首先明确一点,Spring如果使用二级缓存也是完全能够解决代理bean的循环依赖问题的。那Spring为什么要使用三级缓存的设计呢?在回答这个问题前我们先明确一些概念。
Spring Bean相关的知识
Spring Bean 的创建过程
- 扫描xml或者注解获取BeanDefinition;
- 实例化bean:通过createBeanInstance方法创建bean的原始对象BeanWrapper;
- 注入bean的依赖:利用populateBean方法(本质是反射)注入bean的依赖属性;
- 初始化bean:调用initializeBean方法最终形成完整的bean对象;
Spring Bean 的三级缓存定义
三级缓存的查找策略是,先从一级缓存获取,若获取不到就从二级缓存,仍然获取不到则从三级缓存获取,若还是获取不到则通过bean对应的BeanDefinition信息实例化。
Tips:二、三级缓存会在DI的过程中被删除,最终所有的Bean都会变成完整的bean并存入一级缓存中。
- 三级缓存singletonFactories:在注入bean的依赖前存入,所有bean都会存入,循环依赖时会使用,代码如下:
- 二级缓存earlySingletonObjects:存放实例化的对象(可能是原始对象也可能是代理对象),代码如下:
- 一级缓存singletonObjects:用于存放完整的bean,代码如下:
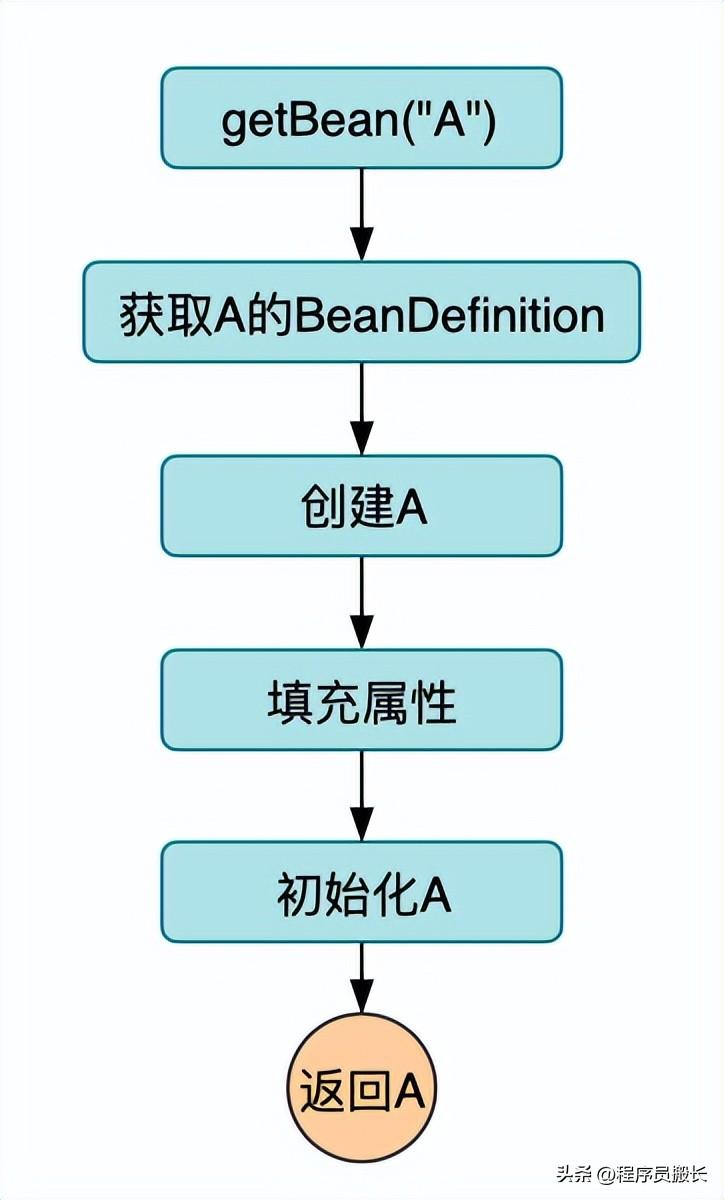
什么是循环依赖?
