1、前言
本文主要描述的是在一次意外中,我们的Proxmox/Ceph集群上丢失了36个磁盘中的33个,这对我们而言,完全是一场灾难!
下文将会相信描述该事件,同时也包含了如何修复以及回溯该严重故障。
到2020年底,我们终于有了一个长期未完成的维护窗口,以便为客户进行系统升级。在此维护窗口期间(涉及服务器系统的重新启动),涉及的Ceph群集意外进入关机状态。本来计划在晚上早些时候做几个小时的检查清单工作,结果却成了一个紧急情况;让我们称之为噩梦吧(不仅仅是因为它让我们多熬了几个通宵)。因为我们从RCA(故障回溯)中学到了一些东西,所以值得与其他人分享。
但首先,让我们退一步,搞清楚我们这次事件的来龙去脉。
2、系统升级
升级的一部分包括3台Debian服务器(我们在这里称它们为server1、server2和server3),它们运行在ProxMoxV5+Debian/stretch上,每个都有12个Ceph OSD(总共65.45TB),这就是Proxmox与Ceph的超融合集群。

首先,我们将ProxMoxV5/stretch系统升级为ProxMoxV6/buster,然后再更新CephV12.13至最新版本14.2版本,由ProxMoxV6/buster支持。Proxmox升级包括将corosync从v2更新到v3。
作为此次升级的一部分,我们必须应用一些配置更改,如调整ring0+ring1地址设置,并将mon_host配置添加到Ceph配置中。
在前两台服务器重新启动期间,我们注意到配置问题。在修复这些问题之后,我们也重新启动了第三台服务器。然后,我们注意到几个Ceph OSD意外停机。升级后NTP服务未按预期工作。根本问题是ntp与systemd timesyncd的竞争条件(请参见#889290)。
因此,Ceph出现了时钟偏移问题,这表明Ceph监视器的时钟不同步(这对于正确的Ceph操作至关重要)。我们最初假设Ceph OSD故障源于这个时钟偏移问题,所以我们处理了它。
在又一轮重新启动之后,为了确保系统以完全相同和正常的配置和服务运行,我们注意到许多失败的OSD。这一次,除了三个OSD(19、21和22)外,其他所有OSD都停机:
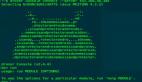
% sudo ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 65.44138 root default
-2 21.81310 host server1
0 hdd 1.08989 osd.0 down 1.00000 1.00000
1 hdd 1.08989 osd.1 down 1.00000 1.00000
2 hdd 1.63539 osd.2 down 1.00000 1.00000
3 hdd 1.63539 osd.3 down 1.00000 1.00000
4 hdd 1.63539 osd.4 down 1.00000 1.00000
5 hdd 1.63539 osd.5 down 1.00000 1.00000
18 hdd 2.18279 osd.18 down 1.00000 1.00000
20 hdd 2.18179 osd.20 down 1.00000 1.00000
28 hdd 2.18179 osd.28 down 1.00000 1.00000
29 hdd 2.18179 osd.29 down 1.00000 1.00000
30 hdd 2.18179 osd.30 down 1.00000 1.00000
31 hdd 2.18179 osd.31 down 1.00000 1.00000
-4 21.81409 host server2
6 hdd 1.08989 osd.6 down 1.00000 1.00000
7 hdd 1.08989 osd.7 down 1.00000 1.00000
8 hdd 1.63539 osd.8 down 1.00000 1.00000
9 hdd 1.63539 osd.9 down 1.00000 1.00000
10 hdd 1.63539 osd.10 down 1.00000 1.00000
11 hdd 1.63539 osd.11 down 1.00000 1.00000
19 hdd 2.18179 osd.19 up 1.00000 1.00000
21 hdd 2.18279 osd.21 up 1.00000 1.00000
22 hdd 2.18279 osd.22 up 1.00000 1.00000
32 hdd 2.18179 osd.32 down 1.00000 1.00000
33 hdd 2.18179 osd.33 down 1.00000 1.00000
34 hdd 2.18179 osd.34 down 1.00000 1.00000
-3 21.81419 host server3
12 hdd 1.08989 osd.12 down 1.00000 1.00000
13 hdd 1.08989 osd.13 down 1.00000 1.00000
14 hdd 1.63539 osd.14 down 1.00000 1.00000
15 hdd 1.63539 osd.15 down 1.00000 1.00000
16 hdd 1.63539 osd.16 down 1.00000 1.00000
17 hdd 1.63539 osd.17 down 1.00000 1.00000
23 hdd 2.18190 osd.23 down 1.00000 1.00000
24 hdd 2.18279 osd.24 down 1.00000 1.00000
25 hdd 2.18279 osd.25 down 1.00000 1.00000
35 hdd 2.18179 osd.35 down 1.00000 1.00000
36 hdd 2.18179 osd.36 down 1.00000 1.00000
37 hdd 2.18179 osd.37 down 1.00000 1.00000
我们顿时感到不妙!我们的集群是不是挂了?发生了什么,我们怎么才能把其他的OSD都找回来?我们在日志中偶然发现了这一详细信息:
kernel: [ 73.697957] XFS (sdl1): SB stripe unit sanity check failed
kernel: [ 73.698002] XFS (sdl1): Metadata corruption detected at xfs_sb_read_verify+0x10e/0x180 [xfs], xfs_sb block 0xffffffffffffffff
kernel: [ 73.698799] XFS (sdl1): Unmount and run xfs_repair
kernel: [ 73.699199] XFS (sdl1): First 128 bytes of corrupted metadata buffer:
kernel: [ 73.699677] 00000000: 58 46 53 42 00 00 10 00 00 00 00 00 00 00 62 00 XFSB..........b.
