本文为来自 字节跳动-国际化电商-S 项目团队 成员的文章,已授权 ELab 发布。
一个 TCP 连接的案例TCP 服务端const net = require('net');
const server = new net.Server();
server.listen(9999, '127.0.0.1', () => {
console.log(`server is listening on ${server.address().address}:${server.address().port}`);
});
server.on('connection', (socket) => {
server.getConnections((err, connections) => {
console.log('current clients is: ', connections);
});
socket.on('data', (data) => {
console.log(`received data: ${data.toString()}`);
});
});const net = require('net');
const client = new net.Socket();
client.connect({
port: 9999,
address: '127.0.0.1',
});
client.on('connect', () => {
console.log('connect success');
client.write(`Hello Server!, I'm ${Math.round(Math.random() * 100)}`);
});疑问❓
NodeJS 代码是如何跑起来的
TCP 连接在 NodeJS 中是如何保持一直监听而进程不中断的
NodeJS 是如何处理并发连接的,当遇到阻塞型调用时如何不阻塞主线程的
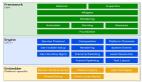
核心架构
NodeJS 架构

NodeJS 源码分为三层:JS、C++ 以及 C。
JS 层
JS 层提供面向用户的调用底层能力的接口,即各种 NodeJS 原生模块,如 net、http、fs、DNS 以及 path 等
C++ 层
C++ 层主要通过 V8 为 JS 层提供与底层交互的能力,起到类似桥梁的作用,通过 V8 不仅实现 JS 的解释执行,还扩展的 JS 的能力边界
C 层
C 层主要包括 Libuv 这一跨平台的异步 IO 库以及其他第三方 C 库
启动过程

image.png
分析
注册 C++ 模块
RegisterBuiltinModules 函数的作用是注册一系列 C++ 模块,通过宏定义展开,最终变成如下逻辑:
void RegisterBuiltinModules() {
_register_async_wrap();
_register_buffer();
_register_fs();
_register_url();
// ...
}通过注册函数,将各个 C++ 模块维护在 modlist_internal 这一链表中,后续在原生 JS 模块中调用 C++ 模块时就可以根据模块名找到对应的模块。
创建 Environment 对象
Environment 在 NodeJS 中是一个运行时的环境对象,很多全局变量都托管在该类上,创建完 environment 后,就将其和 Context 进行绑定,后续 V8 可通过 context 获取 env 对象。
下面简单介绍一下 V8 的 isolate 、 context、scope、handle 等对象。
isolate 是一个独立隔离实例的环境,同一时刻只能被一个线程进入;
context 可以理解为执行上下文对象,可以导入不同的环境变量和函数;
Scope 指的是作用域,可看成是句柄的容器,一个作用域里面可以有很多个句柄;
HandleScope 是用来管理 Handle 的,而 Context::Scope 仅仅用来管理 Context 对象。
Handle 是 V8 引用对象的技术手段,Handle 分为 Local 和 Persistent 两种。Local 是局部的,它同时被 HandleScope 进行管理。 persistent,类似于全局的,不受 HandleScope 的管理,其作用域可以延伸到不同的函数。

初始化 loader 和执行上下文
RunBootstrapping 主要调用了 BootstrapInternalLoaders 和 BootstrapNode 函数。
BootstrapInternalLoaders 用于编译执行 /lib/internal/bootstrap/loader.js,它的具体逻辑是为了NodeJS 能在JS层 通过 binding 函数加载C++模块,以便在原生 JS 模块中调用 C++ 模块。
BootstrapNode 用于初始化执行上下文,暴露 global 对象在全局上下文中,编译执行 /lib/internal/bootstrap/node,从而设置一些全局变量或方法到 global 或者 process
// lib/internal/bootstrap/node.js
// proces 挂载一系列属性方法
{
process.dlopen = rawMethods.dlopen;
process.uptime = rawMethods.uptime;
// TODO(joyeecheung): either remove them or make them public
process._getActiveRequests = rawMethods._getActiveRequests;
process._getActiveHandles = rawMethods._getActiveHandles;
// TODO(joyeecheung): remove these
process.reallyExit = rawMethods.reallyExit;
process._kill = rawMethods._kill;
const wrapped = perThreadSetup.wrapProcessMethods(rawMethods);
process._rawDebug = wrapped._rawDebug;
process.hrtime = wrapped.hrtime;
process.hrtime.bigint = wrapped.hrtimeBigInt;
process.cpuUsage = wrapped.cpuUsage;
process.resourceUsage = wrapped.resourceUsage;
process.memoryUsage = wrapped.memoryUsage;
process.kill = wrapped.kill;
process.exit = wrapped.exit;
process.openStdin = function() {
process.stdin.resume();
return process.stdin;
};
}
// global 挂载一系列属性和方法
if (!config.noBrowserGlobals) {
// Override global console from the one provided by the VM
// to the one implemented by Node.js
// https://console.spec.whatwg.org/#console-namespace
exposeNamespace(global, 'console', createGlobalConsole(global.console));
const { URL, URLSearchParams } = require('internal/url');
// https://url.spec.whatwg.org/#url
exposeInterface(global, 'URL', URL);
// https://url.spec.whatwg.org/#urlsearchparams
exposeInterface(global, 'URLSearchParams', URLSearchParams);
const {
TextEncoder, TextDecoder
} = require('internal/encoding');
// https://encoding.spec.whatwg.org/#textencoder
exposeInterface(global, 'TextEncoder', TextEncoder);
// https://encoding.spec.whatwg.org/#textdecoder
exposeInterface(global, 'TextDecoder', TextDecoder);
// https://html.spec.whatwg.org/multipage/webappapis.html#windoworworkerglobalscope
const timers = require('timers');
defineOperation(global, 'clearInterval', timers.clearInterval);
defineOperation(global, 'clearTimeout', timers.clearTimeout);
defineOperation(global, 'setInterval', timers.setInterval);
defineOperation(global, 'setTimeout', timers.setTimeout);
defineOperation(global, 'queueMicrotask', queueMicrotask);
// Non-standard extensions:
defineOperation(global, 'clearImmediate', timers.clearImmediate);
defineOperation(global, 'setImmediate', timers.setImmediate);
}
// ...
