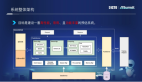
一、问题挑战
基线治理前,我们的基线运维存在较多的问题,有两个数字很能说明问题:
(1)月平均起夜天数达80%以上。为什么会这么多呢,有很多因素,例如运维范围不清晰、基线挂载没有约束、集群资源紧张等等。
(2)基线产出时间较迟,经常无法在上班前产出,月平均破线时长将近十小时。
要进行全链路基线治理,面临的挑战也很大,主要来自3方面:
- 任务多:千亿级日志量,万级任务数,如何收敛在可控的范围,如何在出错后,能较快的重跑完?
- 资源紧:凌晨资源水位95%以上,没有任何的 buffer 预留,也没有弹性资源可用;
- 要求高:显微镜下工作,以 MUSE 产品为例,上百 BD,每天上班就看数据,他们的 KPI 考核就以 MUSE 的数据为准。
二、目标衡量
全链路基线治理的价值,总结起来主要有4个方面:
- 服务于管理层,让管理层第一时间能查看公司的经营数据。
- 面向 C 端的业务数据,能够稳定、及时的让用户更友好的使用。
- 能够建立数据开发团队的研发口碑和影响力。
- 提升我们数据开发同学的运维幸福度,进而提升组织的稳定性。
那么我们用什么指标来衡量我们的目标呢?我们提出了两个数字来牵引:
- 98%:全年可用天数达到98%以上,即服务不达标天数全年不超过7天。
- 基线时间:核心 SLA 基线产出时间需满足业务要求。
三、行动方案
3.1 整体方案
基于上述问题挑战的剖析,我们对该问题的解题思路拆成3个方面:
- 平台基建:俗话说:“根基不牢,地动山摇”,首先要解决的就是平台基建,例如如何衡量我们的集群资源是否饱和、我们的队列如何管控、产品功能如何支持等等。
- 任务运维:全链路上,哪些任务是卡点?超长高耗资源任务是什么原因?哪些任务需要高保障?
- 组织流程:有没有标准的运维 SOP ?跨团队的协作机制如何建立?出问题后,如何有效的跟踪以及避免再次发生?
用3个词归纳,就是稳基建、优任务、定标准。

3.2 稳基建
基建这块,我们梳理了存在的问题:(1)队列使用不明确:总共拆分了几十个队列,没有明确的使用规范;(2)资源监控靠经验,无通用指标衡量;(3)集群 Namenode 压力大,负载高;(4)资源管控弱,遇到突发情况无法保障高优任务优先获取资源。
针对上述问题,我们实施了如下的解决方案:
- 集群稳定性建设:联合杭研,对负载高的 Namenode 集群进行 DB 拆分,迁移上百张表;同时完善集群的监控,例如 nvme 盘夯住自动监控修复,dn/nn/hive 等节点监控优化快速发现问题。
- 集群资源数字化:实现了一个高可靠的资源使用模型,为集群资源管理员提供具体的数字化指标,以此可以快速判断当前集群的资源使用情况,解决当前集群资源分配不合理的情况。
- 产品化:通过产品层面提升资源的使用效率,比如产品功能支持按任务优先级获取队列资源,产品层面实现自助分析&补数功能凌晨禁用或有限度使用。
- 队列资源使用指导建议:制定队列的资源使用规范,明确各个队列的作用,管控队列使用,规划高中低级队列。
3.3 优任务
针对云音乐体量大、业务多、团队广的数据任务特点,我们在这块做的工作主要有:
- 核心 ETL 引入流式处理,按小时预聚合数据,这样1小时内完成流量日任务批跑。
- 任务优化:如 hive、spark2 版本升级至 spark3 ,队列调整、sql 改造等等。
- 打通表、任务、基线间的血缘关系,优化任务的调度时间,减少任务依赖错漏配。
- 指标的异常监控,我们除了传统的 dqc 外,还引入机器学习模型,解决云音乐 DAU 这类指标具有周期性、假日因素的监控难点。
其中,spark 升级得到了杭研同学的贴身服务,取得了比较好的成果,hive 升级到 spark3 完成大几百个任务的改造,节省60%资源。spark2 升级 spark3,完成将近千个任务的改造,整体性能提升52%,文件数量减少69%。
指标的异常监控,引入的机器学习模型,我们主要融合了 Holtwinter、XGBoost 算法,相比 dqc 的监控,我们在 DAU 这个指标上,召回率提升74%,准确率提升40%,正确率提升20%;同时这里还有一个很大的作用是,它能感知业务的动态趋势性变化,而且部署也很简单,配置化接入。在产品层面,我们也正在联合杭研产研同学,将该能力集成到数据质量中心。

3.4 定标准
在定标准方面,主要从两方面出发:运维的范围和运维规范。基于这两点,我们展开了如下的工作:
- 以核心产品+核心报表为载体,划定核心 SLA 运维基线+数仓中间基线,值班运维的范围从原先的上万个任务缩减到千级任务数。
- 明确任务责任人,解决之前事不关己高高挂起的问题,按照业务线划分,工具+人肉并行的方式将无归属的任务归属到责任人。
- 制定基线挂载原则,明确约束条件、各角色职责等。
- 制定标准的运维 SOP ,严格运维军规和奖惩机制;同时跟杭研建立数据运维交警队,多举措保证异常情况的及时处理。
- 建立官方运维消防群,第一时间通知问题和处理进展,解决信息传递不够高效,业务体感差的问题。
- 与杭研、安全中台、前端等达成统一意见,引入 QA 作为公正的第三方,统一牵头处理问题的复盘和归因,确保问题的收敛。
四、成果展示
项目成果这块,主要分为业务成果、技术成果、产品成果三方面。
业务成果,目前我们的核心基线凌晨就能跑完,平均告警天数下降60%,核心基线破线次数0,完成全年可用天数98%以上的目标。
技术成果,我们的《机器学习模型在云音乐指标异动预测的应用实践》荣获了网易集团2022年度技术大会-开源引入奖。同时,我们的集群资源数字化,通过计算出合理的弹性资源,确保集群服务或者任务出现相关波动或异常的情况下,不会造成大量任务延迟、核心基线破线等现象;其次根据资源的安全水位,为扩缩容提供量化的数据指标;最后集群、队列、任务资源透明化后,可以提高整体的资源利用率,降低成本。


产品层面,在杭研的鼎力支持下,实现了队列资源的倾斜、自助取数自动查杀等功能,有效的提升了我们的资源利用率。
五、后续规划
我们将从产品、系统、业务、机制四个方面继续全链路基线治理的工作。
产品层面,我们将引入 DataOps,增强任务的代码自动稽核能力,从开发、上线、审批全流程做管控。优化基线预警,通过检测基线上任务调度时间、依赖设置等,判断是否有优化空间或者异常,并做提示或告警。
系统层面,优化资源监控,支持基于 Label 级别展示分配的物理 CPU、虚拟 CPU、内存等系统资源总量以及指定时段的实际 CPU、虚拟 CPU、内存使用量。同时在任务级的资源使用上,对配置的资源做合理性评估,进而提供优化建议。
业务层面,提升内容级监控覆盖率、准确度;打通线上服务的血缘,覆盖线上服务的任务。
机制完善,联合分析师、数据产品等团队,确定报表、数据产品的下线以及对应历史任务下线流程。
写在最后,治理是一件久久为功的事情,上述更多的是从方法论的角度在讲这件事,但是治理其实更考验执行,需要不断修炼内功,把事情做细,把细事做透。