kernel: [ 73.700205] 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
kernel: [ 73.700836] 00000020: 62 44 2b c0 e6 22 40 d7 84 3d e1 cc 65 88 e9 d8 bD+.."@..=..e...
kernel: [ 73.701347] 00000030: 00 00 00 00 00 00 40 08 00 00 00 00 00 00 01 00 ......@.........
kernel: [ 73.701770] 00000040: 00 00 00 00 00 00 01 01 00 00 00 00 00 00 01 02 ................
ceph-disk[4240]: mount: /var/lib/ceph/tmp/mnt.jw367Y: mount(2) system call failed: Structure needs cleaning.
ceph-disk[4240]: ceph-disk: Mounting filesystem failed: Command '['/bin/mount', '-t', u'xfs', '-o', 'noatime,inode64', '--', '/dev/disk/by-parttypeuuid/4fbd7e29-9d25-41b8-afd0-062c0ceff05d.cdda39ed-5
ceph/tmp/mnt.jw367Y']' returned non-zero exit status 32
kernel: [ 73.702162] 00000050: 00 00 00 01 00 00 18 80 00 00 00 04 00 00 00 00 ................
kernel: [ 73.702550] 00000060: 00 00 06 48 bd a5 10 00 08 00 00 02 00 00 00 00 ...H............
kernel: [ 73.702975] 00000070: 00 00 00 00 00 00 00 00 0c 0c 0b 01 0d 00 00 19 ................
kernel: [ 73.703373] XFS (sdl1): SB validate failed with error -117.
其他出现故障的OSD也存在同样的问题。我们希望数据本身仍然存在,只有XFS分区的挂载失败了。该Ceph群集最初于2017年安装的Ceph jewel 10.2版本。主要是用于文件存储的。
但是,后来,我们将磁盘从filestore迁移到了bluestore(使用ceph-disk,而不是现在使用的ceph-volume)。ceph-disk引入了包含OSD基本元数据的100MB XFS分区。考虑到我们还有三个可用的OSD,我们决定研究如何重建失败的OSD。ceph社区的一些朋友向我们分享了XFS分区如何工作的(thanks T1, ormandj + peetaur!)。
在创建备份(通过dd)之后,我们尝试在server1上重新创建这样一个XFS分区。我们注意到,即使安装新创建的XFS分区也失败了:
synpromika@server1 ~ % sudo mkfs.xfs -f -i size=2048 -m uuid="4568c300-ad83-4288-963e-badcd99bf54f" /dev/sdc1
meta-data=/dev/sdc1 isize=2048 agcount=4, agsize=6272 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=0
data = bsize=4096 blocks=25088, imaxpct=25
= sunit=128 swidth=64 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=1608, versinotallow=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
synpromika@server1 ~ % sudo mount /dev/sdc1 /mnt/ceph-recovery
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0x0/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x0/0x1000
cache_node_purge: refcount was 1, not zero (node=0x1d3c400)
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0x18800/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x18800/0x1000
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0x0/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x0/0x1000
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0x24c00/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x24c00/0x1000
SB stripe unit sanity check failed
Metadata corruption detected at 0x433840, xfs_sb block 0xc400/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0xc400/0x1000
releasing dirty buffer (bulk) to free list!releasing dirty buffer (bulk) to free list!releasing dirty buffer (bulk) to free list!releasing dirty buffer (bulk) to free list!found dirty buffer (bulk) on free list!bad magic number
bad magic number
Metadata corruption detected at 0x433840, xfs_sb block 0x0/0x1000
libxfs_writebufr: write verifer failed on xfs_sb bno 0x0/0x1000
releasing dirty buffer (bulk) to free list!mount: /mnt/ceph-recovery: wrong fs type, bad option, bad superblock on /dev/sdc1, missing codepage or helper program, or other error.