循环依赖是指:Spring在初始化A的时候需要注入B,而初始化B的时候需要注入A,在Spring启动完成后这俩个对象都必须是完整的bean。
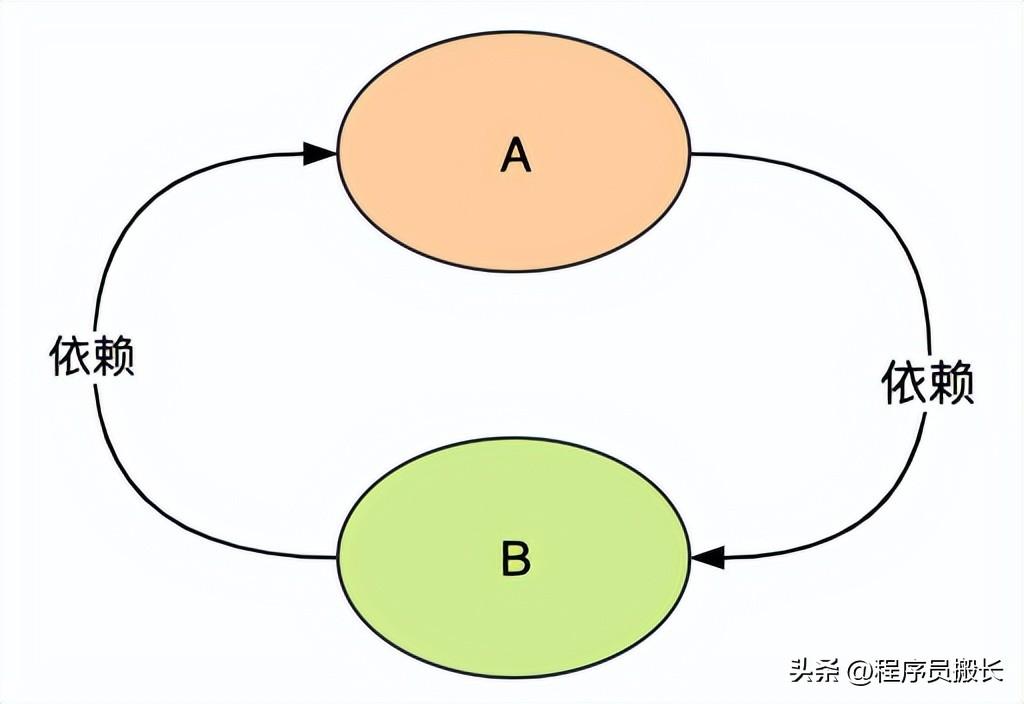
循环依赖的场景有三种:
- 构造器循环依赖:Spring无法解决,因为bean创建的第一步就是通过构造器实例化,也就是说解决循环依赖的前提就是对象可以实例化并缓存,与Java死锁很像;
- prototype范围的依赖:该循环依赖Spring不可解决,prototype作用域的bean Spring不缓存,因此在依赖注入时无法获取到依赖的bean;
- setter循环依赖:该循环依赖是Spring推荐的方式,我们接下来就重点讲解这种方式;
一个简单setter循环依赖的代码示例如下:
Spring 是如何利用多级缓存解决循环依赖的
