BEV 感知到底是什么?自动驾驶的学术界和工业界又都在关注 BEV 感知的什么内容?本文将会为你揭晓答案。
在自动驾驶领域中,让感知模型学习强大的鸟瞰图(BEV)表征是一种趋势,并且已经引起了工业界和学术界的广泛关注。相比于之前自动驾驶领域中的大多数基于在前视图或透视图中执行检测、分割、跟踪等任务的模型,鸟瞰图(BEV)表征能够让模型更好地识别被遮挡的车辆,并且有利于后续模块(例如规划、控制)的开发和部署。
可以看出,BEV 感知研究对自动驾驶领域具有巨大的潜在影响,值得学术界和产业界长期关注并投入大量精力,那么 BEV 感知到底是什么?自动驾驶的学术界和工业界大佬又都在关注 BEV 感知的什么内容?本文将会通过 BEVPerception Survey 为你揭晓答案。
BEVPerception Survey 是上海人工智能实验室自动驾驶OpenDriveLab 团队与商汤研究院合作论文 《Delving into the Devils of Bird's-eye-view Perception: A Review, Evaluation and Recipe》 的实用化工具呈现方式,分为基于 BEVPercption 的最新文献研究和基于 PyTorch 的开源 BEV 感知工具箱两大板块。

- 论文地址:https://arxiv.org/abs/2209.05324
- 项目地址:https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe
概要解读、技术解读
BEVPerception Survey 最新文献综述研究主要包含三个部分 ——BEV 相机、BEV 激光雷达和 BEV 融合。BEV 相机表示仅有视觉或以视觉为中心的算法,用于从多个周围摄像机进行三维目标检测或分割;BEV 激光雷达描述了点云输入的检测或分割任务;BEV 融合描述了来自多个传感器输入的融合机制,例如摄像头、激光雷达、全球导航系统、里程计、高清地图、CAN 总线等。
BEV 感知工具箱是为基于 BEV 相机的 3D 对象检测提供平台,并在 Waymo 数据集上提供实验平台,可以进行手动教程和小规模数据集的实验。

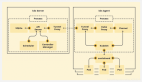
图 1:BEVPerception Survey 框架
具体来说,BEV 相机表示用于从多个周围相机进行 3D 对象检测或分割的算法;BEV 激光雷达表示用点云作为输入来完成检测或分割任务;BEV 融合则是用多个传感器的输出作为输入,例如摄像头、LiDAR、GNSS、里程计、HD-Map、CAN-bus 等。
BEVPercption 文献综述研究
BEV 相机
BEV 相机感知包括 2D 特征提取器、视图变换和 3D 解码器三部分。下图展示了 BEV 相机感知流程图,在视图变换中,有两种方式对 3D 信息进行编码 —— 一种是从 2D 特征预测深度信息;另一种是从 3D 空间中采样 2D 特征。

图 2:BEV 相机感知流程图
对于 2D 特征提取器,2D 感知任务中存在大量可以在 3D 感知任务中借鉴的经验,比如主干预训练的形式。
视图转换模块是与 2D 感知系统非常不同的一方面。如上图所示,一般有两种方式进行视图变换:一种是从 3D 空间到 2D 空间的变换,另一种是从 2D 空间到 3D 空间的变换,这两种转换方法要么是利用在 3D 空间中的物理先验知识或利用额外的 3D 信息监督。值得注意的是并非所有 3D 感知方法都有视图变换模块,比如有些方法直接从 2D 空间中的特征检测 3D 空间中的对象。
3D 解码器接收 2D/3D 空间中的特征并输出 3D 感知结果。大多数 3D 解码器的设计来自基于 LiDAR 的感知模型。这些方法在 BEV 空间中执行检测,但仍然有一些 3D 解码器利用 2D 空间中的特征并直接回归 3D 对象的定位。
BEV 激光雷达
BEV 激光雷达感知的普通流程主要是将两个分支将点云数据转换为 BEV 表示。下图为 BEV 激光雷达感知流程图,上分支提取 3D 空间中的点云特征,提供更准确的检测结果。下分支提取 2D 空间中的 BEV 特征,提供更高效的网络。除了基于点的方法能在原始点云上进行处理外,基于体素的方法还将点体素化为离散网格,通过离散化连续的 3D 坐标提供更高效的表示。基于离散体素表示,3D 卷积或 3D 稀疏卷积可用于提取点云特征。