这看起来与我们看到的实际问题非常相关。所以我们尝试执行mkfs。xfs有一系列不同的sunit/swidth配置。使用'-d sunit=512-d swidth=512'至少在当时是有效的,所以我们决定在创建OSD XFS分区时强制使用它。这为我们带来了一个工作的XFS分区。
请注意,sunit不得大于swidth(稍后将详细介绍!)。然后我们重建了如何恢复OSD的所有元数据(activate.monmap、active、block_uuid、bluefs、ceph_fsid、fsid、keyring、kv_backend、magic、mkfs_done、ready、require_OSD_release、systemd、type、whoami)。为了识别UUID,我们可以从“ceph--format json osd dump”读取数据,就像我们所有osd的数据一样:
synpromika@server1 ~ % for f in {0..37} ; printf "osd-$f: %s\n" "$(sudo ceph --format json osd dump | jq -r ".osds[] | select(.osd==$f) | .uuid")"
osd-0: 4568c300-ad83-4288-963e-badcd99bf54f
osd-1: e573a17a-ccde-4719-bdf8-eef66903ca4f
osd-2: 0e1b2626-f248-4e7d-9950-f1a46644754e
osd-3: 1ac6a0a2-20ee-4ed8-9f76-d24e900c800c
[...]可以通过以下方式为每个OSD UUID识别相应的原始设备:
synpromika@server1 ~ % UUID="4568c300-ad83-4288-963e-badcd99bf54f"
synpromika@server1 ~ % readlink -f /dev/disk/by-partuuid/"${UUID}"
/dev/sdc1
可以通过以下方式查询 OSD 的key ID:
synpromika@server1 ~ % OSD_ID=0
synpromika@server1 ~ % sudo ceph auth get osd."${OSD_ID}" -f json 2>/dev/null | jq -r '.[] | .key'
AQCKFpZdm0We[...]
现在我们还需要确定底层块设备:
synpromika@server1 ~ % OSD_ID=0
synpromika@server1 ~ % sudo ceph osd metadata osd."${OSD_ID}" -f json | jq -r '.bluestore_bdev_partition_path'
/dev/sdc2
通过所有这些,我们重建了keyring、fsid、whoami、block+block_uid文件。XFS元数据分区中的所有其他文件在每个OSD上都是相同的。
因此,为了Ceph的使用,在XFS分区上放置并调整了相应的元数据之后,我们得到了一个可以工作的OSD!因为我们还需要修复另外32个OSD,所以我们决定自动化这个XFS分区和元数据恢复过程。
我们在/srv/backup上有一个网络共享,用于存储现有分区数据的备份。在每台服务器上,我们都使用一个OSD测试该过程,然后再遍历剩余的失败OSD列表。
我们从server1上的shell脚本开始,然后调整了server2和server3的脚本。这是我们在第三台服务器上执行的脚本。
#!/bin/bash
set -eu -o pipefail
case $(hostname) in
server1)
# FIXME:
# OSD_ID_LIST=30
# OSD_ID_LIST="0 2 3 4 5 18 20 28 29 30 31"
echo "Error: server1 has been finished." >&2
exit 1
;;
server2)
# FIXME:
# OSD_ID_LIST="6 7 8 9 10 11 32 33 34"
echo "Error: server2 has been finished." >&2
exit 1
;;
server3)
# FIXME:
#OSD_ID_LIST="12"
OSD_ID_LIST="13 14 15 16 17 23 24 25 35 36 37"
;;
*)
echo "Error: this is an unsupported host." >&2
exit 1
;;
esac
if ! mountpoint /srv/backup &>/dev/null ; then
echo "Error: /srv/backup is not a mountpoint." >&2
exit 1
fi
sudo mkdir -p /srv/backup/ceph_recovery
sudo chown root:synpro /srv/backup/ceph_recovery
sudo chmod 770 /srv/backup/ceph_recovery
sudo mkdir -p /mnt/ceph-recovery
for OSD_ID in ${OSD_ID_LIST} ; do
echo "Executing for OSD ID ${OSD_ID}"
if ! sudo ceph osd tree down | egrep -q "osd.${OSD_ID} \s+down" ; then
echo "Error: ceph OSD ${OSD_ID} is not down, Exiting." >&2
exit 1
fi
UUID="$(sudo ceph --format json osd dump | jq -r ".osds[] | select(.osd==${OSD_ID}) | .uuid")"
RAW_DEVICE="$(readlink -f /dev/disk/by-partuuid/"${UUID}")"
BASE_DEV="$(basename "${RAW_DEVICE}")"
if [ -f "/srv/backup/ceph_recovery/${BASE_DEV}_${UUID}.dd" ] ; then
echo "NOTE: backup file for /srv/backup/ceph_recovery/${BASE_DEV}_${UUID}.dd exists, not overwriting."
