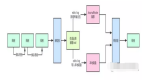
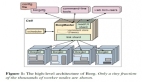
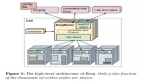
$kube-state-metrics-hkube-state-metricsisasimpleservicethatlistenstotheKubernetesAPIserverandgeneratesmetricsaboutthestateoftheobjects.
Usage:
kube-state-metrics [flags]
kube-state-metrics [command]
AvailableCommands:
completionGeneratecompletionscriptforkube-state-metrics.
helpHelpaboutanycommandversionPrintversioninformation.
Flags:
--add_dir_headerIftrue, addsthefiledirectorytotheheaderofthelogmessages--alsologtostderrlogtostandarderroraswellasfiles (noeffectwhen-logtostderr=true)
--apiserverstringTheURLoftheapiservertouseasamaster--configstringPathtothekube-state-metricsoptionsconfigfile--custom-resource-state-configstringInlineCustomResourceStateMetricsconfigYAML (experimental)
--custom-resource-state-config-filestringPathtoaCustomResourceStateMetricsconfigfile (experimental)
--custom-resource-state-onlyOnlyprovideCustomResourceStatemetrics (experimental)
--enable-gzip-encodingGzipresponseswhenrequestedbyclientsvia'Accept-Encoding: gzip'header.
-h, --helpPrintHelptext--hoststringHosttoexposemetricson. (default"::")
--kubeconfigstringAbsolutepathtothekubeconfigfile--log_backtrace_attraceLocationwhenlogginghitslinefile:N, emitastacktrace (default :0)
--log_dirstringIfnon-empty, writelogfilesinthisdirectory (noeffectwhen-logtostderr=true)
--log_filestringIfnon-empty, usethislogfile (noeffectwhen-logtostderr=true)
--log_file_max_sizeuintDefinesthemaximumsizealogfilecangrowto (noeffectwhen-logtostderr=true). Unitismegabytes. Ifthevalueis0, themaximumfilesizeisunlimited. (default1800)
--logtostderrlogtostandarderrorinsteadoffiles (defaulttrue)
--metric-allowliststringComma-separatedlistofmetricstobeexposed. Thislistcomprisesofexactmetricnamesand/orregexpatterns. Theallowlistanddenylistaremutuallyexclusive.
--metric-annotations-allowliststringComma-separatedlistofKubernetesannotationskeysthatwillbeusedintheresource' labels metric. By default the metric contains only name and namespace labels. To include additional annotations provide a list of resource names in their plural form and Kubernetes annotation keys you would like to allow for them (Example: '=namespaces=[kubernetes.io/team,...],pods=[kubernetes.io/team],...)'. A single '*' can be provided per resource instead to allow any annotations, but that has severe performance implications (Example: '=pods=[*]').--metric-denyliststringComma-separatedlistofmetricsnottobeenabled. Thislistcomprisesofexactmetricnamesand/orregexpatterns. Theallowlistanddenylistaremutuallyexclusive.
--metric-labels-allowliststringComma-separatedlistofadditionalKuberneteslabelkeysthatwillbeusedintheresource' labels metric. By default the metric contains only name and namespace labels. To include additional labels provide a list of resource names in their plural form and Kubernetes label keys you would like to allow for them (Example: '=namespaces=[k8s-label-1,k8s-label-n,...],pods=[app],...)'. A single '*' can be provided per resource instead to allow any labels, but that has severe performance implications (Example: '=pods=[*]'). Additionally, an asterisk (*) can be provided as a key, which will resolve to all resources, i.e., assuming '--resources=deployments,pods', '=*=[*]' will resolve to '=deployments=[*],pods=[*]'.--metric-opt-in-liststringComma-separatedlistofmetricswhichareopt-inandnotenabledbydefault. Thisisinadditiontothemetricallow-anddenylists--namespacesstringComma-separatedlistofnamespacestobeenabled. Defaultsto""--namespaces-denyliststringComma-separatedlistofnamespacesnottobeenabled. Ifnamespacesandnamespaces-denylistarebothset, onlynamespacesthatareexcludedinnamespaces-denylistwillbeused.
--nodestringNameofthenodethatcontainsthekube-state-metricspod. MostlikelyitshouldbepassedviathedownwardAPI. Thisisusedfordaemonsetsharding. Onlyavailableforresources (podmetrics) thatsupportspec.nodeNamefieldSelector. Thisisexperimental.
--one_outputIftrue, onlywritelogstotheirnativeseveritylevel (vsalsowritingtoeachlowerseveritylevel; noeffectwhen-logtostderr=true)
--podstringNameofthepodthatcontainsthekube-state-metricscontainer. Whenset, itisexpectedthat--podand--pod-namespacearebothset. MostlikelythisshouldbepassedviathedownwardAPI. Thisisusedforauto-detectingsharding. Ifset, thishaspreferenceoverstaticallyconfiguredsharding. Thisisexperimental, itmayberemovedwithoutnotice.
