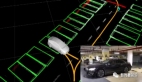
1 何为轨迹预测
自动驾驶中,轨迹预测一般位于感知模块的后端,规控的前端,为承上启下的模块。输入为感知模块提供的目标track的state信息、道路结构信息,综合考量高精地图信息、目标之间的交互信息,环境的语义信息及目标的意图信息,对感知到的各类目标做出意图预测(cut in/out、直行)以及未来一段时间的轨迹预测(0-5s不等)。如下图所示。
ADAS系统需要对周围环境信息有一定认知能力,最基本的水平是要识别环境,再上一层则需要理解环境,而再上一层则需要对环境进行预测。在对目标进行预测后,规控便可根据预测信息进行自车的路径规划,并做出决策对可能出现的危险情况进行制动或发出告警,这便是轨迹预测模块存在的意义所在。

2 两个挑战
轨迹预测可分为短期预测与长期预测。
- 短期预测一般根据运动学模型(CV/CA/CTRV/CTRA)基于当前的目标state信息预测未来一段时间的轨迹,一般<1s是合适的,如果时间过长,那目标仅与运动学相关的假设就不成立了。短期预测可以建一个运动模型专门去预测,同样的也可以使用前面感知模块滤波中的预测模块,只不过不调用测量进行滤波更新,这样的好处是可以传播不确定度。
- 长期预测是当前业界主要在做的。这种预测仅基于运动模型就不合适了,一般需要做意图预测,并结合一些上下文信息(地图、目标间交互信息)才能得到不错的结果。此时业界有很多不同的输出形式,比如输出轨迹的概率分布、输出多条预测轨迹、输出一条可能性最大的预测轨迹。
对于长期的轨迹预测有两个挑战:
- 输出一条可能的轨迹或者输出所有可能的轨迹都是不合理的。你输出一条预测轨迹就可能漏掉真正的轨迹,你输出所有可能的轨迹就会出现误报的情况,这对于ADAS系统均是不可接受的。应该考虑把预测轨迹限制在合适的子集中。
- 对轨迹预测做的越多就需要做更多的假设。极端一点的假设就是假定道路上的所有的目标都遵守交通规则。这如果用于交通模拟功能是合理的,但是对adas系统并不合适,他需要对潜在的危险情况保持敏感。
影响做长期轨迹预测的不确定性主要来源于三个方面:
- 感知模块输出的目标state估计的不确定。
- 驾驶意图预测的不确定性。
- 从意图识别完与车辆机动性改变中间的不确定性。
3 主要考量
对轨迹预测系统应该考虑的四个问题:
- 轨迹预测要对潜在的危险有敏感性,这是轨迹预测存在的意义要求的。
- 既要考虑运行模型也要考虑意图与周围环境的信息。
- 考虑上述的不确定性。
- 考虑输出的轨迹数量问题。
4 业界方法
如下图为bosch公司发表综述论文[2]中的分类方法。
- 如果按照使用模型的不同来分类,轨迹预测方法可以分为使用物理模型的方法、使用学习的方法、使用规划算法的方法。
- 如果按照使用的信息来分类,轨迹预测方法可以分为使用目标的信息的方法、使用环境中的动态目标信息的方法、使用静态环境信息的方法。

轨迹预测具体会涉及到哪些通用算法呢?
- 意图预测:模糊理论、static BNs、DBN(HMM、JumpMM)、DS证据理论、机器学习中的分类算法。
- 深度学习相关,端到端输出。CNN、LSTM、RNN、Attention。
那轨迹预测可以使用哪些具体信息呢?
- 目标信息:当前/历史的速度与位置信息,如果是行人轨迹预测的话,还可使用行人头的朝向、关节信息、性别与年龄信息以及人的注意力信息。
- 环境中的动态目标信息:social force、吸引力、群体约束信息。
- 静态环境信息:free space、map、语义信息(道路结构/交通规则/当前交通信号灯)。
当前学术界轨迹预测方面的论文越来越多,主要原因还是业界没有行之有效的方法。
以下列举业界论文:
BMW:物理模型+意图预测(learning-based)。使用启发式的方法集成专家知识,简化了交互模型,在意图预测的分类模型中加入了博弈论思想[3]。

BENZ:主要为意图预测的相关论文,使用的是DBN[4]。

Uber:LaneRCNN[5]。

Google:VectorNet[6]。

Huawei:HOME[7]。

Waymo:TNT[8]。

Aptive:Covernet[9]。

NEC:R2P2[10]。
商汤:TPNet[11]。

美团:StarNet[12]。行人。

Aibee:Sophie[13]。行人。

MIT:Social lstm[14]。行人。

中科大:STGAT[15]。行人。

百度:Lane-Attention[16]。

Apollo:可以看如下博客作为参考。
https://www.cnblogs.com/liuzubing/p/11388485.html
Apollo的预测模块接收感知、定位以及地图模块的输入。
1.首先做了场景拆分,分为了普通巡航道路以及路口两个场景。
2.而后对感知得到的目标做重要性划分,分为可以忽略的目标(不会影响到自车)、需要谨慎处理的目标(可能影响到自车)以及普通目标(介于二者之间)。
3.而后进入Evaluator,本质上就是一个意图预测。

