













数据库中表存在重复数据,需要清理重复数据,清理后保留其中一条的情况是比较常见的需求,如何通过1条SQL准确的删除数据呢?
1. 创建表及测试数据
1.1 数据库中创建一张测试表
1.2 插入测试数据
1.3 查看重复数据
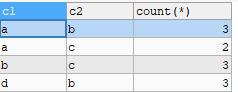
例如c1,c2 这2个字段组合作为唯一条件,则查询重复数据的SQL如下
可见,结果如下:
2. 如何删除重复数据
2.1 方案一
很多研发同学习惯的思路如下:
- 先查出重复的记录(使用in)
- 再查出在重复记录但id不在每组id最大值的记录
- 直接将select 改为delete进行删除
查询SQL如下
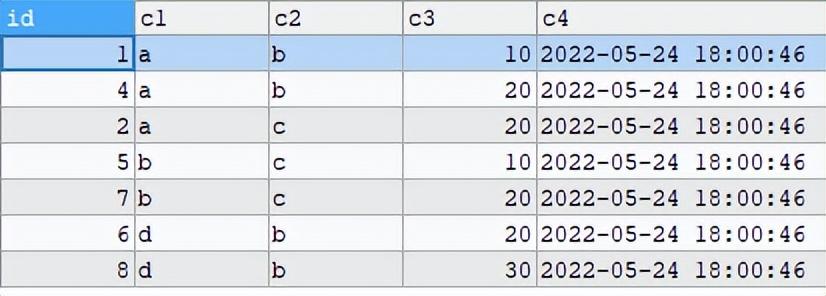
看上去比较符合结果了,但是改为delete执行的时候结果如下:
出现报错信息:
也就是说MySQL里需删除的目标表在in子查询中时,不能直接执行删除操作。
3. 推荐写法
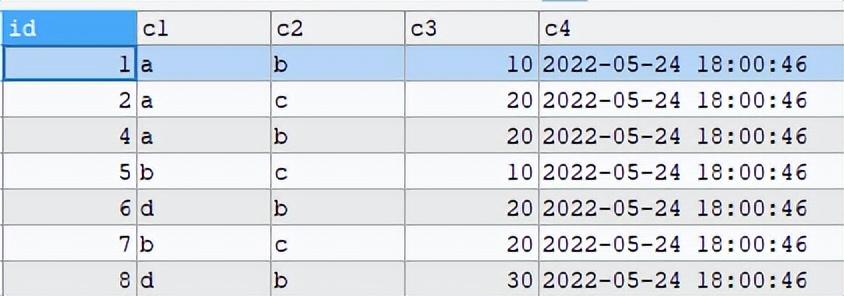
基于以上情况,使用单条SQL删除的方式如下:
查询SQL:
删除SQL
结果:
删除后数据如下:
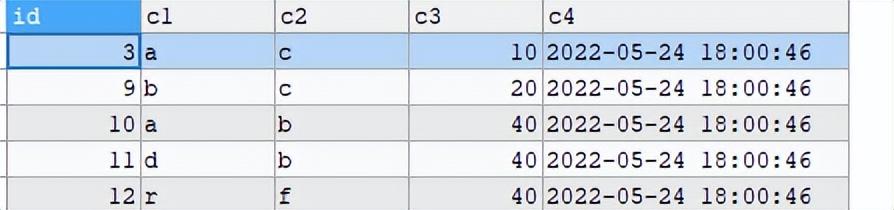
无重复数据了。