我们先抛开Spring的实现来做一次解决循环依赖的设计推演。
在没有缓存的情况下循环依赖的场景
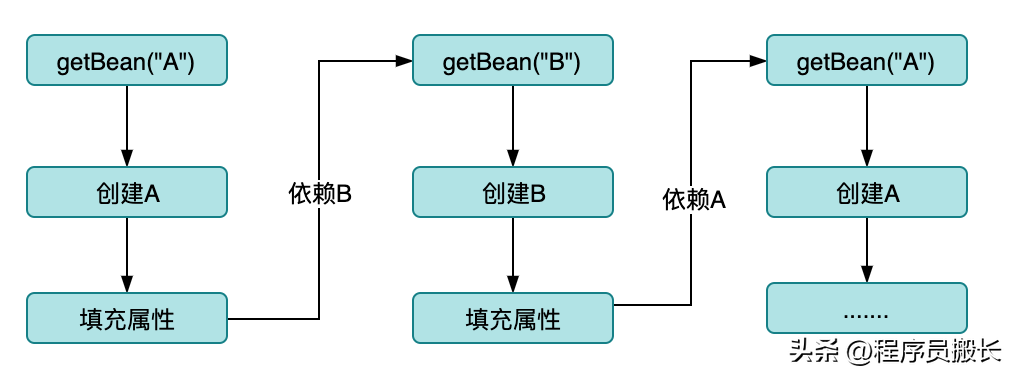
如图可以直接观察到,当没有缓存时,当发生循环依赖时直接死循环了,最终的结局就是StackOverflow或者OOM。
增加一层缓存
为了解决上面循环依赖的问题,我们加入一层缓存,缓存可以使用Map结构,key为beanName,value为对象实例。如下如:
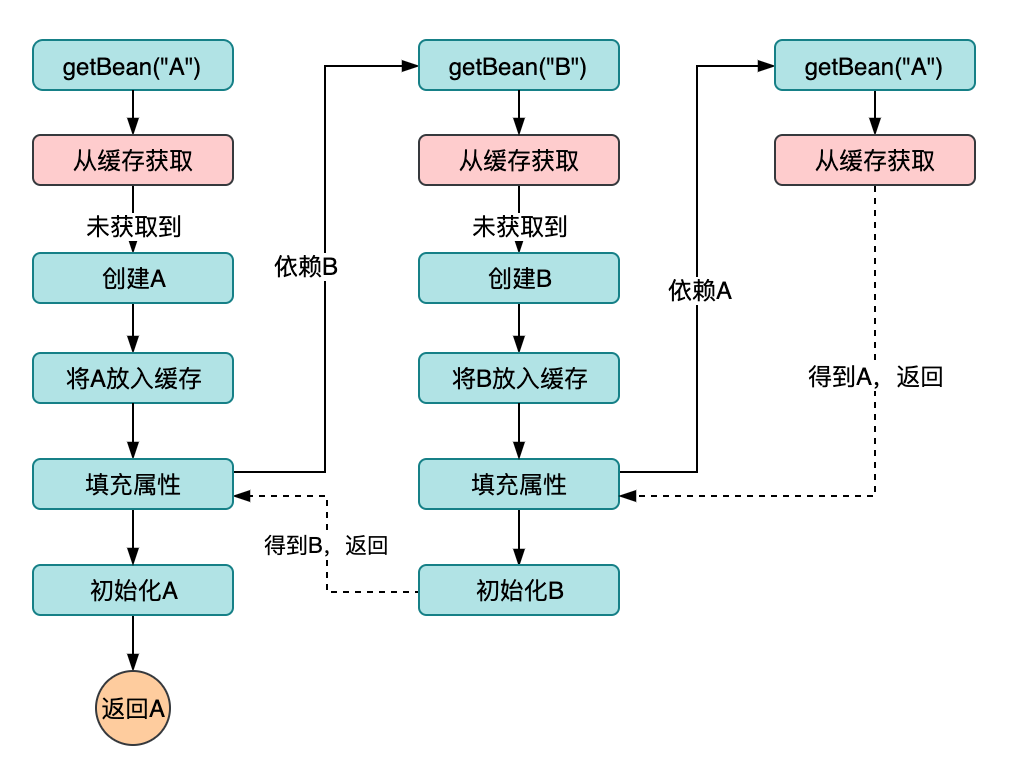
从上图可以直观的看出,循环依赖的问题已经得到了完美解决,但是又有了一个新问题,这个缓存中的bean可能有已经创建完成的、正在创建中还没有注入依赖的,它们都掺杂在一起,我们如何保证Map里面的所有对象是完整的呢?一层缓存很显然不符合设计规范,也缺乏安全性与扩展性。