图 3:BEV 激光雷达感知流程图
BEV 融合
BEV 感知融合算法有 PV 感知和 BEV 感知两种方式,适用于学术界和工业界。下图展示了 PV 感知与 BEV 感知流程图的对比,两者的主要区别在于 2D 到 3D 的转换和融合模块。在 PV 感知流程图中,不同算法的结果首先被转换到 3D 空间中,然后使用一些先验知识或者手工设计的规则进行融合。而在 BEV 感知流程图中,PV 特征图会被转换到 BEV 视角下,然后进行 BEV 空间下的融合从而得到最终的结果,因而能够最大化保留原始特征信息,避免过多的手工设计。

图 4:PV 感知(左)与 BEV 感知(右)流程图
适用于 BEV 感知模型的数据集
针对 BEV 感知任务存在很多的数据集。通常数据集由各种场景组成,并且每个场景在不同数据集中的长度不同。下表总结了目前学界常用的数据集。我们可以从中看到 Waymo 数据集相比其他数据集有着更多样的场景以及更丰富的 3D 检测框的标注。

表 1:BEV 感知数据集一览
然而目前学界并没有针对 Waymo 开发的 BEV 感知任务的软件公开。因此我们选择基于 Waymo 数据集进行开发,希望可以推动 BEV 感知任务在 Waymo 数据集上的发展。
Toolbox - BEV 感知工具箱
BEVFormer 是一种常用的 BEV 感知方法,它采用时空变换器将主干网络从多视图输入提取的特征转换为 BEV 特征,然后将 BEV 特征输入检测头中得到最后的检测结果。BEVFormer 有两个特点,它具有从 2D 图像特征到 3D 特征的精确转换,并可以把它提取的 BEV 特征适用于不同的检测头。我们通过一系列的方式进一步提升了 BEVFormer 的视图转换质量以及最终的检测性能。
在凭借 BEVFormer++ 取得 CVPR 2022 Waymo Challenge 第一名后,我们推出了 Toolbox - BEV 感知工具箱,通过提供一整套易于上手的 Waymo Open Dataset 的数据处理工具,从而集成一系列能够显著提高模型性能的方法(包括但不限于数据增强,检测头,损失函数,模型集成等),并且能够与领域内广泛使用的开源框架,如 mmdetection3d 以及 detectron2 兼容。与基础的 Waymo 数据集相比,BEV 感知工具箱将使用技巧加以优化改进以便不同类型研发人员使用。下图展示的是基于 Waymo 数据集的 BEV 感知工具箱使用示例。

图 5:基于 Waymo 数据集的 Toolbox 使用示例
总结
- BEVPerception Survey 总结了近年来 BEV 感知技术研究的总体情况,包括高层次的理念阐述和更为深入的详细讨论。对 BEV 感知相关文献的综合分析,涵盖了深度估计、视图变换、传感器融合、域自适应等核心问题,并对 BEV 感知在工业系统中的应用进行了较为深入的阐述。
- 除理论贡献外,BEVPerception Survey 还提供了一套对于提高基于相机的 3D 鸟瞰图(BEV)物体检测性能十分实用的工具箱,包括一系列的训练数据增强策略、高效的编码器设计、损失函数设计、测试数据增强和模型集成策略等,以及这些技巧在 Waymo 数据集上的实现。希望可以帮助更多的研究人员实现 “随用随取”,为自动驾驶行业研发人员提供更多的便利。
我们希望 BEVPerception Survey 不仅能帮助使用者方便地使用高性能的 BEV 感知模型,同时也能成为新手入门 BEV 感知模型的良好起点。我们着力于突破自动驾驶领域的研发界限,期待与学界分享观点并交流讨论进而不断发掘自动驾驶相关研究在现实世界中的应用潜力。