--pod-namespacestringNameofthenamespaceofthepodspecifiedby--pod. Whenset, itisexpectedthat--podand--pod-namespacearebothset. MostlikelythisshouldbepassedviathedownwardAPI. Thisisusedforauto-detectingsharding. Ifset, thishaspreferenceoverstaticallyconfiguredsharding. Thisisexperimental, itmayberemovedwithoutnotice.
--portintPorttoexposemetricson. (default8080)
--resourcesstringComma-separatedlistofResourcestobeenabled. Defaultsto"certificatesigningrequests,configmaps,cronjobs,daemonsets,deployments,endpoints,horizontalpodautoscalers,ingresses,jobs,leases,limitranges,mutatingwebhookconfigurations,namespaces,networkpolicies,nodes,persistentvolumeclaims,persistentvolumes,poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas,secrets,services,statefulsets,storageclasses,validatingwebhookconfigurations,volumeattachments"--shardint32Theinstancesshardnominal (zeroindexed) withinthetotalnumberofshards. (default0)
--skip_headersIftrue, avoidheaderprefixesinthelogmessages--skip_log_headersIftrue, avoidheaderswhenopeninglogfiles (noeffectwhen-logtostderr=true)
--stderrthresholdseveritylogsatorabovethisthresholdgotostderrwhenwritingtofilesandstderr (noeffectwhen-logtostderr=trueor-alsologtostderr=false) (default2)
--telemetry-hoststringHosttoexposekube-state-metricsselfmetricson. (default"::")
--telemetry-portintPorttoexposekube-state-metricsselfmetricson. (default8081)
--tls-configstringPathtotheTLSconfigurationfile--total-shardsintThetotalnumberofshards. Shardingisdisabledwhentotalshardsissetto1. (default1)
--use-apiserver-cacheSetsresourceVersinotallow=0forListWatchrequests, usingcachedresourcesfromtheapiserverinsteadofanetcdquorumread.
-v, --vLevelnumberfortheloglevelverbosity--vmodulemoduleSpeccomma-separatedlistofpattern=Nsettingsforfile-filteredloggingUse"kube-state-metrics [command] --help"formoreinformationaboutacommand.
$kubectllogs-fkube-state-metrics-1-nkube-systemI021605:53:23.1511631wrapper.go:78] Startingkube-state-metricsI021605:53:23.1544951server.go:125] "Used default resources"I021605:53:23.1549231types.go:184] "Using all namespaces"I021605:53:23.1555561server.go:166] "Metric allow-denylisting"allowDenyStatus="Excluding the following lists that were on denylist: "W021605:53:23.1557921client_config.go:617] Neither--kubeconfignor--masterwasspecified. UsingtheinClusterConfig. Thismightnotwork.
I021605:53:23.1785531server.go:311] "Tested communication with server"I021605:53:23.2410241server.go:316] "Run with Kubernetes cluster version"major="1"minor="25"gitVersinotallow="v1.25.3"gitTreeState="clean"gitCommit="434bfd82814af038ad94d62ebe59b133fcb50506"platform="linux/arm64"I021605:53:23.2411691server.go:317] "Communication with server successful"I021605:53:23.2451321server.go:263] "Started metrics server"metricsServerAddress="[::]:8080"I021605:53:23.2461481metrics_handler.go:103] "Autosharding enabled with pod"pod="kube-system/kube-state-metrics-1"I021605:53:23.2462331metrics_handler.go:104] "Auto detecting sharding settings"I021605:53:23.2462671server.go:252] "Started kube-state-metrics self metrics server"telemetryAddress="[::]:8081"I021605:53:23.2534771server.go:69] levelinfomsgListeningonaddress[::]:8081I021605:53:23.2534771server.go:69] levelinfomsgListeningonaddress[::]:8080I021605:53:23.2539441server.go:69] levelinfomsgTLSisdisabled.http2falseaddress[::]:8080I021605:53:23.2545341server.go:69] levelinfomsgTLSisdisabled.http2falseaddress[::]:8081I021605:53:23.2975241metrics_handler.go:80] "Configuring sharding of this instance to be shard index (zero-indexed) out of total shards"shard=1totalShards=2I021605:53:23.4117101builder.go:257] "Active resources"activeStoreNames="certificatesigningrequests,configmaps,cronjobs,daemonsets,deployments,endpoints,horizontalpodautoscalers,ingresses,jobs,leases,limitranges,mutatingwebhookconfigurations,namespaces,networkpolicies,nodes,persistentvolumeclaims,persistentvolumes,poddisruptionbudgets,pods,replicasets,replicationcontrollers,resourcequotas,secrets,services,statefulsets,storageclasses,validatingwebhookconfigurations,volumeattachments"
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
可以看到有类型 "Configuring sharding of this instance to be shard index (zero-indexed) out of total shards" shard=1 totalShards=2 这样的日志信息,表面自动分片成功了。我们可以去分别获取下分片的指标数据大小,并和未分片之前的进行对比,可以看到分片后的指标明显减少了,如果单个实例的指标数据还是太大,则可以增加 StatefulSet 的副本数即可。