对于很多的开发小伙伴来说,在MySQL中进行in子查询是一个非常常见的操作。
虽然也有很多人说,尽量少用in子查询,in的数量过多会影响查询性能。
但其实MySQL做了不少的优化手段来保证in子查询的性能,大家也能在实际的业务中感受到in子查询的速度也没那么慢。
那今天就带大家了解一下,MySQL到底是怎么来优化in子查询的。
普通in子查询
首先,我们看一下MySQL是如何执行一个普通的in子查询的。
以一个简单的子查询为例:
对于这个子查询画了一个简单的查询图,不同颜色代表不同的数据页。
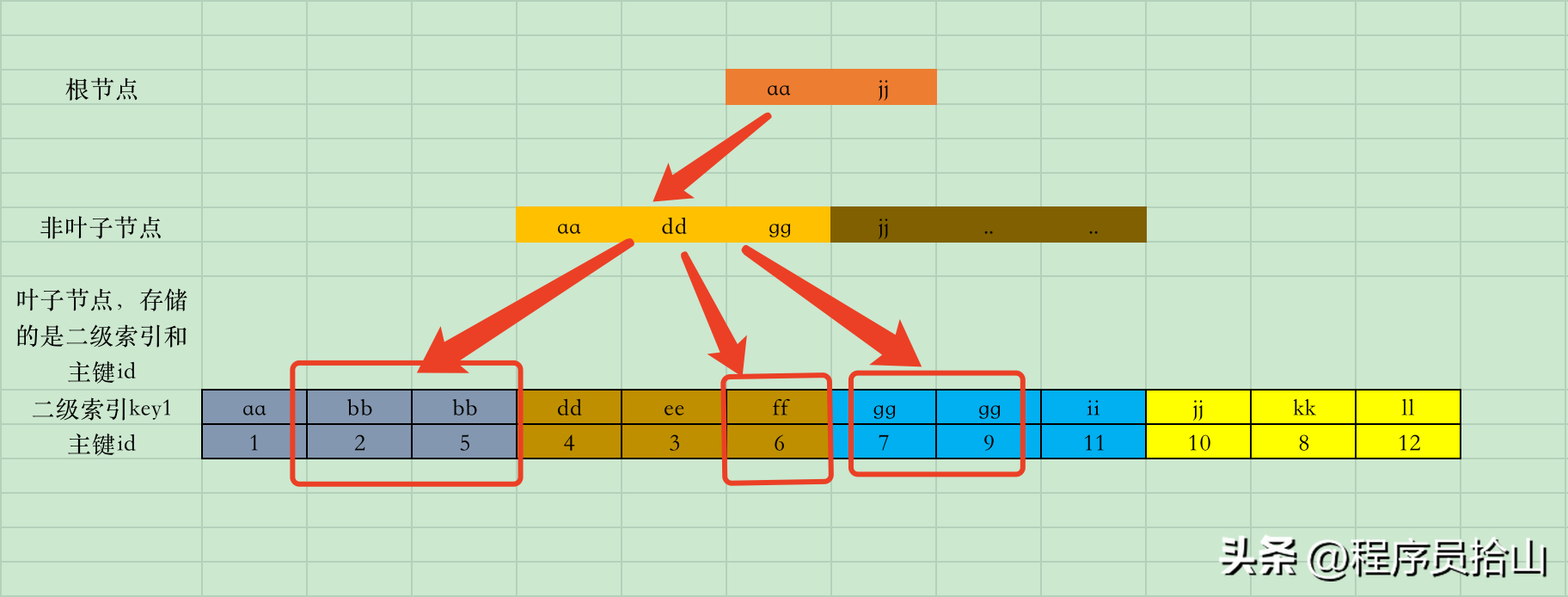
在这个图里,最上层的是根节点,中间的是非叶子节点,最下面的是叶子节点。
对于一个普通的二级索引来说,叶子节点存储的是索引key和主键id,这些基础知识就不详细展开说了。
需要注意的是,二级索引在叶子节点中是按照key的顺序从小到大排序的,但是对应的主键id可不一定。
可能与大家想象的不同,MySQL在执行in子查询时,会把in语句中的条件当做一个个的区间,比如:
['bb','bb'],['ff','ff'],['gg','gg']
然后MySQL在二级索引树上,会先查询['bb','bb']这个区间,比如首先查询到第一个数据页中符合条件的第一条数据(bb,2),获取到主键id=2之后,去聚簇索引回表查询所需的数据(因为我们使用的select *,需要获取到所有的列值)。
然后查询第一个数据页中符合条件的第二条数据(bb,5),获取到主键id=5之后,去聚簇索引回表查询所需的数据,
然后查询第二个数据页中符合条件的第三条数据(ff,6),
不断的重复上面的动作。。。。
最后获取到一个结果集,返回到Server,再由Server返回到客户端。
看到这里大家是否可以感觉到,这样查询数据也太麻烦了,特别是当in子查询的条件越来越多时,如何保证性能呢?
下面,我们一起来看一下,MySQL是如何优化in子查询的。
物化表
首先,为了演示我们建两张表table1和table2,并建立两个二级索引idx_c1和idx_c2。
下面以一个简单的子查询为例:在table2表中查询t2.c2=3的id,并作为table1表c1的查询条件。
对于一个这样普通的子查询来说,MySQL使用了一种叫做物化表的方式来提升性能。
什么意思呢?
就是将子查询的结果集去重后放入到一个临时表中,临时表的列就是子查询的结果集中的列。
去重的目的是为了让临时表尽可能的精简,因为在临时表中重复的列并没有什么意义。
当结果集比较小时,MySQL会为临时表使用memory引擎,并且为临时表中的列建立哈希索引。哈希索引的查询时间复杂度是O(1),查询速度是非常快的。
但是如果结果集比较大时,MySQL就会将临时表定义为InnoDB类型表,并且建立B+树索引,就像一个普通的表一样使用。
话说回来,将子查询转换为临时表以后,其实查询就变成了两张表的连接查询,也就是两个表的内连接。
一旦转换为内连接就好办了,经典的“小表驱动大表”的优化准则就可以派上用场了。
我们看一下MySQL优化器对上面的SQL优化后的结果:
可以看到,MySQL将其转换为了内连接,并且以table2为驱动表,table1为被驱动表的方式进行了查询。
由于c1和c2列上都有索引,那么此时这个sql的执行速度还是相当可以的。
半连接
虽然通过物化表的方式,MySQL将子查询转换为了连接查询,但是创建临时表的成本也是有的。
那可不可以再优化一步,将创建临时表的成本也给优化掉呢?
在某些情况下,确实是可以的。
在上文我们提到,MySQL会将子查询的结果集去重后,放入一个临时表中。
那大家是否意识到,这个临时表中的记录都是唯一的,换句话说,就是一个唯一索引的列。
那么当我们的子查询语句的结果集也类似于一个唯一索引集时,MySQL就不去创建临时表了,而是直接尝试将sql改写成内连接。
半连接的优化还是比较复杂的,要求条件相对也苛刻一点,这里就不再详细的说了,感兴趣的朋友可以去深入学习一下。
最后
无论MySQL采用了哪种优化方法,只要知道了其实现的大致原理,对于使用者来说,就有了对应的优化思路。
特别建议大家写完SQL以后,习惯性的使用explain分析一下是否命中了索引,扫描的行数是否过多。
只有不断的实操,优化SQL的能力才会不断提升。