二级缓存设计
我们希望的是,明确已经构建完成的的Bean被放入到一个缓存中,创建中的bean在另外一个缓存中,于是就有了下面的结构:
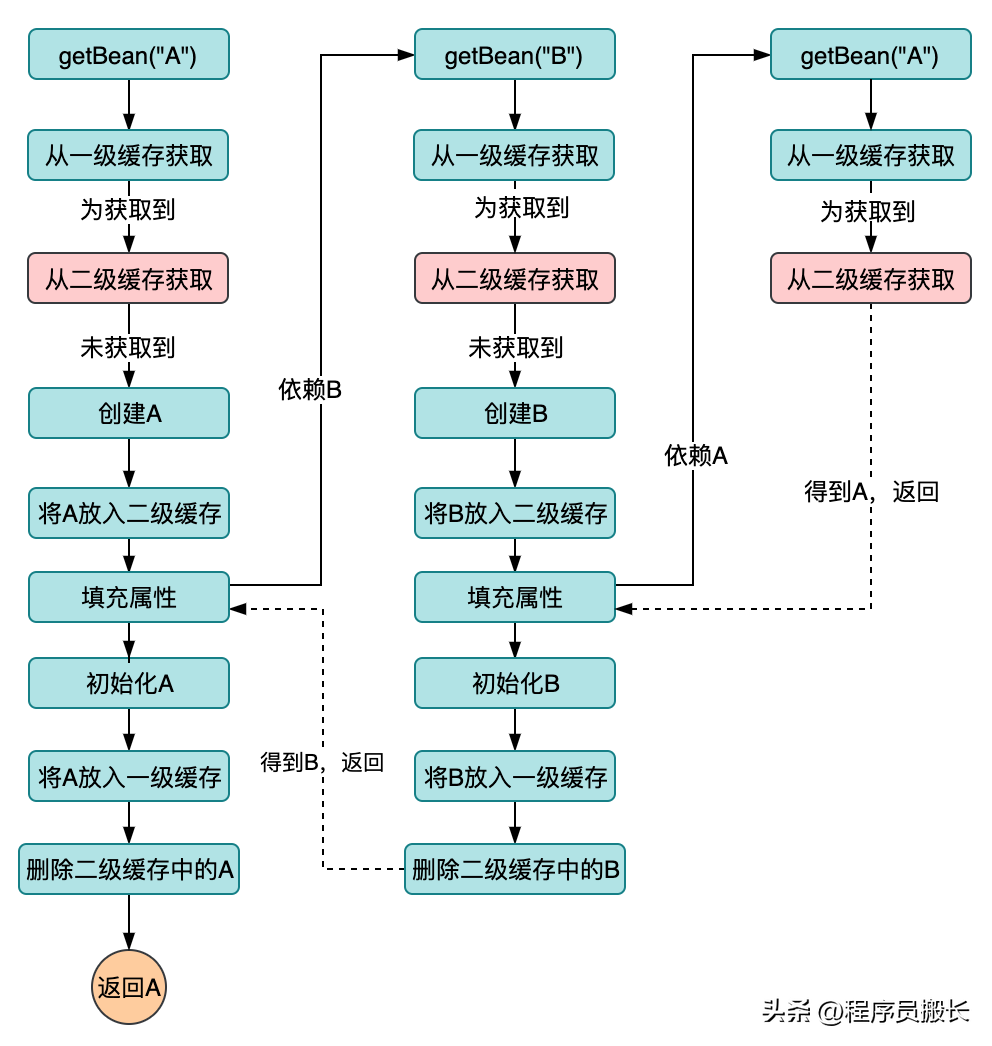
与一级缓存架构设计的区别在于:
- 新增了二级缓存,用于存放刚实例化的bean;
- 当bean初始化完成后会放入一级缓存,同时将bean从二级缓存中的删除(不需要一式两份,保留一份最终完整的Bean即可)
从目前看这个设计完美解决了bean的完整性问题,但是在实际生产中问题总是叠着问题,没有完美的架构设计。我们都知道Java中有代理,而且代理的应用非常广泛,包括在Spring中就有非常多的代理,那问题就来了,我们如何区分代理对象与普通对象?如果循环依赖中存在代理对象的循环依赖会发生什么呢?