4.最后进入predictor,用于预测轨迹生成。对于静止目标、沿道行驶、freeMove、路口等不同场景做不同的操作。

5 数据集
(1) NGSIM
此数据集是美国FHWA搜集的高速公路行车数据,包括了US101、I-80等道路上的所有车辆在一个时间段的车辆行驶状况。数据是采用摄像头获取,然后加工成一条一条的轨迹点记录。其数据集为CSV文件。数据没有太多噪声。

更多是整体调度层面的信息,如道路规划、车道设置、车流量调节等。车辆运动学状态需要进一步抽取。处理代码可使用下面的github。
https://github.com/nachiket92/conv-social-pooling
(2) INTERACTION
此数据集为加州大学伯克利分校机械系统控制实验室(MSC Lab)与来自卡尔斯鲁厄理工学院(KIT)和国立巴黎高等矿业学院(MINES ParisTech)的合作者建立了一个国际性、对抗性、协作性的数据集(INTERACTION)。它能准确再现不同国家的各种驾驶场景中道路使用者(如车辆、行人)的大量交互性行为。

http://www.interaction-dataset.com/
(3)apolloscape
此为Apollo的公开自动驾驶数据集,其中有为轨迹预测提供的数据。内部文件为2fps的1min数据序列,数据结构包括帧数ID、目标ID、目标类别、位置xyz,长宽高信息以及heading,其中目标类别包括小车、大车、行人、自行车/电动车以及其他。
https://apolloscape.auto/trajectory.html
(4) TRAF
此数据集聚焦于高密度的交通状况,此状况可以帮助算法更好地专注在不确定环境下人类驾驶员行为分析。数据每帧分别包含约13辆机动车辆,5名行人和2辆自行车
https://gamma.umd.edu/researchdirections/autonomousdriving/ad
在链接中有很多使用此数据集的轨迹预测项目。
(5) nuScenes
重磅来了,此数据集是2020年4月提出。其在波士顿和新加坡这两个城市收集了1000个驾驶场景,这两个城市交通繁忙而且驾驶状况极具挑战性。其数据集具有相关论文,可以看看,更好了解此数据集。
https://arxiv.org/abs/1903.11027
此数据集中有预测相关的比赛,可以关注。

https://www.nuscenes.org/prediction?externalData=all&mapData=all&modalities=Any
6 评估指标
当前主要使用的评估指标为几何度量。
几何度量有很多个指标,主要使用的是ADE、FDE、MR。
ADE为均一化欧式距离。FDE为最终预测点之间的欧式距离。MR为未中率。有很多不同的名字,主要就是设一个阈值,预测点迹之间欧式距离低于这个预测就记为命中,高于这个阈值就记为未命中,最后计算一个百分比。
几何度量是衡量预测轨迹与实际轨迹相似性的重要指标,可以很好是代表精度。但是以轨迹预测存在的意义来说,仅仅评估精度是没有意义的。还应有概率度量,用来评估不确定性,尤其是对于多模态输出分布;还有任务层面度量,鲁棒性的度量以及效率的评估这些。
概率度量:可以使用KL散度、预测概率、累积概率来作为概率度量。比如NLL, KDE-based NLL[17]。任务层度量:评估轨迹预测对后端规控的影响(piADE,piFDE)[18]。鲁棒性:要考虑在预测之前,观测到的部分轨迹的长度或持续时间;训练数据的size;输入数据采样频率和传感器噪声;神经网络泛化、过拟合及输入利用率分析;感知模块送入的输入如果有问题是否保证功能正常等等方面的因素。效率:要考虑算力的。
如下图所示,此论文的主要考量为基于真值(蓝色),灰色的目标车预测的紫色与绿色轨迹如果使用几何度量是具有相同的ADE与FDE的,但是不同的预测方式对自车的planning会造成影响,而现在没有这种评估任务层级的度量,于是他们提出piADE与piFDE来做这个事。

