前言
你知道Netty为什么性能这么高吗?你知道Redis为什么单线程如此之快吗?这都和底层的网络IO模型有关系,所以掌握网络IO模型真的很重要,是一个基础,对你更好的理解其他应用帮助非常大,今天我们就好好来聊聊Linux的5种网络IO模型。
IO工作原理
我们的应用大多数情况都是部署在linux系统中,linux系统也是一种应用,它是基于计算机硬件的一种操作系统软件。当我们接收一次网络传输,计算机硬件的网卡会从网络中将读到的字节流写到linux的buffer缓冲区内存中,然后用户空间会调用linux对外暴露的接口,将linux内核空间buffer内存中的数据拷贝到用户空间的buffer区。这一次网络读取就是磁盘IO,同理从磁盘中读取,也是遵循一样的机制。

IO的性能瓶颈主要是下面两个阶段:
- 准备阶段,指数据从网络网卡或本地存储器读取到内核的过程
- 复制阶段,指将内核缓冲区中的数据拷贝至用户态的进程缓冲区
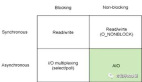
所以,Linux系统中提供了五种IO模型来提高性能,它们分别为BIO、NIO、多路复用、信号驱动、AIO,从性能上来说,它们属于依次递进的关系,但越靠后的IO模型实现也越为复杂。
1. 阻塞IO模型BIO
当用户应用线程调用linux操作系统的recvfrom函数读取数据的时候,如果内核的buffer内存中没有数据,那么用户线程会阻塞等待,直到内核的buffer内存中有数据了,才去将内核的buffer内存中的数据拷贝到用户应用内存中。

打比方理解:
比如你给女神发一条短信, 说我来找你了, 然后就默默的一直等着女神下楼, 这个期间除了等待你不会做其他事情, 属于备胎做法。也就是说线程会一直阻塞等待内核把数据准备好,然后将数据copy到用户空间。
优点:
- 开发简单,容易入门;
- 在阻塞等待期间,用户线程挂起,在挂起期间不会占用CPU资源。
缺点:
- 在BIO这种模型中,为了支持并发请求,通常会采用多线程的方式,并发过高时会导致创建大量线程,造成频繁的上下文切换,甚至系统崩溃
在Java常用的Tomcat服务器中,Tomcat7.x版本以下默认的IO类型也是BIO,但是Tomcat中对BIO模型稍微进行了优化,通过线程池做了限制,所以避免出现并发过高而系统崩溃的情况。
2. 非阻塞IO模型NIO
当用户应用线程调用linux操作系统的recvfrom函数读取数据的时候,如果内核的buffer内存中没有数据,那么用户线程会直接拿到结果(没有数据)不会阻塞等待,于是又会发起一次recvfrom函数调用,直到内核的buffer内存中有数据了,才去将内核的buffer内存中的数据拷贝到用户应用内存中。
在非阻塞IO模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。

打比方理解:
比如你给女神发短信, 如果不回, 接着再发, 一直发到女神下楼, 这个期间你除了发短信等待不会做其他事情, 属于专一做法。同理,用户线程无需等待内核数据准备结果,直接返回,然后通过轮询去问结果,如果结果为准备好,进程把数据copy到用户空间。
优点:
- 每次发起IO调用,在内核等待数据的过程中可以立即返回,用户线程不会阻塞。
缺点:
- 多个线程不断轮询内核是否有数据,会占用大量CPU时间。
NIO相对来说较为鸡肋,因此目前大多数的NIO技术并非采用这种多线程的模型,而是基于单线程的多路复用模型实现的,Java中支持的NIO模型亦是如此。
3. 多路复用IO模型
前面提到NIO由于线程在不断的轮询查看数据是否准备就绪,造成CPU开销较大。既然说是由于大量无效的轮询造成CPU占用过高,那么等内核中的数据准备好了之后,再去询问数据是否就绪是不是就可以了?答案是Yes。这就是我们多路复用IO模型的设计思想。
多路复用IO模型是基于文件描述符File Descriptor实现的,文件描述符是打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。文件包含音频文件,常规文件,硬件设备等等,也包括网络套接字(Socket)。
IO多路复用就是利用Linux的内核单线程去监听多个文件描述符,并在某个文件描述符可读、可写的时候接收到通知,避免无效的等待,充分利用CPU资源。
关于监听的策略,在linux中提供了3种模式,也就是3个函数,分别是 select、poll、epoll,如下图所示。

