1.前言
内因:随着之家业务快速发展,公司内部的数字化需求越来越多,信息系统团队每年都面对大量的需求,但研发侧资源是一定的,那么如何更快速的交付需求,越来越成为团队重点思考解决的问题。
外因:互联网技术的不断推陈出新,尤其以React,Vue为代表的前端技术框架突飞猛进,大幅降低了可视化拖拽操作的技术门槛。
行业内低代码平台主要涉及表单,流程, 数据开发,BI工具,智能机器人等方向。

2.问界低代码平台介绍
问界平台,第一期锁定了数据方向的主题进行建设开发。具体围绕数据分析的以下5个场景:
数据建模场景:实现零代码,可视化的拖拉拽方式数据建模;
数据开发场景:实现数据抽取,清洗加工,然后输出到目标表等功能;
数据分析场景:通过BI解决多维度数据分析需求;
指标及维度规则场景:实现在线的计算公式、数据核算规则的配置及后端自动化核算;
数据质量监控场景:实现低代码方式的数据监控,及既定规则的数据自动修复
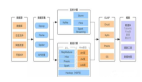
3.问界平台技术架构介绍
3.1前端框架
前端框架选型React, React提供了组件化的编程思想,特别适合中大工程采用,另外考虑移动端RN的普及,所以整体采用React来实施。
前端框架一览表:

3.2后端框架
后端整体的技术架构基于Spring Cloud微服务框架,依托于云平台Asf ; 通过SkyWalking实现后端全链路调用链的监控。

3.2.后端框架
3.3调度引擎
调度引擎选型方面,我们选择了PowerJob开源的工作流调度引擎, 目前市面上的调度引擎主要分为两类,定时调度,代表性的调度引擎有quartz,xxlJob等,以及以Oozie,PowerJob等为代表的工作流调度引擎,考虑到数据开发场景的大量数据依赖任务,问界平台选择了PowerJob来负责底层的任务调度引擎,PowJob框架本身自带流程引擎设计器。

3.4ORM框架
采取自研的ORM框架(automis.orm),相比Mybatis半自动化ORM框架,省去大量SQL脚本的编写, 框架底层增加大量常用的数据查询方法,如自动加载为hash,自动格式化为交叉表等数据的查询及汇总,小计合计的计算等。框架自动支持底层各类日志的跟踪分析,及数据缓存策略,如基于方法,基于脚本,基于路径的数据缓存等。
问界低代码平台后续将继续表单场景的低代码化,基于当前支持动态实体多表的自动序列化。可以有效支持基于数据模型设计的表单数据自动映射与序列化;
3.5运行机制

3.5.运行机制
4.问界低代码场景介绍
4.1数据建模场景
数据建模做为数据分析的基础,问界提供了在线ER图的设计,并且可以在线进行数据表,维度及度量名称等的二次修改及调整,另外支持计算字段及分组字段等的高阶配置;
- 计算字段:支持聚合函数(sum/count/avg等)及计算公式(如:a+b-c*100)等的配置
- 分组字段:支持时间、字符、数值类型的快速分组配置(类case when)
通过以上功能,普通的数据分析师完全可以通过零代码的方式,完成线上数据模型设计,并通过后续的BI分析模块进行下一步的数据分析。
► 4.1.1 在线ER图的设计

4.1.1.在线ER图的设计
► 4.1.2 计算字段的可视化配置

4.1.2.计算字段的可视化配置
► 4.1.3 分组字段的可视化配置

4.1.3.分组字段的可视化配置
4.2数据开发场景
所有的数据分析,离不开基础数据的加工,只有加工清洗后的数据,才具备分析的价值。
问界平台目前已上线支持12个组件,其中4类脚本开发组件,用于在线直接数据脚本的编写与开发,采用Monaco Editor 支持一定的SQL语法糖,支持mysql,SqlServer, hiveSQL, StarRockcs等数据库脚本的编写;另外提供7类数据专项开发组件,后续还会不断进行新增扩充组件(如:API组件、脚本组件等)。
开发模块运行机制:

4.2.数据开发场景
4.2数据开发场景
► 4.2.1 数据集成
采用阿里的DataX框架, 支持多种数据库类型之间的数据抽取;
1.支持在线的源数据与目标数据列字段的自动映射,如同行关联,同名关联等,以及手工拖拽式的配置;

4.2.1.数据集成-列映射
2.对接之家大数据的平台,基于大数据平台能力,实现hive,StarRocks等的能力复用;
► 4.2.2 数据清洗
数据在线清洗功能, 共提供5类组件
- 输入组件:负责源数据输入的定义,支持多源数据的输入;
- 关联组件:提供异构数据的在线关联,实现数据的列扩展;
- 合并组件:合并多个异构源的数据,实现数据的行扩展;
- 聚合组件:实现数据汇总配置,支持多种数据库的聚合函数;
- 清洗组件:支持对输入的数据再次过滤,进行数据行的处理;通过计算字段,值替换等实现数据列的处理;
- 输出组件:用于将清洗后的数据,写入目标的数据源;
效果图:

