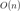自动机概况
使用Linux开发环境的程序员一定使用过sed、grep、lex等Linux系统工具,sed、grep是Linux中重要的数据流搜索与处理工具,Lex是linux下广泛使用的词法分析器生成器,用于复杂语言的解析、编译器前端的开发等。尽管这些Linux系统工具功能各异,但这些工具内部都实现了一个自动机,用于对输入预料进行基于正则表达式的文本搜索。自动机则是正则表达式的等价实现。
从计算理论上讲,正则表达式与自动机具有理论上的严格等价性,正则表达式和自动机具有等价的对匹配模式的定义能力。正则表达式是匹配模式的形式化表达,自动机则是对匹配模式的计算机实现的一种表达。
安全检测与防护领域的入侵检测系统(Intrusion Detection Systems,IDS)、入侵防护系统(Intrusion Prevention System, IPS)、web应用防火墙(Web Application Firewall,WAF)等都大量应用了自动机技术进行网络数据流的正则表达式匹配,以实现对网络报文的检测与分析。

IPS/IDS与WAF系统
自动机技术也广泛应用于DPI系统(Deep Packet Inspection,DPI)中,以实现对网络报文的解析与识别。

应用于应用识别的DPI系统
2、正则表达式与自动机
2.1 初识正则表达式与自动机
在形式化语言与自动机理论中,正则表达式与有穷自动机有着理论上的严格等价性。

正则表达式与自动机的等价性
自动机分为确定型有穷自动机(Deterministic Finite Automata,DFA)和非确定型有穷自动机(Non-Deterministic Finite Automata,NFA)。确定型有穷自动机中,对于给定的确定状态与确定输入,其状态转移关系是确定唯一的,且每一时刻只存在一个激活状态。相反,在非确定型有穷自动机中,对于给定的确定状态与确定输入,其可能存在多个状态转移关系,且某一时刻可能存在多个的激活状态。非确定型有穷自动机又主要分为存在epsilon转移的epsilon-NFA与没有epsilon转移的NFA,其经典代表分别为Thompson NFA与Gluskov NFA。

Thompson NFA
上图所示为识别正则表达式(AB|CD)*AFF*的Thompson NFA,可见thompson NFA由基本的子正则表达式NFA单元通过epsilon边连接而成,epsilon边连接的两个状态可以由空字符进行转移,即存在无条件的状态转移关系,由字母标识的边连接的两个状态表明这两个状态之间需要输入对应的字符才能进行激活状态的转移。

Gluskov NFA
上图所示为识别正则表达式(AB|CD)*AFF*的Gluskov NFA。显而易见,Gluskov NFA比Thompson NFA要简洁很多,且Glukov NFA中NFA的状态数与正则表达式中出现的字符和字符集总数一致。相比于Thompson NFA,Gluskov NFA状态数更少,结构更紧凑。同时在Gluskov NFA中,状态之间的跳转条件被移到了节点内变成了节点的激活条件,因此Gluskov NFA的运行时处理也会变得更加简单。在运行时读入一个字符c时,便可知道字符c可以激活的状态集reach(c),那么只需在Gluskov NFA当前的激活状态集s的基础上计算其后继状态集succ(s),并取reach(c)与succ(s)的交集,所得的交集即为Gluskov NFA的下一刻激活状态集。对于Thompson NFA,节点的激活条件并不唯一,且需要处理epsilon边连接的状态转移关系,其下一刻的激活状态集的计算会更复杂。
对Thompson NFA或Gluskov NFA使用子集构造算法,可以将NFA转化为DFA。DFA相较于NFA最大的优势是性能,而劣势在于空间开销,这是因为DFA状态转移的确定性是通过对NFA不同状态进行组合得到的,因此功能等价的DFA和NFA从理论上来说,DFA状态数的上限是NFA状态数的指数关系。

DFA状态图
上图所示为使用子集构造算法将识别正则表达式(AB|CD)*AFF*的thompson NFA转化为DFA后的状态图。图中每个蓝色框的序号集中的序号对应于thompson NFA中状态的序号,体现了DFA中的每个状态对应于NFA状态集的一个子集。
2.2 主流的开源自动机相关库
目前广泛使用的主流开源自动机相关库主要是Pcre、RE2、Hyperscan:
- Pcre支持的正则表达式语法是最全最复杂的,但PCRE只支持块模式编译和匹配,并且只支持单条正则表达式的编译和匹配,性能在这三款软件中是最差的。对于需要进行大规模正则规则并行匹配的场景,pcre就显得力不从心了。
- Google的开源正则匹配引擎RE2是基于虚拟机方法c++实现的一款快速、安全、线程友好的正则匹配自动机,支持的正则表达式语法比pcre少但比hyperscan多。RE2支持少量正则规则集的并行匹配,不支持只能用回溯算法实现的正则表达式语法。
- Hyperscan是Intel开源的一款基于正则表达式NFA/DFA图分析与拆解的高性能正则表达式混合自动机。在这三款软件中,hyperscan支持的正则语法最少,但其性能是最强的,且支持大规模正则规则集的并行匹配。
3、自动机的性能优化实践
正则表达式的匹配速率是制约IDS/IPS、WAF、DPI等业务的重要性能瓶颈。提升正则表达式自动机的匹配性能是提升以上业务能力的关键所在,下面介绍自动机性能优化的几种主流方法。
3.1 基于预过滤的性能优化

