最近同事接手了一个老项目,在简单的做了几个小需求后,经过自测没问题就发布上线了,没想的是,上线没一会监控平台就报警有全表扫描的慢SQL。
因为上线的几个功能使用频率也不高,所以也只是告诉同事慢SQL的情况,让该同事先检查优化。
结果直到快下班,才收到同事提交的新版本。一问,才知道竟然是一个多表关联查询中的两张表的编码方式不一致,导致出现了隐式类型转换,从而去扫描全表了。
而之所以该同事在测试环境使用了各种手段都没有复现线上的场景,是因为测试环境的表编码是一致的,果然老项目处处是坑啊。
今天借着这个问题,带大家了解一下,为什么字符集编码不一致(可能)会发生不走索引扫描全表的问题。(注意,是可能,并非一定)。
首先,我们新建两张表复现一下现场。
请注意table1的字符集编码是utf8,而table2的字符集编码是utf8mb4。
我们执行一条普通的左关联sql:
通过explain查看一下执行计划:
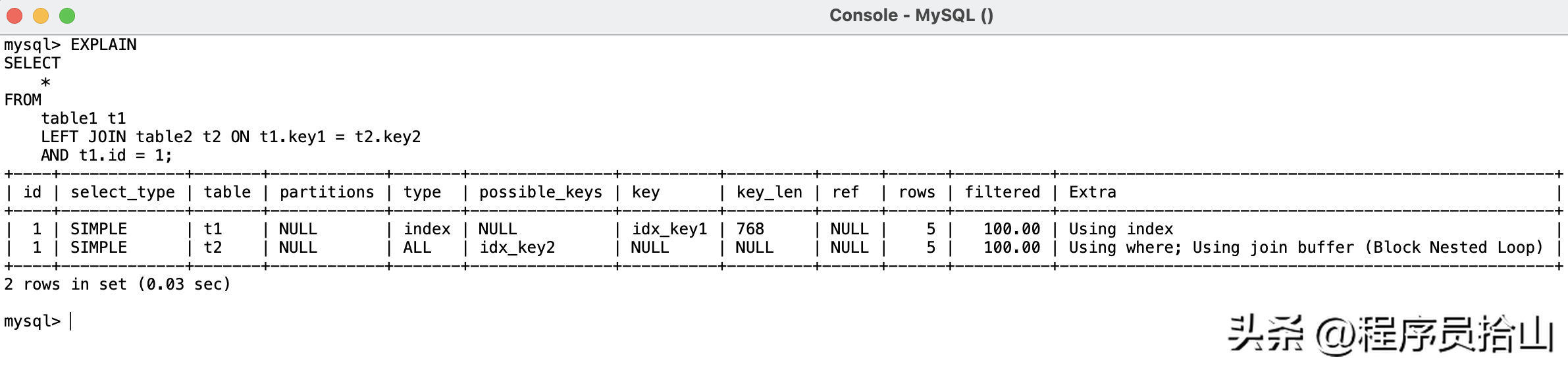
可以看到,table1使用了索引idx_key1,但是table2却没有命中索引,反而执行了全表扫描。
那真的是因为字符集转换导致的索引失效吗?
口说无凭,我们看一下MySQL经过优化器优化的sql:
执行explain select ...之后,再执行show warnings即可看到优化后的sql。
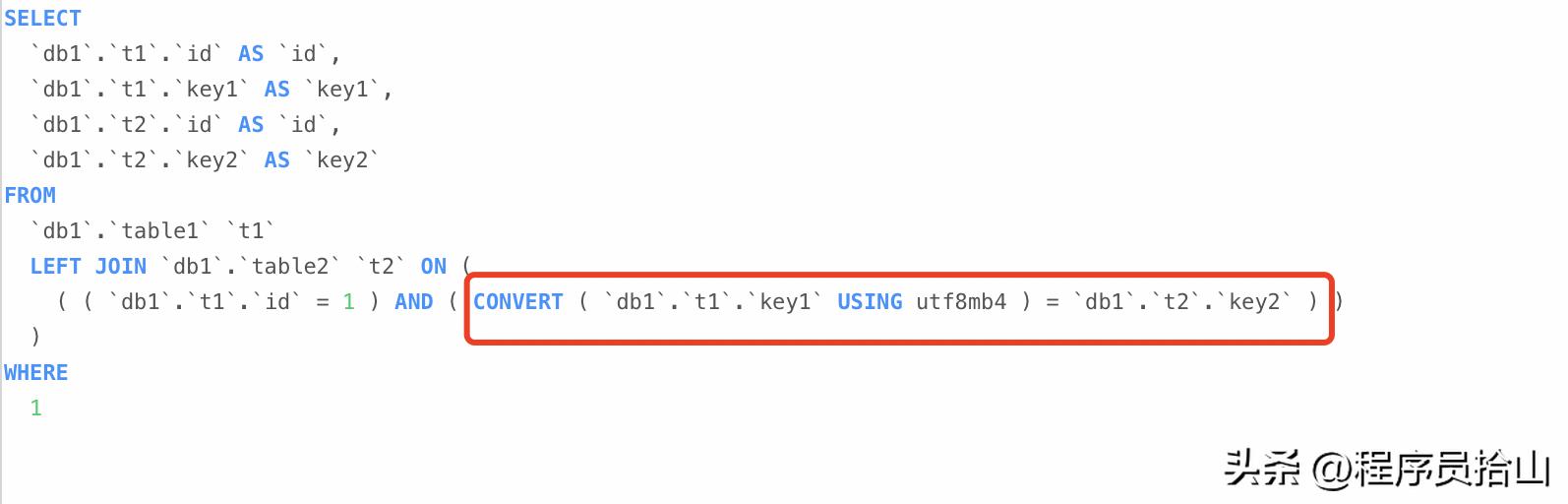
可以清楚的看到,经过优化后的sql,其实是对table1的key1字段做了convert转换,即从utf8转换为utf8mb4。
那有的朋友可能要问了, 明明是对key1字段做的convert,怎么导致table2无法走索引了呢?
其实这是因为此处以table1为驱动表,table2为被驱动表,从table1中查出数据,然后去table2中匹配,但是table1查出来的数据要做类型转换,对于table2来说,无论是索引的等值匹配,还是范围匹配,都需要确定值才行。值不确定,干脆走全表扫描一条条的匹配。
换句话说,相当于执行了下面的sql:
看到这,大家是否回忆起我们经常说的sql优化:
不要在索引字段上函数操作。
这才是索引失效的真正原因。
那这种情况该怎么解决呢?
自然是把表的字符集修改为一致,当然如果数据量很大无法做到online ddl的话,那就尝试改写sql,避免索引字段出现函数操作。当然改写sql不一定能满足所有情况,需要根据实际情况来判断。
我们再回到开头,为什么说字符集编码不一致可能会发生隐私类型转换,而不是一定会发生呢?
这是因为MySQL在背后做了很多的优化工作,帮助我们提前把坑给填上了。
还是上面的sql为例,我们稍微改动一下:
我们修改一下查询条件,将原本条件中的t1.id改为t2.id,再来看一下优化后的sql:

可以看到,table2可以用到主键索引了。
这是因为,通过判断条件中的t2.id=1,已经可以通过主键唯一定位到一条记录了,所以可以直接使用table2的主键索引。当然,table2的key2索引还是用不了的。
一般来说,对索引字段做显示的函数操作,是很容易发现和修正的。
这种字符集编码不一样的情况,确实是防不胜防,只能建议从建表初始,就确定良好的编码规范,统一字符集来避免了。
另外建议大家养成随手explain的习惯,可以在问题发生前避免很多问题。