初始化 Libuv
这里对事件循环的部分阶段做一些初始化的操作,创建一个默认的 event_loop 结构体用于管理后续各个阶段产生的任务
void Environment::InitializeLibuv(bool start_profiler_idle_notifier) {
HandleScope handle_scope(isolate());
Context::Scope context_scope(context());
CHECK_EQ(0, uv_timer_init(event_loop(), timer_handle()));
uv_unref(reinterpret_cast<uv_handle_t*>(timer_handle()));
uv_check_init(event_loop(), immediate_check_handle());
uv_unref(reinterpret_cast<uv_handle_t*>(immediate_check_handle()));
uv_idle_init(event_loop(), immediate_idle_handle());
uv_check_start(immediate_check_handle(), CheckImmediate);
uv_prepare_init(event_loop(), &idle_prepare_handle_);
uv_check_init(event_loop(), &idle_check_handle_);
uv_async_init(
event_loop(),
&task_queues_async_,
[](uv_async_t* async) {
Environment* env = ContainerOf(
&Environment::task_queues_async_, async);
env->CleanupFinalizationGroups();
env->RunAndClearNativeImmediates();
});
uv_unref(reinterpret_cast<uv_handle_t*>(&idle_prepare_handle_));
uv_unref(reinterpret_cast<uv_handle_t*>(&idle_check_handle_));
uv_unref(reinterpret_cast<uv_handle_t*>(&task_queues_async_));
// ...
}执行用户 JS 代码
StartExecution 用于加载用户 JS 代码并执行
// src/node.cc
MaybeLocal<Value> StartExecution(Environment* env, StartExecutionCallback cb) {
// ...
if (!first_argv.empty() && first_argv != "-") {
return StartExecution(env, "internal/main/run_main_module");
}
// ...
}
// lib/internal/main/run_main_module.js
require('internal/modules/cjs/loader').Module.runMain(process.argv[1]);
进入 Libuv 事件循环
执行完用户 JS 代码,用户代码就会往 Libuv 中注册一些任务,然后进入整个事件循环,直到没有待处理的任务,Libuv 则会退出事件循环,进而退出 NodeJS 进程。
// src/node_main_instance.cc
do {
uv_run(env->event_loop(), UV_RUN_DEFAULT);
per_process::v8_platform.DrainVMTasks(isolate_);
more = uv_loop_alive(env->event_loop());
if (more && !env->is_stopping()) continue;
if (!uv_loop_alive(env->event_loop())) {
EmitBeforeExit(env.get());
}
// Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
more = uv_loop_alive(env->event_loop());
} while (more == true && !env->is_stopping());
源代码概览
// src/node_main.cc
int main(int argc, char* argv[]) {
return node::Start(argc, argv);
}
// src/node.cc
namespace node {
int Start(int argc, char** argv) {
InitializationResult result = InitializeOncePerProcess(argc, argv);
// ...
NodeMainInstance main_instance(¶ms,
uv_default_loop(),
per_process::v8_platform.Platform(),
result.args,
result.exec_args,
indexes);
result.exit_code = main_instance.Run();
}
InitializationResult InitializeOncePerProcess(int argc, char** argv) {
// ...
{
result.exit_code =
InitializeNodeWithArgs(&(result.args), &(result.exec_args), &errors);
//...
}
V8::Initialize();
return result;
}
int InitializeNodeWithArgs(std::vector<std::string>* argv,
std::vector<std::string>* exec_argv,
std::vector<std::string>* errors) {
// ...
// Register built-in modules
binding::RegisterBuiltinModules();
// ...
