重复随机样本会导致过度拟合。
数据科学中经常使用两种重抽样方法:
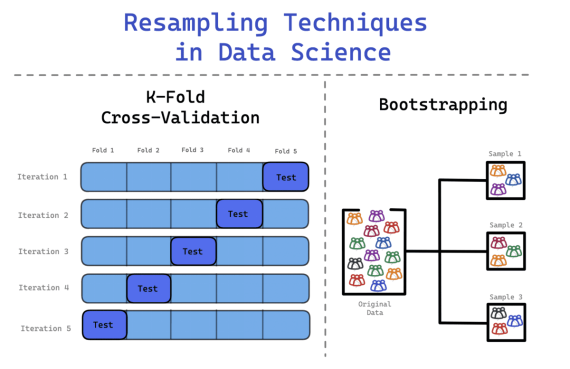
- Bootstrap法(引导法)
- 交叉验证法
Bootstrap法
这种方法用在一些不遵循典型正态分布的数据集。因此,可以应用Bootstrap方法来检查数据集的隐藏信息和分布。
在使用Bootstrap方法时,抽出的样本会被替换,而不包括在样本中的数据被用来测试模型。它是一种灵活的统计方法,可以帮助数据科学家和机器学习工程师量化不确定性。
其过程包括如下:
1. 反复从数据集中抽取样本观测值
2. 替换这些样本,以确保原始数据集保持在相同的规模。
3. 一个观察值可以出现不止一次,也可以完全不出现。
你可能听说过Bagging,即合集技术。它是Bootstrap Aggregation的简称,它结合了Bootstrap和聚合来形成一个集合模型。它创建了多个原始训练数据集,然后汇总得出最终的预测结果。每个模型都会学习前一个模型的错误。
引导法的一个优点是,与上面提到的训练-测试分割法相比,它们的方差较低。
交叉验证法
当你重复地随机分割数据集时,会导致样本最终进入训练集或测试集。这可能会不幸地对你的模型产生不平衡的影响,使其无法做出准确的预测。
为了避免这种情况,你可以使用K-Fold交叉验证法来更有效地分割数据。在这个过程中,数据被分为k个相等的集合,其中一个集合被定义为测试集,而其余的集合则用于训练模型。这个过程将一直持续到每个集合都作为测试集,并且所有的集合都经过了训练阶段。
其个过程包括:
1. 数据被分割成k个部分。例如,一个数据集被分成10个部分--10个相等的集合。
2. 在第一次迭代中,模型在(k-1)上进行训练,并在剩余的一组上进行测试。假设每个数据集合都有编号,第一次训练把1-9号数据集合作为训练集,把10号集合作为测试集。第二训练把1-8号集合以及10号集合作为测试集,把9号集合作为测试集。第三次把1-7号集合以及9、10号集合作为训练集合,把8号集合作为测试集合。
3. 这个过程不断重复(10次),直到所有的集合都作为测试集合进行训练为止。
这使每个样本有平衡的代表性,确保所有的数据都被用来改善模型的学习,以及测试模型的性能。
总结
在这篇文章中,你将了解什么是重采样,以及如何以3种不同的方式对你的数据集进行采样:训练-测试分割、bootstrap和交叉验证。
所有这些方法的目标是帮助模型以有效的方式吸收尽可能多的信息。确保模型成功学习的唯一方法是在数据集中的各种数据点上训练模型。
重新采样是预测性建模阶段的一个重要元素;确保准确的输出、创建高性能的模型和有效的工作流程。
译者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:The Role of Resampling Techniques in Data Science,作者:Nisha Arya