用过 Canvas 的都知道它的 API 比较多,使用起来也很麻烦,比如我想绘制一个圆形就要调一堆 API,对开发算不上友好。
为了解决这个痛点,诞生了例如 PIXI、ZRender、Fabric 等 Canvas 库,对 Canvas API 进行了一系列的封装。
今天主要介绍一下社区几个比较有代表性的 Canvas 渲染引擎的设计原理。
这篇文中不会从源码讲起,更像是一篇科普文章,介绍 Canvas 一些有趣的点。
1. 特性
Canvas 渲染引擎一般包括下面几个特点:
- 封装
将 Canvas API 的调用封装成更简单、清晰的形式,贴近于我们使用 DOM 的方式。
比如想画一个圆,直接调用封装好的绘制方法就行了,我们不需要关心是如何绘制的。
- 性能
虽然封装之后的 API 很贴近 HTML 语法,但也意味着开发者很难去做一些底层的性能优化。因此,大部分 Canvas 渲染引擎都会内置了一些性能优化手段。
常见的性能优化手段有离屏渲染、脏区渲染、异步渲染等等。
- 跨平台
一些渲染引擎为了更加通用,在底层做了更多抽象,不仅支持 Canvas Renderer,甚至还支持 WebGL、WebGPU、SVG、CanvasKit、小程序等等,真正实现了一套代码多种渲染。
针对底层的渲染流程和类进行抽象化,在不同平台具象化去实现具体的渲染逻辑,从而可以一套代码,只要切换渲染器就能实现多平台渲染。
2. 封装
2.1 虚拟节点
Canvas 是一张画布,里面的内容都是自己调用 API 绘制的,所以更像是我们拿起画笔来作画。
目前主流的 Canvas 渲染引擎都会将要绘制的图形封装成类,以方便开发者去调用,复用性也比较强。调用方式类似于 DOM,每个实例可以当做一个虚拟节点。
使用 AntV/g 的例子:
在此基础上,可以进一步针对 React/Vue 语法进行封装,让用户对底层的实现无感知。
使用 React-Konva 的例子(通过 react-reconciler 实现):
除了内置的图形类,很多渲染引擎还会提供自定义绘制图形类的能力。
以 Konva 为例,每个图形类都需要实现 sceneFunc 方法,在这个方法里面去调用 Canvas API 来进行绘制。
如果需要自定义新的图形,就可以继承 Shape 来实现 sceneFunc 方法。
Konva 里面圆形绘制类的实现:
参照 DOM 树的结构,每个 Konva 应用包括一个舞台 Stage、多个画布 Layer、多个分组 Group,以及若干的叶子节点 Shape,这些虚拟节点关联起来最终形成了一棵树。

在 Konva 中,一个 Stage 就是根节点,Layer 对应一个 Canvas 画布,Group 是指多个 Shape 的集合,它本身不会进行绘制,但同一个 Group 里面的 Shape 可以一起应用旋转、缩放等变换。
Shape 则是指具体的绘制节点,比如 Rect、Circle、Text 等等。
2.2 包围盒
既然有了虚拟节点,那知道每个虚拟节点的位置和大小也比较重要,它会涉及到判断两个图形是否相交、事件等等。
有时候元素的形状不是很规则,如果直接对不规则元素进行碰撞检测会比较麻烦,所以就有了一个近似的算法,就是在物体外侧加上包围盒,如图:
目前主流的包围盒有 AABB 和 OBB 两种。
AABB 包围盒:
实现方式简单,直接用最大最小的横纵坐标来生成包围盒,但不会跟着元素旋转,因此空白区域比较多,也不够准确。
也是目前 Konva 和 AntV 使用的方式。(适合表格业务)
OBB 包围盒:
实现方式相对复杂,通过构建协方差矩阵来计算出新的坐标轴方向,将其顶点投射到坐标轴上面来得到新的包围盒。
所以 OBB 包围盒更加准确一些,也是 cocos2d 使用的方式。
碰撞检测:
两个包围盒在所有轴(与边平行)上的投影都发生重叠,则判定为碰撞;否则,没有发生碰撞。
2.3 排版系统
绘制 Canvas 的时候一般是通过相对坐标来确定当前要绘制的位置,所以都是通过各种计算来拿到 x、y。
即使是 Konva 也是依赖于 x、y 来做相对定位。
因此,在 AntV 和 SpriteJS 这类 Canvas 渲染引擎里面,都内置支持了盒模型的语法糖,底层会将盒模型属性进行一次计算转换成 x、y。
以 AntV 为例子,排版能力是基于 Facebook 开源的 Yoga 排版引擎(React Native)来实现的,支持一套非常完整的盒模型和 Flex 布局语法。
在腾讯开源的 Hippy 里面自己实现了一套类似 Yoga 的排版引擎,叫做 Titank。
在飞书文档多维表格里面,排版语法更加接近于 Flutter,实现了 Padding、Column、Row、Margin、Expanded、Flex、GridView 等 Widget。
下面的示例是 Flutter 的:
实现了盒模型和 Flex 布局,可以让 Canvas 的排版能力更上一层楼。
不仅可以减少代码中的大量计算,也可以让大家从 DOM 开发无缝衔接进来,值得我们参考。
canvas-flexbox - CodeSandbox
3. 事件
Canvas 本身是一块画布,所以里面的内容都是画出来的,在 DOM 树里面也只是一个 Canvas 的节点,所以如何才能知道当前点击的是哪个图形呢?
