我们在使用SQL语句查询表数据时,提前用explain进行语句分析是一个非常好的习惯。通过explain输出sql的详细执行信息,就可以针对性的进行sql优化。
今天我们来分析一下,在explain中11种不同type代表的含义以及其应用场景。
1、system
应用场景:表中只有一条数据,且存储引擎可以准确的统计到这条数据。
system一般出现在MyISAM、memory类型的表查询中。
由于我们一般使用的存储引擎都是InnoDB,所以system这种类型很少会用到。
2、const
应用场景:通过主键或者唯一索引等值查询来定位一条数据。
比如:select * from test where id = 1。
我们知道,MySQL底层使用B+树来保存数据,其结构大体可类似下图,
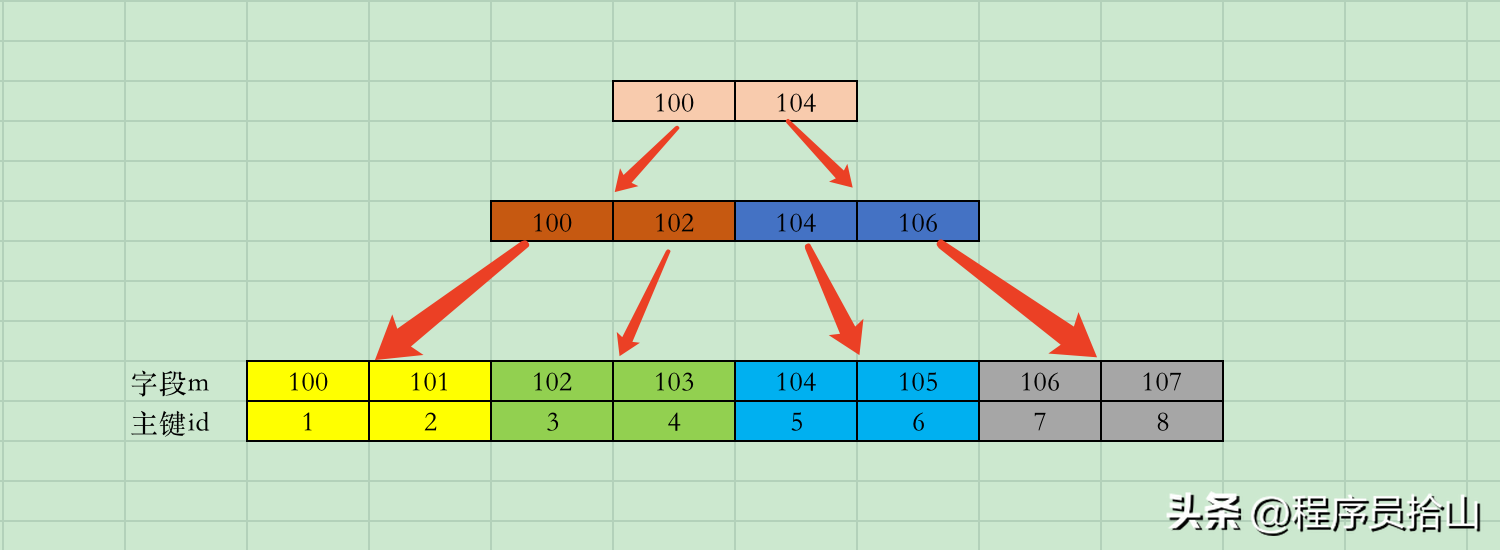
那么我们在m字段上创建唯一索引约束,如果想找到m=103的记录,通过二分法只需简单两步就可以定位到m=103。
即100->102->103。
即使对于一张记录很多的真正的业务表,因为B+树矮胖的结构,定位一条唯一索引中的记录,速度也是非常快的。
可以粗略的认为,这种查询速度是常数级的。
所以,MySQL就把这种唯一索引或主键(主键也是一种唯一索引)等值匹配的查询定义为const(常数级)。
需要注意的是,由于唯一索引中允许存在多个null值,所以如果对唯一索引进行null值查询,是没法用const的。
3、eq_ref
应用场景:在进行多表连接查询时,被驱动表通过主键或唯一索引键进行等值查询。
比如:SELECT * FROM t1 LEFT JOIN t2 ON t1.id = t2.id。