}
MaybeLocal<Value> Environment::RunBootstrapping() {
EscapableHandleScope scope(isolate_);
//...
if (BootstrapInternalLoaders().IsEmpty()) {
return MaybeLocal<Value>();
}
Local<Value> result;
if (!BootstrapNode().ToLocal(&result)) {
return MaybeLocal<Value>();
}
//...
return scope.Escape(result);
}
}
// src/node_main_instance.cc
namespace node {
int NodeMainInstance::Run() {
// ...
DeleteFnPtr<Environment, FreeEnvironment> env =
CreateMainEnvironment(&exit_code);
if (exit_code == 0) {
LoadEnvironment(env.get());
// ...
{
// ...
do {
uv_run(env->event_loop(), UV_RUN_DEFAULT);
per_process::v8_platform.DrainVMTasks(isolate_);
more = uv_loop_alive(env->event_loop());
if (more && !env->is_stopping()) continue;
if (!uv_loop_alive(env->event_loop())) {
EmitBeforeExit(env.get());
}
// Emit `beforeExit` if the loop became alive either after emitting
// event, or after running some callbacks.
more = uv_loop_alive(env->event_loop());
} while (more == true && !env->is_stopping());
}
}
// ...
}
NodeMainInstance::CreateMainEnvironment(int* exit_code) {
// ...
context = NewContext(isolate_);
Context::Scope context_scope(context);
DeleteFnPtr<Environment, FreeEnvironment> env { CreateEnvironment(
isolate_data_.get(),
context,
args_,
exec_args_,
EnvironmentFlags::kDefaultFlags) };
return env;
}
}
// src/environment.cc
namespace node {
void LoadEnvironment(Environment* env) {
USE(LoadEnvironment(env,
StartExecutionCallback{},
{}));
}
MaybeLocal<Value> LoadEnvironment(
Environment* env,
StartExecutionCallback cb,
std::unique_ptr<InspectorParentHandle> removeme) {
env->InitializeLibuv(per_process::v8_is_profiling);
env->InitializeDiagnostics();
return StartExecution(env, cb);
}
Environment* CreateEnvironment(IsolateData* isolate_data,
Local<Context> context,
int argc,
const char* const* argv,
int exec_argc,
const char* const* exec_argv) {
return CreateEnvironment(
isolate_data, context,
std::vector<std::string>(argv, argv + argc),
std::vector<std::string>(exec_argv, exec_argv + exec_argc));
}
Environment* CreateEnvironment(
IsolateData* isolate_data,
Local<Context> context,
const std::vector<std::string>& args,
const std::vector<std::string>& exec_args,
EnvironmentFlags::Flags flags,
ThreadId thread_id,
std::unique_ptr<InspectorParentHandle> inspector_parent_handle) {
Isolate* isolate = context->GetIsolate();
HandleScope handle_scope(isolate);
Context::Scope context_scope(context);
// TODO(addaleax): This is a much better place for parsing per-Environment
// options than the global parse call.
Environment* env = new Environment(
isolate_data,
context,
args,
exec_args,
flags,
thread_id);
// ...
if (env->RunBootstrapping().IsEmpty()) {
FreeEnvironment(env);
return nullptr;
}
return env;
}
}
Libuv 架构
Libuv 是 NodeJS 的核心组件,是一个跨平台的处理异步 I/O 请求的 C 库,从架构来看,它把各类请求主要分为两大类:网络 I/O 相关请求,以及文件 I/O、DNS Ops 以及 User code 组成的请求。
对于网络 I/O 相关请求,根据 OS 平台的不同,分别采用了 Linux 的 epoll、OSX 和 BSD 类 OS 的 kqueue、SunOS 的 event ports 以及 Windows 的 IOCP 等 I/O 读写机制。
对于 File I/O 为代表的请求,则使用线程池实现异步请求处理,具有更好的跨平台特性。
事件循环 event loop
在 Node 应用启动后,就会进入 Libuv 事件循环中,每一轮循环 Libuv 都会处理维护在各个阶段的任务队列的回调节点,在回调节点中可能会产生新的任务,任务可能在当前循环或是下个循环继续被处理。
以下是 Libuv 的执行流程图:
下面简述一下各个阶段代表的含义:
- 首先判断当前事件循环是否处于 alive 状态,否则退出整个事件循环。alive 状态表示是否有 active 状态的 handle 和 request,closing 状态的 handle
- 基于系统时间更新时间戳
- 判断由定时器组成的小顶堆中那个节点超时,超时则执行定时器回调
- 执行 pending 回调任务,一般 I/O 回调添加的错误或写数据成功的任务都会在下一个事件循环的 pending 阶段执行
- 执行 idle 阶段的回调任务
- 执行 prepare 阶段的回调任务
- 调用各平台的 I/O 读写接口,最多等待 timeout 时间(定时器最快过期时间),期间如果有数据返回,则执行 I/O 对应的回调
- 执行 check 阶段的回调任务
- 执行 closing 阶段的回调任务
- 重新回到流程 1
源码概览
// src/unix/core.c
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
int timeout;
int r;
int can_sleep;
r = uv__loop_alive(loop);
if (!r)
uv__update_time(loop);
while (r != 0 && loop->stop_flag == 0) {
uv__update_time(loop);
uv__run_timers(loop);
can_sleep =
QUEUE_EMPTY(&loop->pending_queue) && QUEUE_EMPTY(&loop->idle_handles);
uv__run_pending(loop);
uv__run_idle(loop);
uv__run_prepare(loop);
timeout = 0;
if ((mode == UV_RUN_ONCE && can_sleep) || mode == UV_RUN_DEFAULT)
timeout = uv__backend_timeout(loop);
uv__metrics_inc_loop_count(loop);
// 动态设置 epoll_wait 的超时时间
uv__io_poll(loop, timeout);
for (r = 0; r < 8 && !QUEUE_EMPTY(&loop->pending_queue); r++)
uv__run_pending(loop);
uv__metrics_update_idle_time(loop);
uv__run_check(loop);
uv__run_closing_handles(loop);
if (mode == UV_RUN_ONCE) {
uv__update_time(loop);
uv__run_timers(loop);
}
r = uv__loop_alive(loop);
if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT)
break;
}
/* The if statement lets gcc compile it to a conditional store. Avoids
* dirtying a cache line.