基于预过滤的正则表达式优化策略
上图所示为基于字符串匹配器预过滤的正则表达式匹配优化策略。该方案会在正则表达式的编译过程中提取正则表达式中的字符串信息,并根据提取的字符串构建一个多字符串预匹配器。如针对规则0,提取了字符串SEARCH,针对规则N提取了字符串SUBSCRIBE。在对输入预料进行匹配的过程中,会先使用多字符串匹配器进行字符串的匹配,若匹配过程中匹配到了字符串SERACH但是没有匹配到字符串SUBCRIBE,则会进一步使用根据正则表达式规则0构建的自动机进行第二阶段的正则表达式匹配。可见基于预过滤的正则表达式匹配方案为一个两阶段的匹配过程。
基于字符串匹配器的预过滤正则表达式匹配方案虽然能提早过滤掉无法匹配的语料。但仍然存在以下的诸多不足:
(1)对正则表达式中的字符串存在重复匹配,即预过滤的字符串匹配组件匹配一次字符串,自动机又重复匹配一次字符串;
(2)基于预过滤的匹配方案中的第二阶段,使用自动机对字符串进行匹配难以有效地使用CPU的SIMD指令集进行字符串匹配的并行加速;
(3)不合理的关键字符串选择容易拖累整体正则表达式的匹配性能。
针对基于字符串匹配器预过滤的正则表达式匹配方案的不足,一种更新颖有效的基于正则表达式分解的正则表达式匹配方案便应运而生了。
3.2 基于正则表达式分解的性能优化
基于正则表达式分解的正则表达式匹配方案首先会将正则表达式拆解成几个子字符串和子正则表达式。拆解的子字符串会被构建为一个字符串匹配器(字符串匹配器可以有效地使用CPU的SIMD指令集进行并行加速,相比于使用自动机匹进行字符串配具有数量级上的性能优势),而拆解的子正则表达式则会被构建为一个子自动机,如NFA或DFA。在对输入语料进行正则表达式匹配时,该方案会按照一定顺序调用各个匹配器,并尽量优先调用字符串匹配器进行字符串的匹配,只有当前一个匹配器匹配成功后才会调用下一个匹配器进行匹配,并且只有当所有的匹配器都按照既定的顺序匹配成功后,整条拆解的正则表达式才真正匹配成功。

基于规则拆分的正则表达式匹配策略
上图所示为使用拆解后的正则表达式.*start[^x]comA+匹配输入字符串AstarZcomA的一个示例。首先,正则表达式被拆解为五个部分,分别对应于自动机部分FA2、FA1、FA0与字符串部分STR2、STR1。拆解后构造的各个子自动机与子字符串匹配器的匹配顺序为STR1->STR2->FA1->FA0->FA2。拆解后构造的各个子自动机与子字符串遵循一下的优先级原则:
- 字符串匹配优先于自动机匹配。
- 两个字符串中间的自动机匹配优先于其它位置的自动机匹配。
- 匹配语料尾部的自动机优先于匹配语料头部的自动机。
第一条优先级原则很好理解,在于字符串匹配速率相对于自动机匹配速率有着数量级上的性能优势。两个字符串之间的自动机所需匹配的语料的行首和行尾是锚定的,因此它的优先级相对于其它自动机优先级较高,即优先级原则2。由于匹配语料尾部的自动机其匹配的行首是锚定的无需回溯操作,所以其优先级较高,即优先级原则3。可见,拆解后的各子自动机与子字符串匹配器的匹配顺序原则上遵循:性能开销越小的匹配过程,其匹配顺序越靠前。
对于输入语料,AstarZcomA,首先会使用字符串匹配器匹配字符串STR1,此时字符串匹配成功,继续调用字符串匹配器匹配字符串STR2,此时字符串STR2匹配失败,则不再使用后续的FA1、FA0、FA2进行匹配。若输入的字符串为AstartZcomA,则会依次成功匹配STR1、STR2、FA1、FA0、FA2,最后输出匹配成功信息。
4、正则规则匹配的应用思考
在互联网领域的各种开发与应用中,网络进攻检测、应用流量识别等大量的场景需要使用正则引擎进行正则表达式的匹配。正则表达式的匹配效率不仅取决于使用的正则引擎的性能好坏,也与书写的正则表达式形式息息相关。揭秘正则引擎的实现原理能让我们更深入了解正则表达式的形式与正则引擎效率的相关性,更好地指导我们进行正则引擎的性能调优。以下原则的正则表达式书写指导意见能帮助我们在开发与应用过程中更高效地进行正则表达式的匹配:
- 尽量避免使用需要用回溯方法实现的正则表达式语法,如反向引用语法。回溯的引入会使最坏情况下正则匹配的时间复杂度呈指数的增长。
- 尽量在正则表达式中避免(.*)、{min,max}这样的语法,(.*)引入的不确定性以及{min,max}带来的有界重复是正则表达式引擎的重要性能瓶颈。
- 尽量将正则表达式写得更确定,如尽量在正则表达式中写更多确定的字符或字符串。