4、ref
应用场景:普通二级索引等值查询。
比如:select * from t2 where key2 =4。

除了唯一索引,我们更多的会使用普通的二级索引。
由于通过二级索引,可能会查询到多个匹配值,相比const性能差那么一点。
MySQL就把这种类型的查询定义为了ref。
在上面我们说到,由于唯一索引可能存在多个null,所以用不了const。
那对于 select * from t2 where key2 is null 来说,不管是唯一索引还是普通索引,其最多用到ref这种类型。
5、ref_or_null
应用场景:命中索引时,查询条件除了等值查询,还包含null值查询。
比如:select * from t2 where key2 =4 or key2 is null。

其实看名字就很容易理解,MySQL会在B+树上,找到key2=1和key2 is null 这两种记录范围值,然后拿到主键id去回表查询相关信息。
6、index_merge
应用场景:查询条件可以命中多个索引的情况。
比如:select * from t3 where key1 =3 or key2 =4、

索引合并其实也很好理解,当查询条件可以命中多个索引时,MySQL会尝试在两个索引树查找匹配的条件,然后将结果其合并起来。
7、unique_subquery
应用场景:查询条件包含子查询,并且子查询的列可以进行主键等值匹配。
比如:SELECT * FROM t2 WHERE t2.key2 IN ( SELECT id FROM t3 WHERE t2.key2 = t3.key2 ) OR t2.key2 = 1。

通过查看MySQL优化的执行sql,可以看到MySQL将in子查询优化为了exist语句,并且在主键索引上进行了等值查询。
MySQL优化后的语句:/* select#1 */ select `dbs`.`t2`.`id` AS `id`,`dbs`.`t2`.`key2` AS `key2` from `dbs`.`t2` where (<in_optimizer>(`dbs`.`t2`.`key2`,<exists>(<primary_index_lookup>(<cache>(`dbs`.`t2`.`key2`) in t3 on PRIMARY where ((`dbs`.`t2`.`key2` = `dbs`.`t3`.`key2`) and (<cache>(`dbs`.`t2`.`key2`) = `dbs`.`t3`.`id`))))) or (`dbs`.`t2`.`key2` = 1))。
8、index_subquery
应用场景:查询条件包含子查询,并且子查询的列可以通过索引进行等值匹配。
比如:SELECT * FROM t2 WHERE t2.key2 IN ( SELECT key1 FROM t3 WHERE t2.key2 = t3.key2 ) OR t2.key2 = 1。

index_subquery和unique_subquery的区别在于子查询中的列是唯一索引还是普通的二级索引。
9、range
应用场景:命中索引时,查询某一个范围内的结果。
比如:select * from t3 where t3.key1 >1 and t3.key1<3。

在实际的业务场景中,对某个列进行范围查询还是很常见的需求。
10、index
应用场景:直接在某个索引树上做条件判断,并且不需要回表。
比如:select t3.key1 from t3 where t3.key2 =6。

当我们创建了联合索引idx_key1_key2(key1,key2)时,判断条件key2=6时,其虽然不满足索引的最左前缀原则,但是我们可以遍历idx_key1_key2这颗索引树,找到key2=6的记录即可。
由于查询结果需要的key1在这个联合索引上,也不需要回表,此时就可以使用index。
相对来说,index的性能是比较慢的。
11、all
应用场景:直接遍历整个聚簇索引。
比如: select * from t1。
当MySQL无法通过where条件匹配到合适的索引或者因为全部扫描的代价更小时,MySQL就会选择all这种类型来全表扫描。
这种方式也是最不推荐的。
最后
总得来说,我们在进行查询时,查询类型可分为两大类:全部扫描和索引查询。
索引查询又可以细分:
- 唯一索引等值查询。
- 普通索引等值查询。
- 普通索引范围查询。
- 扫描整个索引树。
对于一条查询sql来说,不同的查询类型虽然结果可能是一样的,但是其性能却可能天差地别。
不同类型性能从强到差:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > all。
建议大家在平时书写sql时,多用explain进行分析,尝试去优化代码,只有不断的实践,才能让自己的sql能力越来越强。