代理对象的循环依赖
在现实开发过程中,我们往往会产生很多的代理对象,当存在代理对象加入到循环依赖流程会是什么样的场景,我们来推演一下,我们仍然使用二级缓存的设计来做推演。
如果我们在bean初始化完成之后再创建代理对象,整个流程是这样的:
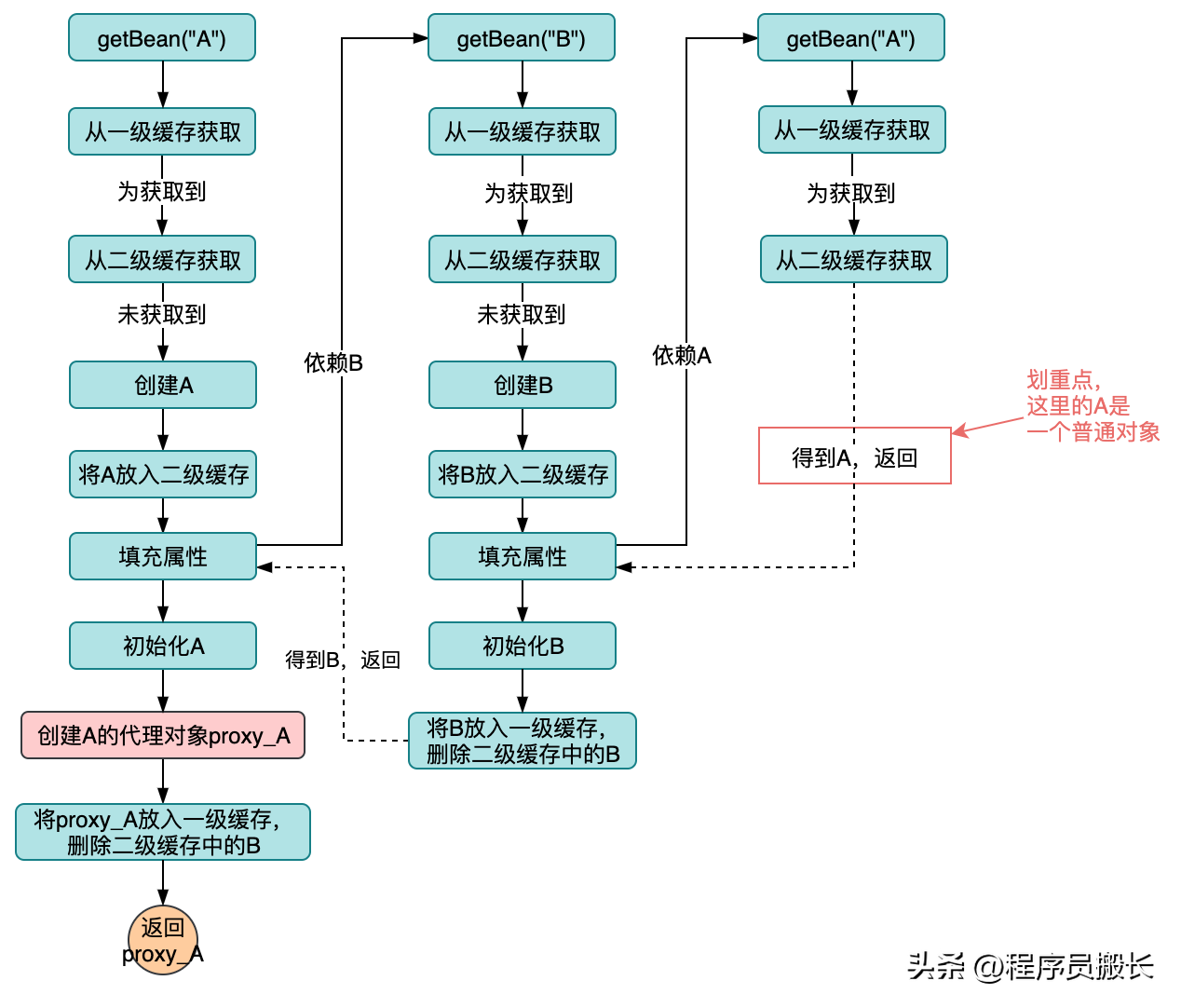
从上图可以非常直观的看出,最终在一级缓存中的对象A是一个proxy_A,但是对象B依赖的对象A却是一个普通A!很明显现有的设计不能够满足代理对象的循环依赖问题。