*/
if (loop->stop_flag != 0)
loop->stop_flag = 0;
return r;
}
任务调度
了解了 Libuv 的事件循环流程,接下来结合 JS 代码具体看看 NodeJS 是如何进行任务调度的。
image.png
目前,主要有五种主要类型的队列被 Libuv 的事件循环所处理:
- 过期或是定期的时间队列,由 setTimeout 或 setInterval 函数所添加的任务
- Pending 队列,主要存放读写成功或是错误的回调
- I/O 事件队列,主要存放完成 I/O 事件时的回调
- Immediates 队列,采用 setImmediate 函数添加的任务,对应 libuv 的 check 阶段
- Close 任务队列,主要存放 close 事件回调
除了以上五种主要的任务列表,还有额外两种不属于 libuv 而是作为 NodeJS 一部分的任务队列:
- Next Ticks 队列,采用 process.nextTick 添加的任务
- 其他微任务队列,例如 promise callback 等
nextTicks 队列和其他微任务队列会在事件循环每一阶段穿插调用,nextTicks 优先级会比其他微任务队列更高。
示例
// timer -> pending -> idle -> prepare -> poll io -> check -> close
// timer phase
setTimeout(() => {
Promise.resolve().then(() => {
console.log('promise resolve in timeout');
process.nextTick(() => {
console.log('tick task in timeout promise');
});
})
process.nextTick(() => {
console.log('tick task in timeout');
process.nextTick(() => {
console.log("tick task in timeout->tick");
})
});
console.log('timer task');
}, 0);
// check phase
setImmediate(() => {
process.nextTick(() => {
console.log('imeediate->tick task')
});
console.log('immediate task');
});
Promise.resolve().then(() => {
console.log('promise resolve');
});
process.nextTick(() => {
console.log("tick task");
});
console.log('run main thread');
// result
run main thread
tick task
promise resolve
timer task
tick task in timeout
tick task in timeout->tick
promise resolve in timeout
tick task in timeout promise
immediate task
imeediate->tick task
现在解读一下以上的执行流程:
NodeJS 在经过一系列初始化工作后,开始执行用户 JS 代码,解释执行过程中,分别把 setTimeout、setImmediate、Promise、nextTick 函数的回调插入 timer、immediate、microtask 和 nexttick 队列。
- 执行主线程 console.log("run main thread"),打印 "run main thread"
- 进入 timer 阶段前,发现 nextTick 、promise 队列有任务如下:
nextTicks = [() => {
console.log("tick task");
}];
microtasks = [() => {
console.log('promise resolve');
}];分别打印 "tick task" 以及 "promise resolve"
- 进入 timer 阶段,执行定时器回调,定时器回调中再次往 microtask 和 nextTick 插入新的任务如下:
nextTicks = [() => {
console.log('tick task in timeout');
process.nextTick(() => {
console.log("tick task in timeout->tick");
})
}];
microtasks = [() => {
console.log('promise resolve in timeout');
process.nextTick(() => {
console.log('tick task in timeout promise');
});
}];打印主线程任务中的 "timer task",再进入下一阶段,发现 nextTicks 和 microtasks 队列为非空,执行微任务。由于 nextTicks 优先级更高,先打印 "tick task in timeout",然后又往 nextTicks 插入 () => {console.log("tick task in timeout->tick")} ,继续执行 nextTicks 任务打印 "tick task in timeout->tick"。
此时 nextTicks 队列已空,执行 miacrotasks 队列,打印 "promise resolve in timeout",此时又往 nextTicks 插入任务 () => {console.log('tick task in timeout promise')},继续执行 nextTick 任务,打印 "tick task in timeout promise"。
进入 check 阶段(Immediate),为 nextTicks 添加 () => {console.log('imeediate->tick task') },主线程打印 "immediate task",进入下一阶段前先执行 nextTicks 任务,打印 'imeediate->tick task'。