- select时间复杂度O(n),它仅仅知道了,有I/O事件发生了,却并不知道是哪几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长,而且最多支持的连接数量是1024个。
- poll(翻译:轮询)时间复杂度O(n),poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的。
- epoll时间复杂度O(1),epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))。
打个比方理解:
IO多路复用相当于找一个宿管大妈来帮你监视下楼的女生, 这个期间你可以些其他的事情. 例如可以顺便看看其他妹子,玩玩王者荣耀, 上个厕所等等。IO复用又包括 select、poll、epoll 模式。那么它们的区别是什么?
- select大妈 每一个女生下楼, select大妈都不知道这个是不是你的女神, 她需要一个一个询问, 并且select大妈能力还有限, 最多一次帮你监视1024个妹子。
- poll大妈不限制盯着女生的数量, 只要是经过宿舍楼门口的女生, 都会帮你去问是不是你女神。
- epoll大妈不限制盯着女生的数量, 并且也不需要一个一个去问. 那么如何做呢? epoll大妈会为每个进宿舍楼的女生脸上贴上一个大字条,上面写上女生自己的名字, 只要女生下楼了, epoll大妈就知道这个是不是你女神了, 然后大妈再通知你。
通知你之后,你需要到女生宿舍门口,把女神带回自己宿色。
优点:
- 系统不必创建维护大量线程,只使用一个线程,一个选择器即可同事处理成千上万个连接,大大减少系统开销。
缺点:
- 本质上,它还是同步的,数据准备好后,拷贝阶段依然是阻塞的。
如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用mutil-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll 的优势并不是对于单个连接能处理得更好,而是在于性能更多的连接,比如Redis、Netty都是采用这种IO模型。
4. 信号驱动IO模型
当用户应用线程调用linux操作系统的sigaction函数,直接返回,然后该线程去做其他事情了,当有数据来了的时候,内核空间会去递交信号给用户空间,此时用户空间会调用recvfrom函数去将数据从内核空间缓冲区拷贝到用户空间缓冲区,并处理数据。

打比方理解:
你给女神发短信,她下楼了主动通知你,你这时候在宿舍门口等着把她待会自己宿舍。同比,进程无需等待内核数据准备结果,直接返回,事件信号通知进程结果,进程把数据copy到用户空间。
优点:
- 从一定意义上实现了异步,也就是数据的准备阶段是异步非阻塞执行的
缺点:
- 当调用的线程过多,对应的信号量会增多,SIGIO函数处理不及时,会导致保存信号的队列溢出
- 内核空间与用户空间频繁的进行信号量的交互,性能很差。
现实中这种模式用的不多,就不展开阐述了。纵观上述的所有IO模型:BIO、NIO、多路复用、信号驱动,本质上从内核缓冲区拷贝数据到程序缓冲区的过程都是阻塞的,如果想要做到真正意义上的异步非阻塞IO,那么就牵扯到了异步IO模型。
5. 异步IO模型AIO
异步非阻塞模型,该模型是真正意义上的异步非阻塞式IO,数据准备与复制阶段都是异步非阻塞的。
在该模型中,首先用户进程中会创建一个Sigio信号处理程序,然后会系统调用sigaction信号处理函数,紧接着内核会直接让用户进程中的线程返回,用户进程可在这期间干别的工作,当内核中的数据准备好之后,内核会生成一个Sigio信号,通知对应的用户进程数据已准备就绪,然后由用户进程在触发一个recvfrom的系统调用,从内核中将数据拷贝出来进行处理。

打比方理解:
你给女神发短信,女神准备好了并且主动来到你宿舍通知你,你开门。 同比,应用进程把IO请求传给内核后,完全由内核去操作文件拷贝到用户空间。内核完成相关操作后,会发信号告诉应用进程本次IO已经完成。
优点:
- 真正实现了异步非阻塞,吞吐量高
缺点:
- 对内核有要求,比如Linux系统中,异步IO在2.6才引入
总结
本文讲解了Linux系统中5中IO模型,其中前面4种都属于同步IO,因为数据拷贝阶段都是处于阻塞状态,只有异步IO模型才真正实现了异步非阻塞。