如何解决这个问题呢?我们还是在上一个设计上做修改:
- 方案一:在获取到A时立即创建代理,如下图(红色部分)所示:
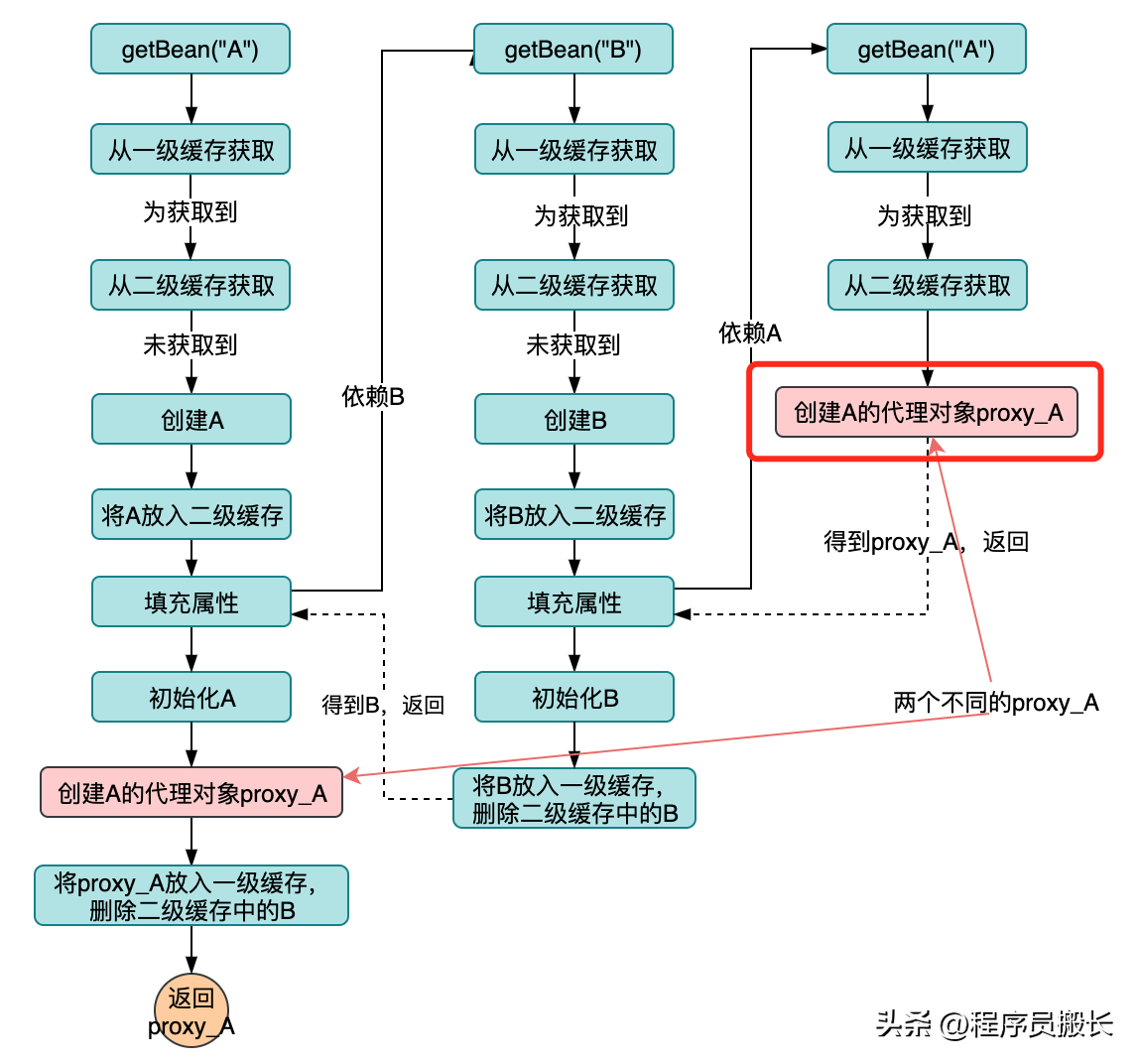
这个方案看起来解决了B对象依赖不到A的proxy对象问题,但是又引起了一个致命的问题,在A初始化完成之后还会创建一次代理对象,那么就创建了两次代理对象,他们是完全不一样的,这个代理对象不是单例的了!