由于 Canvas 渲染引擎都会封装虚拟节点,每个节点都有自己的包围盒,所以为实现 Canvas 的事件系统提供了可能性。
主流的 Canvas 渲染引擎都是针对 Canvas 节点或者上层节点进行事件委托,监听用户相关的事件(mouseDown、click、touch等等)之后,匹配到当前触发的元素,将事件分发出去,并且拥有一套向上冒泡的机制。
目前主流的两种事件实现方式分别是取色值法和几何法。
3.1 取色值法
取色值法是 Konva 采用的实现方式,它的实现方式非常简单,匹配精确度很高,适合不规则图形的匹配。
取色值法的原理如下:
- 在主 Canvas 绘制一个图形的时候,会为这个图形生成一个随机的 colorKey(十六进制的颜色),同时建立类似于 Map<colorKey, Shape> 的映射。
- 绘制的同时会在内存里的 hitCanvas 同样位置绘制一个一模一样的图形,填充色是刚才的 colorKey。
- 当用户鼠标点击 Canvas 画布的时候,可以拿到鼠标触发的 x、y,将其传给内存里面的 Canvas。
- 内存里面的 Canvas 通过 getImageData 来获取到当前的颜色,进而通过 colorKey 来匹配到对应的图形。
从上述原理可以看出来,Konva 对于不规则图形的匹配依然很精确,但缺点也很明显,每次都需要绘制两份,导致绘制性能变差。
同时,getImageData 耗时比较高,在频繁触发的场景(onWheel)会导致帧率下降严重。
3.2 几何法
几何法有很多种实现方式,这里主要讲解引射线法,因为需要进行一系列几何计算,所以这里我称之为几何法。
几何法是 AntV 和飞书文档采用的实现方式,实现方式相对复杂一些,针对不规则图形的匹配效率偏低。
几何法的实现原理如下:
- 基于当前虚拟节点的包围盒来构建一棵 R Tree
- 当用户触发事件的时候,利用 R Tree 来进行空间索引查找,依据 z-index 找到最顶层的一个图形。
- 从目标点出发向一侧发出一条射线,看这条射线和多边形所有边的交点数目。
- 如果有奇数个交点,则说明在内部,如果有偶数个交点,则说明在外部。
为什么奇数是在内部,偶数是在外部呢?我们假设射线与这个图形的交点,进入图形叫做穿入,离开图形叫做穿出。
在图形内部发出的射线,一定会有穿出但没有穿入的情况。但在外部发出的射线,穿入和穿出是相对的。
但是射线刚好穿过顶点的情况比较特殊,因此需要单独进行判断。
几何法的优势在于不需要在内存里面进行重复绘制,但依赖于复杂的几何计算,因此不适合有大量不规则图形的情况。
在 AntV 里面支持对不规则图形的匹配,但飞书文档由于是表格业务,所以可以将所有图形都当做矩形来处理,反而更简单一些。
4. 性能
由于 Canvas 渲染引擎都会进行大量的封装,所以开发者想针对底层做性能优化是非常难的,需要渲染引擎自身去支持一些优化。
4.1 异步批量渲染
在飞书文档 Bitable 和 Konva 里面都支持异步渲染,将大量绘制进行批量处理。
由于每次修改图形的属性或者添加、销毁子节点都会触发渲染,为了避免同时修改多个属性时导致的重复渲染,因此约定每次在下一帧进行批量绘制。
这种渲染方式类似于 React 的 setState,避免短时间内多次 setState 导致多次 render。
4.2 离屏渲染
离屏渲染我们应该都比较熟悉了,就是两个 Canvas 来回用 drawImage 绘制可复用部分,从而减少绘制的耗时。
这里主要讲解 Konva 和飞书 Bitable 里面的离屏渲染。
在 Konva 中的离屏渲染主要是针对 Group 级别来做的,通过调用 cache 方法就能实现离屏渲染。
基于 Group 来做离屏渲染的原理是:
- 调用 cache 方法,创建一个离屏 Canvas 节点。
- 遍历 Group 子节点进行绘制,同时将其绘制到离屏 Canvas 上面。
- 下次 batchDraw 的时候判断是否有缓存,如果有,那么直接走 drawImage 的形式。
这种离屏渲染的调用方式比较简单,Group 的粒度可以由开发者自己决定,但也有一定的问题。
- 比较难应用于表格这种形式的业务
- Konva 没有脏检测能力,即使 Group 里面的 Shape 属性改变了,依然不会更新离屏 Canvas。
- 由于使用色值法来匹配图形,导致开启了离屏渲染,实际上至少要绘制四份(主canvas、事件 hitCanvas、离屏 cacheCanvas、离屏事件 cacheHitCanvas)。