4.2.2.数据清洗
► 4.2.3 SQL组件
- MySQL脚本组件
- MsSQL脚本组件
- HiveSql脚本组件
- StarRocks脚本组件
SQL编辑器选型对比:

具体使用效果:

4.2.3.SQL组件
► 4.2.4 辅助组件
开始组件:用来配置任务的调度策略;问界平台封装了Cron的公共组件,可以在线快速配置Cron表达式;
效果图:

4.2.4.辅助组件-CRON表达式设置
► 4.2.5 动态参数
同时数据开发模块还提供了执行时动态参数替换,用于更灵活动态的执行相关组件任务,可支持全局及组件自定义参数设置。
参数名格式:${xxxx}

4.2.5.动态参数-全局参数

4.2.5.动态参数-自定义参数
4.3指标规则场景
数据分析的需求多变,因此数据加工离不开规则的配置,问界平台提供了维度管理及指标管理实现了规则的线上化配置。
► 4.3.1 维度管理
维度管理功能提供了大量的线上口径数据的定义,后台基于规则配置完成维度数据的核算,目前该场景已大量在销管,业绩核算等业务场景中应用。

4.3.1.维度管理
► 4.3.2 指标管理
用于指标公式的配置,提供原子指标,派生指标,衍生指标三种类型的指标库管理。目前指标模块已在HR组织健康度完成150+指标的管理。
实现的效果如下:

4.3.2.指标管理
4.4数据分析场景
数据分析场景主要面向了一线的业务人员,及各个BU的数据分析师。在我们总结的数据分析场景中,一共提供以下三类场景的实现
► 4.4.1 仪表板
仪表板主要采用 Echarts框架, ECharts最初由百度团队开源,并于2018年初捐赠给Apache基金会,成为ASF孵化级项目。未采用Highcharts的原因, 付费非开源不利于后续的升级。
另外我们也自研了多个场景的分析组件,如果故事线组件,交叉表及明细表组件等。
截止到当前仪表板共提供7类23个场景的分析组件,另外提供基于路径的钻取分析,同环比配置,及基于明细的下钻配置,每个数据卡片支持任意的拖拽布局,支持任何系统的行级权限配置。

4.4.1.仪表板
►4.4.2 电子报表
电子报表我们一期实现了常用的明细表及交叉表的设计;2023年我们将继续升级这块,满足所有中国式报表的分析场景,目前已完成技术框架的原型。

4.4.2 电子报表
►4.4.3 多维分析
多维分析场景主要用来实现数据的及时探查分析, 实现的效果如下图。可以快速进行行列配置,并自动进行聚合,及各类维度的小计,总计等的配置。
底层采用自研的ORM框架,自动实现下面的复杂分析场景。
多维分析的场景效果图:

4.4.3.多维分析
4.5数据监控与预警
问界平台提供了在线的数据脚本巡查,并可以进行字段级的数据预警规则配置。
提醒方式分别支持邮件、手机短信、钉钉消息及钉钉群群机器人消息,可以快速完成数据预警及数据播报场景的应用,同时还提供规则明确情况下的数据自动修复功能。
► 4.5.1 邮件提醒
支持邮件模板的配置,支持语法糖;异常数据内容支持以邮件附件的形式发送;

4.5.1.邮件提醒
►4.5.2 钉钉机器人提醒
支持在线配置钉钉机器人 ,可以实现各种群消息提醒, 如数据播报,值班提醒机器人等。目前我们已在财务结账,技术值班等完成这些场景的配置。
效果如下图:

4.5.2.钉钉机器人提醒
►4.5.3 短信提醒
►4.5.4 钉钉提醒
5.总结与规划
5.1总结
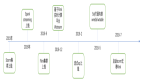
问界低代码平台在2022年12月2日正式完成V1.0.0的发布,目前已在之家人财物事等多个业务场景中进行使用,在我们实践的过程中,团队自身的交付效率得到了大幅的提升。
2023年,我们将继续夯实每个功能的细节体验,实现基于数据模型的表单配置场景,并完成权限平台,流程中心等的功能整合,为之家提供一站式的全场景低代码平台,赋能一线业务,也赋能我们所有的前中后台的产研团队。
另外我们也希望与各个BU的技术团队进行共建,共同为之家的低代码平台建设,添砖加瓦,为技术人提效!
5.2规划
问界平台23年规划:

5.2.规划