else
echo "Creating backup file /srv/backup/ceph_recovery/${BASE_DEV}_${UUID}.dd"
sudo dd if=/dev/disk/by-partuuid/"${UUID}" of="/srv/backup/ceph_recovery/${BASE_DEV}_${UUID}.dd"
fi
if ! [ -r "/srv/backup/ceph_recovery/${BASE_DEV}_${UUID}.dd" ] ; then
echo "Error: backup file /srv/backup/ceph_recovery/${BASE_DEV}_${UUID}.dd does not exist." >&2
exit 1
fi
sudo dd if=/dev/zero of="${RAW_DEVICE}" || true
echo "Executing mkfs.xfs -f -i size=2048 -m uuid=${UUID} ${RAW_DEVICE}"
sudo mkfs.xfs -f -i size=2048 -d sunit=512 -d swidth=512 -m uuid="${UUID}" "${RAW_DEVICE}"
sudo mount "${RAW_DEVICE}" /mnt/ceph-recovery/
for file in activate.monmap active block_uuid bluefs ceph_fsid fsid keyring kv_backend magic mkfs_done ready require_osd_release systemd type whoami ; do
# NOTE - this path needs to be adjusted on each server accordingly!
sudo cp -p /mnt/ceph-data/var/lib/ceph/osd/ceph-34/"${file}" /mnt/ceph-recovery/
done
echo "Generating fsid file:"
echo "${UUID}" | sudo tee /mnt/ceph-recovery/fsid
echo "Generating whoami file:"
echo "${OSD_ID}" | sudo tee /mnt/ceph-recovery/whoami
KEY="$(sudo ceph auth get osd."${OSD_ID}" -f json 2>/dev/null | jq -r '.[] | .key')"
echo "Generating keyring file:"
echo "[osd.$OSD_ID]" | sudo tee /mnt/ceph-recovery/keyring
echo " key = ${KEY}" | sudo tee -a /mnt/ceph-recovery/keyring
BLOCK_DEVICE="$(sudo ceph osd metadata "${OSD_ID}" -f json | jq -r '.bluestore_bdev_partition_path')"
BLK_DEV_UUID="$(sudo blkid "${BLOCK_DEVICE}" -o value -s PARTUUID)"
echo "Generating block symlink:"
sudo ln -s /dev/disk/by-partuuid/${BLK_DEV_UUID} /mnt/ceph-recovery/block
echo "Generating block_uuid file:"
echo "${BLK_DEV_UUID}" | sudo tee /mnt/ceph-recovery/block_uuid
echo "Unmounting /mnt/ceph-recovery/"
sudo umount /mnt/ceph-recovery/
echo "Executing ceph-volume simple scan ${RAW_DEVICE}"
sudo ceph-volume simple scan "${RAW_DEVICE}" || true
done
多亏了这一点,我们成功地使Ceph集群重新启动并运行起来。不过,我们不想在晚上继续Ceph升级,因为我们想知道到底发生了什么,以及系统为什么会这样。RCA(故障回溯)的时间到了!
3、根本原因分析
因此,server2上除了三个OSD之外,其他所有OSD都出现了故障,问题似乎与XFS有关。
因此,我们进行RCA(故障回溯)的出发点是,确定server2与server1+server3的不同之处。我最初的假设是,这与相关控制器的一些固件问题有关(后来证明,我是对的!)。
这些磁盘作为JBOD设备连接到ServeRAID M5210控制器(条带大小为512)。固件状态:
synpromika@server1 ~ % sudo storcli64 /c0 show all | grep '^Firmware'
Firmware Package Build = 24.16.0-0092
Firmware Version = 4.660.00-8156
synpromika@server2 ~ % sudo storcli64 /c0 show all | grep '^Firmware'
Firmware Package Build = 24.21.0-0112
Firmware Version = 4.680.00-8489
synpromika@server3 ~ % sudo storcli64 /c0 show all | grep '^Firmware'
Firmware Package Build = 24.16.0-0092
Firmware Version = 4.660.00-8156
这看起来非常有希望,因为server2确实在控制器上使用不同的固件版本运行。但怎么会这样呢?
好的,server2的主板在2020年1月被一名联想/IBM技术人员更换,因为在内存升级过程中,我们的内存插槽出现了故障。作为本程序的一部分,联想/IBM技术人员安装了最新的固件版本。根据我们的文档,一些OSD在2020年3月和4月重建(由于filestore->bluestore迁移)。
事实证明,正是这些OSD在升级中幸存了下来。因此,幸存的驱动器是使用在相关控制器上运行的不同固件版本创建的。所有其他OSD都是使用较旧的控制器固件创建的。但这又有什么区别呢?
现在,让我们检查固件更改日志。24.21.0-0097我们发现:
- Cannot create or mount xfs filesystem using xfsprogs 4.19.x kernel 4.20(SCGCQ02027889)
- xfs_info command run on an XFS file system created on a VD of strip size 1M shows sunit and swidth as 0(SCGCQ02056038)
我们的XFS问题当然与控制器的固件有关。我们还记得,我们的监控系统报告了3月和4月重建的OSD的不同sunit设置。例如,OSD 21被重新创建并获得不同的sunit设置:
WARN server2.example.org Mount options of /var/lib/ceph/osd/ceph-21 WARN - Missing: sunit=1024, Exceeding: sunit=512
我们将新OSD 21与现有OSD(server3上的OSD 25)进行了比较:
synpromika@server2 ~ % systemctl show var-lib-ceph-osd-ceph\\x2d21.mount | grep sunit
Optinotallow=rw,noatime,attr2,inode64,sunit=512,swidth=512,noquota
synpromika@server3 ~ % systemctl show var-lib-ceph-osd-ceph\\x2d25.mount | grep sunit
Optinotallow=rw,noatime,attr2,inode64,sunit=1024,swidth=512,noquota
由于我们的文档,我们可以比较它们创建的执行日志:
% diff -u ceph-disk-osd-25.log ceph-disk-osd-21.log
-synpromika@server2 ~ % sudo ceph-disk -v prepare --bluestore /dev/sdj --osd-id 25
+synpromika@server3 ~ % sudo ceph-disk -v prepare --bluestore /dev/sdi --osd-id 21
[...]