为什么需要绘制四份呢?因为离屏渲染是 drawImage 的形式,这样就不会有 colorKey 和 Shape 对应的情况了,所以离屏 Canvas 也要有一个自己的 hitCanvas 来做 getImageData,也就是 cacheHitCanvas。
另一种场景的离屏渲染就是飞书 Bitable 里面的实现。
飞书在底层之上封装了虚拟列表的 Widget,也就是基于业务定制的 Widget,这也是一种有趣的思路。
- 创建一个虚拟列表的 Widget 类,将列表数据传入
- 实现列表每一项的绘制方法,将列表绘制出来
- 滚动的时候虚拟列表内部进行节点的回收创建,但不会进行异步批量渲染,针对可复用的部分进行离屏渲染
- 更新阶段,通过 key 对比来决定是回收、创建还是复用。
在多维表格看板视图里面,每个分组都是一个虚拟列表,多个分组(虚拟列表)又组合成一个大的虚拟列表。
多选单元格编辑器也可以基于虚拟列表实现。
虚拟列表 Widget 类适合多维表格这种业务,多个视图都需要有自己的滚动容器,不同视图都需要处理节点的回收、复用、新建,通过公用 Widget 可以一步到位去支持,也方便在内部去做更多性能优化。
4.3 脏区渲染
对于 Konva 来说,每次重新渲染都是对整个 Canvas 做 clearRect 清除,然后重新绘制,性能相对比较差。
更好的做法是检测到当前的改动影响到的范围,计算出重绘范围后,只清除重绘区的内容重新进行绘制。
在 Canvas 中可以通过 rect 和 clip 限制绘制区域,从而做到只对部分区域重绘。
以前 ECharts 底层的 ZRender 为例来讲解:
- 根据图形前后变化,来计算出重绘区域,比如上图的区域,在飞书文档中会将整个移动的路径当做重绘区域。
- 如果有多个重绘区域,那么优先尝试将相交(包围盒)的重绘区进行合并,并且优先合并相交面积最大的重绘区。
- 如果合并完成后,当前剩余的重绘区数量大于5,则进一步进行合并,直到数量只剩5。
- 依次遍历这些重绘区域,先清除掉原有的内容,再进行绘制。
飞书文档多维表格没有做 Canvas 渲染分层,但对各种交互响应速度非常快,也是得益于底层渲染引擎对脏矩形渲染的支持,它的性能也是所有同类产品里面最好的。
除了上述的这些,还有在文档这边使用的一些优化手段,比如合并相同属性的图形绘制(线、矩形、文本等)、Canvas 分层等等,这些就不多做阐述了。
5. 跨平台
很多 Canvas 渲染引擎并不满足于只做 Canvas,一般还会支持一些其他的渲染模式,比如 SVG 渲染、WebGL 渲染、WebGPU 渲染等等。
在 AntV 里面通过引入对应的 package 来实现加载渲染器的,在 ZRender 中则是通过 register 来注册不同的渲染器。
AntV 中使用 CanvasKit 渲染:
关于跨平台的架构这里不做讲解,主要是抹平不同平台的差异,这里主要讲解一下针对于服务端渲染的不同处理。
主流的服务端渲染方式有两种,一种是用 node-canvas 来输出一张图片,在 echarts 等库中都有使用,缺陷在于文本排版不够准确,对于自适应浏览器窗口的情况无法处理。因此它不适用于文档直出的场景。
另一种就是通过 SVG 来模拟 Canvas 的效果,输出 SVG DOM 字符串。但它的实现会比较麻烦,也无法 100% 还原 Canvas 的效果。
但很多 Canvas 渲染引擎本身也支持 SVG 渲染,即使不支持,也可以通过 canvas2svg 这个库来进行转换。
对于更加通用的场景来说,在浏览器端使用 Canvas 渲染,服务端使用 SVG 渲染是更合理的形式。
在新版 ECharts 里面,针对 SVG 服务端渲染的能力,还支持了 Virtual DOM 来代替 JSDOM,最后转换成 DOM 字符串。
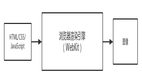
在飞书文档中使用了一种完全独立于 node-canvas 和 SVG 的解决方式,非常值得我们借鉴。
由于飞书多维表格底层统一了渲染引擎,所有绘制元素都是 Widget(对齐 Flutter),可以脱水转换成下面 FVG 格式。

一般来说,文档业务首屏加载是下面这么几步:
获取首屏数据 -> 资源加载 -> 首屏数据反序列化 -> 初始化 Model 层 -> 计算排版数据 -> Canvas 渲染
在飞书文档里面直出渲染层 Widget 的数据结构,这个数据结构是最后提供给 Canvas 渲染的数据,也就是已经经过了计算排版数据阶段。
当渲染层 JS 资源加载完成后,直接省略反序列化、初始化 Model、计算排版数据等阶段,将 FVG 转换成 Widget 进行 Canvas 渲染,这一步非常接近于 React 的 hydrate,很巧妙。