拓展
setImmediate(() => console.log('this is set immediate 1'));
setImmediate(() => console.log('this is set immediate 2'));
setImmediate(() => console.log('this is set immediate 3'));
setTimeout(() => console.log('this is set timeout 1'), 0);
setTimeout(() => {
console.log('this is set timeout 2');
process.nextTick(() => console.log('this is process.nextTick added inside setTimeout'));
}, 0);
setTimeout(() => console.log('this is set timeout 3'), 0);
setTimeout(() => console.log('this is set timeout 4'), 0);
setTimeout(() => console.log('this is set timeout 5'), 0);
process.nextTick(() => console.log('this is process.nextTick 1'));
process.nextTick(() => {
process.nextTick(console.log.bind(console, 'this is the inner next tick inside next tick'));
});
process.nextTick(() => console.log('this is process.nextTick 2'));
process.nextTick(() => console.log('this is process.nextTick 3'));
process.nextTick(() => console.log('this is process.nextTick 4'));I/O 模型
得益于 Libuv 这一跨平台的高性能异步 I/O 库,使得 NodeJS 在处理 I/O 密集型任务上十分彰显优势。下面结合不同的 I/O 模型,对比分析一下 NodeJS 目前工程实践所采用的 I/O 模型的优越性。
首先理清一下阻塞和非阻塞、异步和同步的概念:
在应用程序通过 I/O 函数申请读写数据时,如果在数据就绪前进程一直在等待的,就是阻塞 I/O,即发起 I/O 请求时是阻塞的
数据从内核缓冲区到到用户内存复制过程中,需要用户进程等待,就是同步 I/O,即实际的 I/O 读写是同步的
同步阻塞
图片来源:https://www.51cto.com/article/693213.html
在网络编程中,当调用 recvfrom 获取客户端数据时,首先会阻塞进程,等待数据通过网卡到内核缓冲区;当数据就绪后,再同步等待指代数据从内核缓冲区拷贝到用户空间,此时用户进程再进行数据处理。
同步阻塞 I/O 模型是最简单的 I/O 模型,好处是使用简单,通常在 fd 较少、数据就绪很快的场景,缺点是如果内核数据一直没准备好,则用户进程将会一直阻塞无法执行后续任务。
以网络编程为例,默认情况下socket 是 blocking 的,即函数 accept , recvfrom 等,需等待函数执行结束之后才能够返回(此时操作系统切换到其他进程执行)。accpet 等待到有 client 连接请求并接受成功之后,recvfrom 需要读取完client 发送的数据之后才能够返回
// 创建套接字
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// IP 和端口配置 ...
// ...
// 绑定 IP 和端口
bind(serv_sock, ...);
// 监听来自监听型套接字的请求
listen(serv_sock, ...);
int clnt_sock;
while (1) {
// 创建新的通信型套接字用于接收来自客户端的请求,此时会阻塞程序执行,直到有请求到来
clnt_sock = accept(serv_sock, ...);
// 接收客户端的数据,同步阻塞 I/O,等待数据就绪
recvfrom(clnt_sock, ...);
// 处理数据
handle(data);
}
同步非阻塞
图片来源:https://www.51cto.com/article/693213.html
同步非阻塞 I/O 的特点是当用户进程发起网络读请求时,如果内核缓冲区还没接收到客户端数据,会立即返回 EWOULDBLOCK 错误码,而不会阻塞用户进程,用户进程可结合轮询调用方式继续发起 recvfrom 调用,直到数据就绪,然后同步等待数据从内核缓冲区复制到用户空间,然后用户进程进行数据处理。
同步非阻塞 I/O 的优势在于当发起 I/O 请求时不会阻塞用户进程,一定程度上提升了程序的性能,但是为了及时获取数据的就绪状态,需要频繁轮询,这样也会消耗不小的 CPU 资源。
以网络编程为例,可设置 socket 为 non-blocking 模式,使用 socket()创建的 socket 默认是阻塞的;可使用函数 fcntl 可设置创建的 socket 为非阻塞的,这样使用原本 blocking 的各种函数(accept、recvfrom),可以立即获得返回结果。通过判断返回的errno了解状态:
这样就实现同步非阻塞 I/O 请求:
// 创建套接字
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// 设置 socket 为非阻塞 I/O
int flags = fcntl(serv_sock, F_GETFL, 0);
fcntl(serv_sock, F_SETFL, flags | O_NONBLOCK);
// IP 和端口配置 ...
// ...