-command_check_call: Running command: /sbin/mkfs -t xfs -f -i size=2048 -- /dev/sdj1
-meta-data=/dev/sdj1 isize=2048 agcount=4, agsize=6272 blks
[...]
+command_check_call: Running command: /sbin/mkfs -t xfs -f -i size=2048 -- /dev/sdi1
+meta-data=/dev/sdi1 isize=2048 agcount=4, agsize=6336 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0, rmapbt=0, reflink=0
-data = bsize=4096 blocks=25088, imaxpct=25
- = sunit=128 swidth=64 blks
+data = bsize=4096 blocks=25344, imaxpct=25
+ = sunit=64 swidth=64 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=1608, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[...]
那时候,我们甚至试图追查到这一点,但还没有弄明白。但现在这听起来很像与我们看到的Ceph/XFS故障相关。
我们遵循Occam的razor,假设最简单的解释通常是正确的,那么让我们检查磁盘属性,看看有什么不同:
synpromika@server1 ~ % sudo blockdev --getsz --getsize64 --getss --getpbsz --getiomin --getioopt /dev/sdk
4685545472
2398999281664
512
4096
524288
262144
synpromika@server2 ~ % sudo blockdev --getsz --getsize64 --getss --getpbsz --getiomin --getioopt /dev/sdk
4685545472
2398999281664
512
4096
262144
262144
请参阅server1和server2之间相同磁盘的区别?getiomin选项现在为他们报告了一些不同的内容:
synpromika@server1 ~ % sudo blockdev --getiomin /dev/sdk
524288
synpromika@server1 ~ % cat /sys/block/sdk/queue/minimum_io_size
524288
synpromika@server2 ~ % sudo blockdev --getiomin /dev/sdk
262144
synpromika@server2 ~ % cat /sys/block/sdk/queue/minimum_io_size
262144
最小I/O大小(iomin,又名BLKIOMIN)大于最佳I/O大小(ioopt,又名BLKIOOPT)是没有意义的。这导致我们遇到了Bug 202127–无法在597T设备上安装或创建xfs,这与我们的发现相匹配。但是为什么这个XFS分区在过去可以工作,而在新的内核版本中却失败了呢?
4、XFS的行为改变
现在,我们已经有了所有XFS分区的备份,我们想要追踪,a)何时引入了这种XFS行为,b)是否可以重用XFS分区,如果可以,如何重用XFS分区,而不必从头开始重建(例如,如果您没有可用的Ceph OSD或备份)。
让我们看一下Grml live系统中失败的XFS分区:
root@grml ~ # grml-version
grml64-full 2020.06 Release Codename Ausgehfuahangl [2020-06-24]
root@grml ~ # uname -a
Linux grml 5.6.0-2-amd64 #1 SMP Debian 5.6.14-2 (2020-06-09) x86_64 GNU/Linux
root@grml ~ # grml-hostname grml-2020-06
Setting hostname to grml-2020-06: done
root@grml ~ # exec zsh
root@grml-2020-06 ~ # dpkg -l xfsprogs util-linux
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version Architecture Description
+++-==============-============-============-=========================================
ii util-linux 2.35.2-4 amd64 miscellaneous system utilities
ii xfsprogs 5.6.0-1+b2 amd64 Utilities for managing the XFS filesystem
无论我们尝试哪种挂载选项,它都会失败:
root@grml-2020-06 ~ # mount ./sdd1.dd /mnt
mount: /mnt: mount(2) system call failed: Structure needs cleaning.
root@grml-2020-06 ~ # dmesg | tail -30
[...]
[ 64.788640] XFS (loop1): SB stripe unit sanity check failed
[ 64.788671] XFS (loop1): Metadata corruption detected at xfs_sb_read_verify+0x102/0x170 [xfs], xfs_sb block 0xffffffffffffffff
[ 64.788671] XFS (loop1): Unmount and run xfs_repair
[ 64.788672] XFS (loop1): First 128 bytes of corrupted metadata buffer:
[ 64.788673] 00000000: 58 46 53 42 00 00 10 00 00 00 00 00 00 00 62 00 XFSB..........b.