- 方案二:在方案一的基础上,我们是不是可以将创建完的proxy_A对象加入到二级缓存中,直接覆盖掉普通A(代理对象会持有普通对象A的引用,所以可以覆盖):这个方案看上去没有问题,但是从设计角度讲,这不符合设计规范,而且覆盖后的A是个代理对象,在后续的操作中,如果再从二级缓存中获取A,这时候就不知道到底获取到的是普通A还是proxy_A了,这无形增加了判断识别的复杂度。
- 方案三:在首次实例化A的时候就直接创建A的代理对象,并放入二级缓存中:这个方案与方案二有相同的问题,这里不在赘述。
解决代理对象的循环依赖之终极方案
解决代理对象的循环依赖之终极方案-三级缓存!
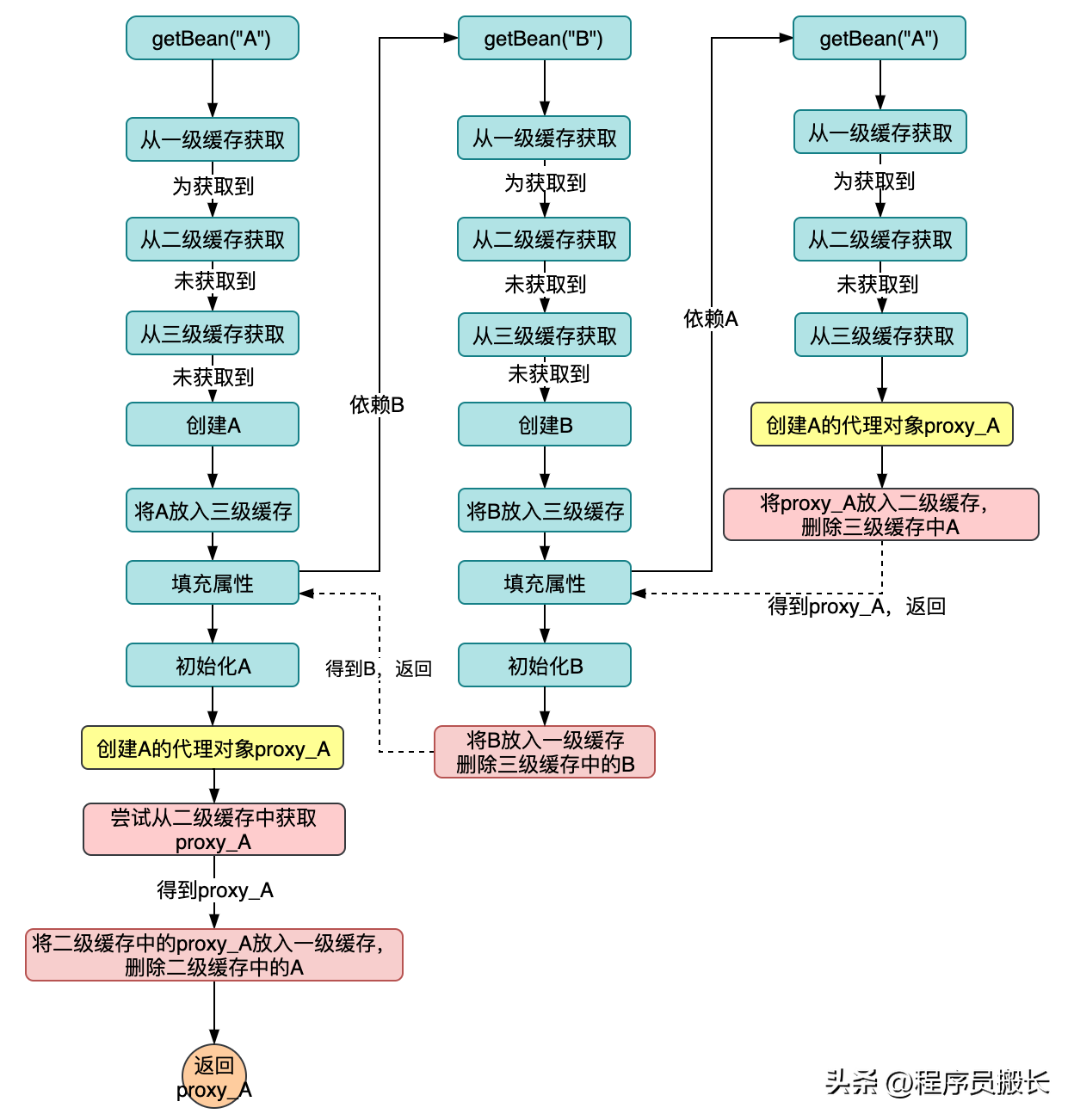
与二级缓存设计最大的不同点在于:
- 在获取到A时创建proxy_A,同时将其加入到二级缓存中,并返回给B,这样B就依赖了proxy_A;
- 在A初始化过程中会创建代理对象,这时候会做一个检查,也就是会去查询二级缓存,看有没有proxy_A的存在,如果有说明proxy_A已经创建,我们会选择二级缓存中的proxy_A存入一级缓存并返回(因为二级缓存中的proxy_A已经被B依赖);
其它流程不在赘述,该设计中最重要的几个地方在Spring中的实现是更加细致的,我在流程途中只是简单概括,下面特殊说明一下几个点。
Spring Bean初始化会产生代理对象的场景
在上述流程中,标记位黄色的部分就是两个代理对象的创建的地方,在Spring中就是这两个后置处理器调用的地方,它们分别是:
- 在调用getEarlyBeanReference时如果实现了BeanPostProcessor则会创建代理对象;