// 绑定 IP 和端口
bind(serv_sock, ...);
// 监听来自监听型套接字的请求
listen(serv_sock, ...);
// 创建新的通信型套接字用于接收来自客户端的请求
int clnt_sock;
while (1) {
// 在non-blocking模式下,如果返回值为-1,且 errno == EAGAIN 或errno == EWOULDBLOCK 表示no connections 没有新连接请求;
clnt_sock = accept(serv_sock, ...);
if (clnt_sock == -1 && errno == EAGAIN) {
fprintf(stderr, "no client connections\n");
continue;
} else if (clnt_sock == -1) {
perror("accept failed");
}
// 接收客户端的数据,同步非阻塞 I/O,在non-blocking模式下,如果返回值为-1,且 errno == EAGAIN表示没有可接受的数据或正在接受尚未完成;
while (1) {
int ret = recvfrom(clnt_sock, ...);
if (ret == -1 && errno == EAGAIN) {
fprintf(stderr, "no data ready\n");
continue;
} else if (ret == -1) {
perror("read failed");
}
// 处理数据
handle(data);
}
}
I/O 多路复用
图片来源:https://www.51cto.com/article/693213.html
上述两种 I/O 模型均是面向单个客户端连接的,同一时间只能处理一个 client 请求,虽然可以通过多进程/多线程的方法解决,但是多进程/多线程需要考虑额外的资源消耗以及同步互斥的相关问题。
为了高效解决多个 fd 的状态监听,I/O 多路复用技术应运而生。
I/O 多路复用的核心思想是可以同时监听多个不同的 fd(网络环境下即是网络套接字),当套接字中的任何一个数据就绪了,就可以通知用户进程,此时用户进程再发起 recvfrom 请求去读取数据。
以网络编程为例,可通过维护一个需要监听的所有 socket 的 fd 列表,然后调用 select/epoll 等监听函数,如果 fd 列表中所有 socket 都没有数据就绪,则 select/epoll 会阻塞,直到有一个 socket 接收到数据,然后唤醒进程。
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// 设置 socket 为非阻塞 I/O
int flags = fcntl(serv_sock, F_GETFL, 0);
fcntl(serv_sock, F_SETFL, flags | O_NONBLOCK);
// IP 和端口配置 ...
// ...
// 绑定 IP 和端口
bind(serv_sock, ...);
// 监听来自监听型套接字的请求
listen(serv_sock, ...);
// 存放需要监听的 socket 列表
fd_set readfds;
// 添加 需要监听的 socket 到 readfds
FD_SET(serv_sock, readfds);
// 创建新的通信型套接字用于接收来自客户端的请求
int clnt_sock;
// 调用 select 返回的结果值
int res;
// 预计可接受的最大连接数量,select 最大支持 1024 个 fd
int maxfd = 1000;
while (1) {
// 调用 select 阻塞监听 fd 列表,直到有一个 socket 接收到请求,唤醒进程
res = select(maxfd + 1, &readfds, ...);
if (res == -1) {
perror("select failed");
exit(EXIT_FAILURE);
} else if (res == 0) {
fprintf(stderr, "no socket ready for read\n");
}
// 遍历每个 socket,如果是 serv_sock 则 accept,否则进行读操作
for (int i = 0; i <= maxfd; i++) {
// 是否 socket 是否在 监听的 fd 列表中
if (!FD_ISSET(i, &readfds)) {
continue;
}
if (i == serv_sock) {
// 当前请求是 server sock,则建立 accept 连接
clnt_sock = accpet(serv_sock, ...);
// 将新建立的客户端连接添加进行 readfds 监听列表中
FD_SET(clnt_sock, &readfds);
} else {
// 当请求是客户端的 socket,接收客户端的数据,此时数据已经就绪,将数据从内核空间复制到用户空间
int ret = recvfrom(i, ...);
if (ret == -1 && errno == EAGAIN) {
fprintf(stderr, "no data ready\n");
continue;
} else if (ret == -1) {
perror("read failed");
}
// 处理数据
handle(data);
}
}
}
上面是使用 select 函数实现的 I/O 多路复用,实际在 Libuv 采用的是 epoll 函数,epoll 函数是为了解决 select 的以下缺点而诞生的:
- 监听的 I/O 最大连接数量有限,Libux 系统下一般为 1024
- 一方面,监听的 fd 列表需要从用户空间传递到内核空间进行 socket 列表的监听;另一方面,当数据就绪后,又需要从内核空间复制到用户空间,随着监听的 fd 数量增长,效率也会下降。
- 此外,select 函数返回后,每次都需要遍历一遍监听的 fd 列表,找到数据就绪的 fd。
图片来源:https://www.51cto.com/article/693213.html
epoll 的优势在于:
- 基于事件驱动,每次只返回就绪的 fd,避免所有 fd 的遍历操作
- epoll 的 fd 数量上限是操作系统最大的文件句柄数目,一般与内存相关
- 底层使用红黑树管理监听的 fd 列表,红黑树在增删、查询等操作上时间复杂度均是 logN,效率较高
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// 设置 socket 为非阻塞 I/O
int flags = fcntl(serv_sock, F_GETFL, 0);
fcntl(serv_sock, F_SETFL, flags | O_NONBLOCK);
// IP 和端口配置 ...
// ...