[ 64.788674] 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
[ 64.788675] 00000020: 32 b6 dc 35 53 b7 44 96 9d 63 30 ab b3 2b 68 36 2..5S.D..c0..+h6
[ 64.788675] 00000030: 00 00 00 00 00 00 40 08 00 00 00 00 00 00 01 00 ......@.........
[ 64.788675] 00000040: 00 00 00 00 00 00 01 01 00 00 00 00 00 00 01 02 ................
[ 64.788676] 00000050: 00 00 00 01 00 00 18 80 00 00 00 04 00 00 00 00 ................
[ 64.788677] 00000060: 00 00 06 48 bd a5 10 00 08 00 00 02 00 00 00 00 ...H............
[ 64.788677] 00000070: 00 00 00 00 00 00 00 00 0c 0c 0b 01 0d 00 00 19 ................
[ 64.788679] XFS (loop1): SB validate failed with error -117.
root@grml-2020-06 ~ # mount -t xfs -o rw,relatime,attr2,inode64,sunit=1024,swidth=512,noquota ./sdd1.dd /mnt/
mount: /mnt: wrong fs type, bad option, bad superblock on /dev/loop1, missing codepage or helper program, or other error.
32 root@grml-2020-06 ~ # dmesg | tail -1
[ 66.342976] XFS (loop1): stripe width (512) must be a multiple of the stripe unit (1024)
root@grml-2020-06 ~ # mount -t xfs -o rw,relatime,attr2,inode64,sunit=512,swidth=512,noquota ./sdd1.dd /mnt/
mount: /mnt: mount(2) system call failed: Structure needs cleaning.
32 root@grml-2020-06 ~ # dmesg | tail -14
[ 66.342976] XFS (loop1): stripe width (512) must be a multiple of the stripe unit (1024)
[ 80.751277] XFS (loop1): SB stripe unit sanity check failed
[ 80.751323] XFS (loop1): Metadata corruption detected at xfs_sb_read_verify+0x102/0x170 [xfs], xfs_sb block 0xffffffffffffffff
[ 80.751324] XFS (loop1): Unmount and run xfs_repair
[ 80.751325] XFS (loop1): First 128 bytes of corrupted metadata buffer:
[ 80.751327] 00000000: 58 46 53 42 00 00 10 00 00 00 00 00 00 00 62 00 XFSB..........b.
[ 80.751328] 00000010: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
[ 80.751330] 00000020: 32 b6 dc 35 53 b7 44 96 9d 63 30 ab b3 2b 68 36 2..5S.D..c0..+h6
[ 80.751331] 00000030: 00 00 00 00 00 00 40 08 00 00 00 00 00 00 01 00 ......@.........
[ 80.751331] 00000040: 00 00 00 00 00 00 01 01 00 00 00 00 00 00 01 02 ................
[ 80.751332] 00000050: 00 00 00 01 00 00 18 80 00 00 00 04 00 00 00 00 ................
[ 80.751333] 00000060: 00 00 06 48 bd a5 10 00 08 00 00 02 00 00 00 00 ...H............
[ 80.751334] 00000070: 00 00 00 00 00 00 00 00 0c 0c 0b 01 0d 00 00 19 ................
[ 80.751338] XFS (loop1): SB validate failed with error -117.
此外,xfs_repair也没有帮助:
root@grml-2020-06 ~ # xfs_info ./sdd1.dd
meta-data=./sdd1.dd isize=2048 agcount=4, agsize=6272 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0, rmapbt=0
= reflink=0
data = bsize=4096 blocks=25088, imaxpct=25
= sunit=128 swidth=64 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=1608, versinotallow=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
root@grml-2020-06 ~ # xfs_repair ./sdd1.dd
Phase 1 - find and verify superblock...
bad primary superblock - bad stripe width in superblock !!!
attempting to find secondary superblock...
..............................................................................................Sorry, could not find valid secondary superblock
Exiting now.
通过“SB stripe unit sanity check failed”(SB条带单元健全性检查失败)消息,我们可以轻松跟踪到以下提交fa4ca9c:
% git show fa4ca9c5574605d1e48b7e617705230a0640b6da | cat
commit fa4ca9c5574605d1e48b7e617705230a0640b6da
Author: Dave Chinner <dchinner@redhat.com>
Date: Tue Jun 5 10:06:16 2018 -0700
xfs: catch bad stripe alignment configurations
When stripe alignments are invalid, data alignment algorithms in the
allocator may not work correctly. Ensure we catch superblocks with
invalid stripe alignment setups at mount time. These data alignment
mismatches are now detected at mount time like this:
XFS (loop0): SB stripe unit sanity check failed
XFS (loop0): Metadata corruption detected at xfs_sb_read_verify+0xab/0x110, xfs_sb block 0xffffffffffffffff
XFS (loop0): Unmount and run xfs_repair
XFS (loop0): First 128 bytes of corrupted metadata buffer:
0000000091c2de02: 58 46 53 42 00 00 10 00 00 00 00 00 00 00 10 00 XFSB............