- 另一个地方是在执行Bean初始化initializeBean时执行BeanPostProcessor会创建代理对象;
在Spring中的第三级缓存有更加灵活设计
在Spring中,第三级缓存不仅仅是存入了实例化的对象,而是存入了一个匿名类ObjectFactory,getEarlyBeanReference函数的实现中会调用BeanPostProcessor执行用户自定义的逻辑。具体代码如下:
若初始化阶段的后置处理器对对象做了代理,Spring是如何处理的?
在Spring中若在initializeBean阶段的后置处理器对对象做了代理,那么Spring会对做依赖检查,具体代码如下:
为什么Spring采用三级缓存设计?
我们再回到最初的问题上,其实上述整个设计推演过程就已经很好的回答了这个问题,这里再做一下补充。从上述Spring源码可知,其在第三级缓存中放入的是匿名类ObjectFactory,每次需要获取对象实例就会调用其getObject方法。我们举个例子:
假如现在没有earlySingletonObjects这一层缓存(也就是第二级缓存),也就是两级缓存结构,现在有三个对象,其依赖关系如下A->B、B->A和C、C->A,从这个依赖关系可以得出,A所在的ObjectFactory会被调用两次getObject(),如果两次都返回不同的proxy_A(毕竟后置处理器的代码是使用者自己写的,可能代码是new Proxy(A)),那么就可能导致,B、C对象依赖的proxy_A不是一个对象,那么这种设计是致命的。
这个案例也从侧面反映了三层缓存的设计必要性、必然性,也是为了让框架更加的灵活健壮,以上就是我对Spring bean 三层缓存设计的理解,如有疑问欢迎在评论区讨论留言。