// 绑定 IP 和端口
bind(serv_sock, ...);
// 监听来自监听型套接字的请求
listen(serv_sock, ...);
// 创建 epoll 对象
int MAX_EVENTS = 5; // 告诉内核可能需要监听的 fd 数量,如果使用时大于该数,则内核会申请动态申请工多空间
int epoll_fd = epoll_create(MAX_EVENTS);
if (epoll_fd == -1) {
printf("epoll_create error!\n");
return -1;
}
// 注册 serv_sock 所监听的事件
struct epoll_event ev;
struct epoll_event events[MAX_EVENTS];
ev.data.fd = serv_sock; // 设置该事件的 fd 为 serv_sock
ev.events = EPOLLIN; // 设置监听 serv_sock 的可读事件
// 添加 serv_sock 到 epoll 的可读事件监听队列中
int ret = epoll_ctl(epoll_fd, EPOLL_CTL_ADD, serv_sock, &ev);
if (ret == -1) {
printf("epoll_ctl error!\n");
return -1;
}
int connfd = 0; // 与客户端连接成功后的通信型 fd
while (1) {
// int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
// 等待 epoll_fd 中的事件,如果 serv_sock 有可读事件发生,则函数返回就绪后的 fd 数量
// 最后一个 timeout 参数可用来控制 epoll_wait 的等待事件发生的时间,-1 为阻塞等待,0 为非阻塞立即返回
int nfds = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
for (int i = 0; i < nfds; i++) {
// 客户端发起请求
if (events[i].data.fd == serv_sock) {
connfd = accept(serv_sock, ...);
if (connfd == -1) {
printf("accept error!\n");
}
ev.data.fd = connfd; // 设置该事件的 fd 为当前的 connfd
ev.events = EPOLLIN; // 设置当前的 connfd 的可读事件
// 添加当前 connfd 到 epoll 的可读事件监听队列中
if (epoll_ctl(epoll_fd, EPOLL_CTL_ADD, connfd, &ev) == -1) {
printf("epoll_ctl add error!\n");
return -1;
}
} else {
// 某个来自客户端的请求的数据已就绪
int ret = recvfrom(i, ...);
if (ret == -1 && errno == EAGAIN) {
fprintf(stderr, "no data ready\n");
continue;
} else if (ret == -1) {
perror("read failed");
}
// 处理数据
handle(data);
}
}
}
以上就是基于 epoll 机制的事件驱动型的 I/O 多路复用模型,服务器通过注册文件描述符及其对应监听的事件到 epoll(epoll_ctl),epoll 开始阻塞监听事件直到有某个 fd 的监听事件触发(epoll_wait),然后就遍历就绪事件,根据 fd 类型的不同执行不同的任务。
服务器架构
单进程单线程·串行模型
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// IP 和端口配置 ...
// ...
// 绑定 IP 和端口
bind(serv_sock, ...);
// 监听来自监听型套接字的请求
listen(serv_sock, ...);
int clnt_sock;
while (1) {
// 创建新的通信型套接字用于接收来自客户端的请求,此时会阻塞程序执行,直到有请求到来
clnt_sock = accept(serv_sock, ...);
// 接收客户端的数据,同步阻塞 I/O,等待数据就绪
recvfrom(clnt_sock, ...);
// 处理数据
handle(data);
}
单进程单线程·串行处理请求是最简单的服务器架构,先从经过三次握手,然后从连接队列中获取客户端连接节点(accept 返回的套接字),然后从客户端的套接字获取数据进行处理,接下来再进行下个连接节点处理。
在并发连接数较大的情况下,并且采用的是阻塞式 I/O 模型,那么处理客户端连接的效率就会非常低。
多进程/多线程
单进程串行处理请求因为阻塞 I/O 导致连接队列中的节点被阻塞导致处理效率低下,通过把请求分给多个进程处理从而提升效率,人多力量大。在多进程/多线程架构下,如果一个请求发送阻塞 I/O,那么操作系统会挂起该进程,接着调度其他进程,实现并发处理能力的提高。
但这种架构模式下的性能瓶颈在于系统的进程数、线程数是有限的,开辟进程和线程的开销也是需要考虑的问题,系统资源消耗高。
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
// IP 和端口配置 ...
// ...