0000000023bff869: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00000000cdd8c893: 17 32 37 15 ff ca 46 3d 9a 17 d3 33 04 b5 f1 a2 .27...F=...3....
000000009fd2844f: 00 00 00 00 00 00 00 04 00 00 00 00 00 00 06 d0 ................
0000000088e9b0bb: 00 00 00 00 00 00 06 d1 00 00 00 00 00 00 06 d2 ................
00000000ff233a20: 00 00 00 01 00 00 10 00 00 00 00 01 00 00 00 00 ................
000000009db0ac8b: 00 00 03 60 e1 34 02 00 08 00 00 02 00 00 00 00 ...`.4..........
00000000f7022460: 00 00 00 00 00 00 00 00 0c 09 0b 01 0c 00 00 19 ................
XFS (loop0): SB validate failed with error -117.
And the mount fails.
Signed-off-by: Dave Chinner <dchinner@redhat.com>
Reviewed-by: Carlos Maiolino <cmaiolino@redhat.com>
Reviewed-by: Darrick J. Wong <darrick.wong@oracle.com>
Signed-off-by: Darrick J. Wong <darrick.wong@oracle.com>
diff --git fs/xfs/libxfs/xfs_sb.c fs/xfs/libxfs/xfs_sb.c
index b5dca3c8c84d..c06b6fc92966 100644
--- fs/xfs/libxfs/xfs_sb.c
+++ fs/xfs/libxfs/xfs_sb.c
@@ -278,6 +278,22 @@ xfs_mount_validate_sb(
return -EFSCORRUPTED;
}
+ if (sbp->sb_unit) {
+ if (!xfs_sb_version_hasdalign(sbp) ||
+ sbp->sb_unit > sbp->sb_width ||
+ (sbp->sb_width % sbp->sb_unit) != 0) {
+ xfs_notice(mp, "SB stripe unit sanity check failed");
+ return -EFSCORRUPTED;
+ }
+ } else if (xfs_sb_version_hasdalign(sbp)) {
+ xfs_notice(mp, "SB stripe alignment sanity check failed");
+ return -EFSCORRUPTED;
+ } else if (sbp->sb_width) {
+ xfs_notice(mp, "SB stripe width sanity check failed");
+ return -EFSCORRUPTED;
+ }
+
+
if (xfs_sb_version_hascrc(&mp->m_sb) &&
sbp->sb_blocksize < XFS_MIN_CRC_BLOCKSIZE) {
xfs_notice(mp, "v5 SB sanity check failed");
此更改包含在内核版本4.18-rc1及更新版本中:
% git describe --contains fa4ca9c5574605d1e48
v4.18-rc1~37^2~14
现在,让我们使用旧的Grml 2017.05版本,尝试使用旧的内核版本(4.9.0):
root@grml ~ # grml-version
grml64-small 2017.05 Release Codename Freedatensuppe [2017-05-31]
root@grml ~ # uname -a
Linux grml 4.9.0-1-grml-amd64 #1 SMP Debian 4.9.29-1+grml.1 (2017-05-24) x86_64 GNU/Linux
root@grml ~ # lsb_release -a
No LSB modules are available.
Distributor ID: Debian
Description: Debian GNU/Linux 9.0 (stretch)
Release: 9.0
Codename: stretch
root@grml ~ # grml-hostname grml-2017-05
Setting hostname to grml-2017-05: done
root@grml ~ # exec zsh
root@grml-2017-05 ~ #
root@grml-2017-05 ~ # xfs_info ./sdd1.dd
xfs_info: ./sdd1.dd is not a mounted XFS filesystem
1 root@grml-2017-05 ~ # xfs_repair ./sdd1.dd
Phase 1 - find and verify superblock...
bad primary superblock - bad stripe width in superblock !!!
attempting to find secondary superblock...
..............................................................................................Sorry, could not find valid secondary superblock
Exiting now.