// 绑定 IP 和端口
bind(serv_sock, ...);
// 监听来自监听型套接字的请求
listen(serv_sock, ...);
int clnt_sock;
int pid;
while (1) {
// 创建新的通信型套接字用于接收来自客户端的请求,此时会阻塞程序执行,直到有请求到来
clnt_sock = accept(serv_sock, ...);
pid = fork();
if (pid < 0) {
perror("fork failed");
return -1;
}
if (fork() > 0) {
// 父进程
continue;
} else {
// 子进程
// 接收客户端的数据,同步阻塞 I/O,等待数据就绪
recvfrom(clnt_sock, ...);
// 处理数据
handle(data);
}
}
单进程单线程·事件驱动
除了通过多进程/多线程方式去应对并发量大的场景,基于 I/O 多路复用模型的单进程单线程·事件驱动架构也是较好的解决方案,同时由于是单线程,所以不会因开辟大量进场/线程所带来的资源开销以及同步互斥的问题。
单线程不适合执行 CPU 密集型任务,因为如果任务一直占用 CPU 时间,则后续任务无法执行,因此针对大量 CPU 计算、引起进程阻塞的任务,可引入线程池技术去解决。
目前 NodeJS 就是采用这种设计架构,所有 JS 代码跑在主线程中(单线程),基于 I/O 多路复用的模型去实现事件驱动的多读写请求的管理,配合线程池,将 CPU 密集型任务从主线程分离出来,以保证主线程的高效响应。
解答
- NodeJS 代码是如何跑起来的
- 当我们执行 node server.js 时,NodeJS 首先会进行一系列的初始化操作,包括:
注册 C++ 系列的模块和 V8 的初始化操作
创建 environment 对象用于存放一些全局的公共变量
初始化模块加载器,以便在用户 JS 代码层调用原生 JS 模块以及原生 JS 模块调用 C++ 模块能够成功加载
初始化执行上下文,暴露 global 在全局上下文中,并设置一些全局变量和方法在 global 或 process 对象
初始化 libuv,创建一个默认的 event_loop 结构体用于管理后续各个阶段产生的任务
紧接着 NodeJS 执行用户 JS 代码,用户 JS 代码执行一些初始化的逻辑以及往事件循环注册任务,然后进程就进入事件循环的阶段。
整个事件循环分为 7 个阶段,timer 处理定时器任务,pending 处理 poll io 阶段的成功或错误回调,idle、prepare、check 是自定义阶段,poll io 主要处理网络 I/O,文件 I/O等任务,close 处理关闭的回调任务,同时在各个事件阶段还会穿插微任务队列。
以开篇的 TCP 服务为例,当创建 TCP 服务器调用原生 JS 的 net 模块的 server.listen 方法后, net 模块就会引用 C++ 的 TCP 模块实例化一个 TCP 服务器,内部调用了 Libuv 的 uv_tcp_init 方法,该方法封装了 C 中用于创建套接字的 socket 函数;接着就是调用 C++ 的 TCP 模块的 Bind 方法,该方法封装了 Libuv 的 uv_ip_addr 以及 uv_tcp_bind,分别用于设置 TCP 的 IP 地址和端口信息以及调用 C 中的 bind 方法用于绑定地址信息。
然后 net 模块注册 onconnect 回调函数,该函数将在客户端请求到来后,在 Libuv 的 poll io 阶段执行,onconnect 函数调用了 C++ 的 ConnectionWrap::OnConnection 方法,内部调用了 Libuv 的 uv_accpet 去接收来自客户端的连接。最后调用 TCP 实例的 listen 方法使得服务器进入被动监听状态,listen 使用了 C++ 的 TCPWrap::Listen 方法,该方法是对 uv_listen 的封装,最终调用的 C 的 listen 方法。
当客户端请求通过网卡传递过来,对应的监听型 socket 发生状态变更,事件循环模块根据命中之前设置的可读事件,将 onconnection 回调插入 poll io 阶段的任务队列,当新一轮的事件循环到达 poll io 时执行回调,调用 accept 方法创建与客户端的通信型 socket,此时进入进程阻塞,经过三次握手后,建立与客户端的连接,将用户 JS 的回调插入 poll io 的任务队列,在新一轮的事件循环中进行数据的处理。

image.png
- TCP 连接在 NodeJS 中是如何保持一直监听而进程不中断的
TCP 服务器在启动之后,就往 NodeJS 的事件循环系统插入 listen 的监听任务,该任务会一直阻塞监听(不超过 timeout)来自客户端的请求,当发生请求后,建立连接然后进行数据处理后,再会进入监听请求的阻塞状态,新一轮的事件循环发现 poll io 队列还有任务所以不会退出事件循环,从而驱动进程一直运行。
- NodeJS 是如何处理并发连接的,当遇到阻塞型调用时如何不阻塞主线程的
NodeJS 采用的是单线程+事件驱动的服务端架构,首先对于事件循环以外的代码会在初始化时执行完,然后进程就进入事件循环,针对网络 I/O NodeJS 底层采用的是 I/O 多路复用模型,通过监听就绪的连接做到从容应对大并发连接。对于网络数据而言,当调用阻塞的 recvfrom 处理来自的网络的数据,此时数据已经就绪,所以数据处理起来很快,如果是大文件,则需要业务代码自行开辟线程去处理;对于文件 I/O,NodeJS 底层采用线程池的机制,在主线程外开辟工作线程去处理本地大文件,在处理完后通过事件通知机制告诉上层 JS 代码。
参考资料
- https://blog.insiderattack.net/event-loop-and-the-big-picture-nodejs-event-loop-part-1-1cb67a182810
- https://zhuanlan.zhihu.com/p/115912936?utm_source=pocket_reader
- https://www.cnblogs.com/javalyy/p/8882066.html?utm_source=pocket_reader
- https://github.com/theanarkh/understand-nodejs/blob/master/docs/chapter01-Node.js%E7%BB%84%E6%88%90%E5%92%8C%E5%8E%9F%E7%90%86.md