1 root@grml-2017-05 ~ # mount ./sdd1.dd /mnt
root@grml-2017-05 ~ # mount -t xfs
/root/sdd1.dd on /mnt type xfs (rw,relatime,attr2,inode64,sunit=1024,swidth=512,noquota)
root@grml-2017-05 ~ # ls /mnt
activate.monmap active block block_uuid bluefs ceph_fsid fsid keyring kv_backend magic mkfs_done ready require_osd_release systemd type whoami
root@grml-2017-05 ~ # xfs_info /mnt
meta-data=/dev/loop1 isize=2048 agcount=4, agsize=6272 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1 spinodes=0 rmapbt=0
= reflink=0
data = bsize=4096 blocks=25088, imaxpct=25
= sunit=128 swidth=64 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=1608, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
现在,如果我们使用旧的内核使用新的和正确的sunit/swidth设置挂载文件系统,它应该在磁盘上重写它们:
root@grml-2017-05 ~ # mount -t xfs -o sunit=512,swidth=512 ./sdd1.dd /mnt/
root@grml-2017-05 ~ # umount /mnt/
事实上,挂载这个rewritten的文件系统也适用于较新的内核:
root@grml-2020-06 ~ # mount ./sdd1.rewritten /mnt/
root@grml-2020-06 ~ # xfs_info /root/sdd1.rewritten
meta-data=/dev/loop1 isize=2048 agcount=4, agsize=6272 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0, rmapbt=0
= reflink=0
data = bsize=4096 blocks=25088, imaxpct=25
= sunit=64 swidth=64 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=1608, versinotallow=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
root@grml-2020-06 ~ # mount -t xfs
/root/sdd1.rewritten on /mnt type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,sunit=512,swidth=512,noquota)
FTR:xfs mount选项中的'sunit=512,swidth=512'与xfs_info的输出'sunit=64,swidth=64'相同(因为mount.xfs的sunit值是以512字节块单位给出的,请参见man 5 xfs,这里报告的xfs_info输出是以块大小(bsize)为4096的块为单位的,所以'sunit=512512:=644096')。
mkfs为 stripe unit and stripe width使用最小和最佳大小;您可以通过以下方式进行检查(请注意,固件版本中,server2报告正确的值,而控制器固件损坏的server3报告无意义):
synpromika@server2 ~ % for i in /sys/block/sd*/queue/ ; do printf "%s: %s %s\n" "$i" "$(cat "$i"/minimum_io_size)" "$(cat "$i"/optimal_io_size)" ; done
[...]
/sys/block/sdc/queue/: 262144 262144
/sys/block/sdd/queue/: 262144 262144
/sys/block/sde/queue/: 262144 262144
/sys/block/sdf/queue/: 262144 262144
/sys/block/sdg/queue/: 262144 262144
/sys/block/sdh/queue/: 262144 262144
/sys/block/sdi/queue/: 262144 262144
/sys/block/sdj/queue/: 262144 262144
/sys/block/sdk/queue/: 262144 262144
/sys/block/sdl/queue/: 262144 262144
/sys/block/sdm/queue/: 262144 262144
/sys/block/sdn/queue/: 262144 262144
[...]
synpromika@server3 ~ % for i in /sys/block/sd*/queue/ ; do printf "%s: %s %s\n" "$i" "$(cat "$i"/minimum_io_size)" "$(cat "$i"/optimal_io_size)" ; done
[...]
/sys/block/sdc/queue/: 524288 262144
/sys/block/sdd/queue/: 524288 262144
/sys/block/sde/queue/: 524288 262144
/sys/block/sdf/queue/: 524288 262144
/sys/block/sdg/queue/: 524288 262144
/sys/block/sdh/queue/: 524288 262144
/sys/block/sdi/queue/: 524288 262144
/sys/block/sdj/queue/: 524288 262144
/sys/block/sdk/queue/: 524288 262144
/sys/block/sdl/queue/: 524288 262144
/sys/block/sdm/queue/: 524288 262144
/sys/block/sdn/queue/: 524288 262144
[...]
这就是最初创建的XFS分区使用不正确的sunit/swidth设置创建的根本原因。server1和server3的固件损坏是错误的原因——在旧的xfs/内核版本中忽略了它们,但新版本却直接报错。
请务必阅读XFS常见问题解答“如何计算正确的sunit、swidth值以获得最佳性能”。在RedHat的知识库中,我们还偶然发现了两个有趣的文章:5075561+215001(需要订阅)和#1835947。
5、我受到影响了吗?如何解决这个问题?
要检查XFS挂载是否受此问题的影响,请使用以下命令行:
awk '$3 == "xfs"{print $2}' /proc/self/mounts | while read mount ; do echo -n "$mount " ; xfs_info $mount | awk '$0 ~ "swidth"{gsub(/.*=/,"",$2); gsub(/.*=/,"",$3); print $2,$3}' | awk '{ if ($1 > $2) print "impacted"; else print "OK"}' ; done如果您遇到上述情况,使原始XFS分区重新工作的唯一已知解决方案是重新引导到较旧的内核版本(4.17或更旧),使用正确的sunit/swidth设置挂载XFS分区,然后重新引导到新系统(内核版本)。
6、经验教训
记录所有内容并确保所有相关信息可用(包括实际更改时间、使用的内核/软件包/固件/…版本)。完整的文档是我们在本案例中最重要的资产,因为我们有紧急处理期间以及RCA(故障回溯)期间所需的所有数据和信息
如果发生意外故障,请深入挖掘故障原因
知道该问谁,一个专家级的技术支持能够少走很多弯路
在shell中包含时间戳使重建更容易(涉及的人员和文档越多,就越难完成重建)
密切关注变更日志/发行说明
应用定期更新,不要忘记不可见层(例如BIOS、控制器/磁盘固件、IPMI/OOB(ILO/RAC/IMM/…)固件)
应用定期重新启动,以避免可能的增量问题(这也会使调试更加困难)
原文: https://michael-prokop.at/blog/2021/04/09/a-ceph-war-story/