7 三个问题
问题1:三种不同的轨迹预测方法:基于物理模型、基于学习、基于规划各自应用场景在什么地方,有什么优缺点呢?
不同的建模方法可以结合并利用不同类型的上下文信息。利用目标的上下文线索、动静态环境可以扩展出所有建模方法。然而,不同的建模方法在结合不同类别的语义信息时表现出不同程度的复杂性和效率。
1.基于物理模型的方法
适用场景:目标、静态环境、动力学模拟可以被显式转移方程建模。
优点:
- 基于物理模型的方法通过选择适当的转移方程,可以很容易地跨环境应用,而不需要训练数据,尽管一些用于参数估计的数据是有用的。在论文中,简单的CV模型也可产生合理的结果。
- 基于物理模型的方法很容易和target agent cues结合进行扩展。
缺点:
- 这种显示建模的方法可能无法很好地捕捉现实世界的复杂性。
- 转移方程在空间与时间上缺乏全局信息,导致可能获得是局部最优解。
这样的缺点导致使用物理的方法限制在短期预测或者obstacle-free的环境。
2.基于学习的方法
适用场景:适合于当前环境具有复杂的未知信息(例如具有丰富语义的公共区域),并且这些信息可以用于比较大的预测范围。
优点:
- 基于学习的方法可以潜在地处理所有类型的上下文信息,这些信息编码在收集的数据集。他们中一些是map-based,另外一些可以用来对上下文信息进一步扩展。
缺点:
- 需要在特定地点收集足够的数据,才能进行训练。
- 上下文信息扩展可能会导致involved learning、数据效率和泛化问题。
- 倾向于在非安全的关键组件中使用,在ADAS中比较在意可解释性,这是基于学习方法无法做到的。
3.基于规划的方法
适用场景:在终点定下来了且环境地图可获得的场景,有很好的表现。
优点:
- 如果满足以上两个条件,其比物理方法可以获得更好的精度,比基于学习的方法有更好的泛化能力。
缺点:
- 传统的规划算法:Dijkstra、Fast Marching Method、optimal sampling-based motion planners会随着目标的数量、环境的大小、预测范围的增加而指数增长。
- 与基于物理的简单模型相比,基于上下文线索的规划方法(如逆向规划的奖励函数和正向规划的模型)的参数是琐碎的,通常更容易学习,但在推理方面,对于高维(目标)智能体状态,效率较低。
基于规划的方法本质上是map-aware 与 abstacle-aware,很自然地使用语义线索进行扩展。通常情况下,他们会将情境复杂性编码到目标/奖励方程中,但这可能无法恰当地整合动态线输入。因此,作者必须设计具体的修改,将动态输入纳入预测算法(Jump Markov Processes、local adaptations of the predicted trajectory、game-theoretic)。与基于学习的方法不同,目标输入很容易被合并,因为前向与逆向的规划过程都基于同一个目标动态模型。
问题2:轨迹预测的问题现在已经解决了吗?
轨迹预测的需求很大程度上取决于应用领域和其中的特定用例场景。短期内可能不能说轨迹预测这个问题已经解决了。以汽车行业举例,因为有专门的标准规定,定义了最大速度、交通规则、行人速度和加速度的分布,以及车辆舒适加速/减速率的规范,其在制定需求和提出的解决方案方面似乎是最成熟的。可以说对于智能汽车的AEB功能,解决方案已经达到了允许工业化生产消费产品的性能水平,对于其所需用例已经解决。至于其他用例,则需要在不久的将来对需求进行更多的标准化和明确的表述。并且对于鲁棒性与稳定性还需要演进。
所以在回答轨迹预测是否已经解决这个问题之前,最起码应该把标准定了。
当前对于机器人领域来说
- 基于物理模型与学习的方法可以在短时间(1-2s)有较高的精度。非常适用于人群的局部运动规划与碰撞避免。最简单的CV模型就对机器人的局部规划有很好的效果。如果考虑行人之间的交互以及因为机器人的存在对行人运动产生的影响,有好多种先进算法。
- 对于需要预测15-20s的去全局路径规划,有很大挑战。需求可以适当放松,而理解动静态上下文输入(长期来看影响运行、在环境地图上的推理、目标的意图推断)则变得十分重要。对于局部和全局路径规划,位置无关方法最适合在各种环境下预测运动。
- 当前机器人预测4.8s的ADE为0.19-0.4m的。简单的速度模型也可以达到0.53m的ADE。9s预测有1.4-2m的ADE。
当前对于自动驾驶领域来说:
- 大多数工作考虑的都是横穿马路的行人:开始走 继续走 停止走。
- 自行车:一个骑自行车的人在接近一个十字路口时,后面有多达五个不同的道路方向。
问题3:当前衡量轨迹预测性能的评估技术是否足够好?
当前对于预测算法缺乏系统性的方法,特别是对于考虑上下文输入以及预测任意数量的目标的轨迹预测方法。
现在大多数作者仅仅使用几何度量(AED, FDE)作为衡量算法好坏的指标。然而对于长时间预测,预测通常是多模态的,并且与不确定性有关,对此种方法的性能评估应该使用考虑到这一点的指标,例如从KLD得到的负对数似然或对数损失。
此外也需要概率度量,其可以更好地反映了人体运动的随机性以及感知缺陷所涉及的不确定性。
还有鲁棒性的评估,需要考量在感知端出现检测错误,跟踪缺陷,自我定位不确定性或地图变化此类场景时系统的稳定性。
同时当前所使用数据集,虽然包含的场景十分的全面,但是这些数据集通常是半自动注释的,因此只能提供不完整和有噪声真值估计。此外,在一些需要长期预测的应用领域中,轨迹长度往往不足。最后,数据集中的目标之间的交互通常是有限的,例如在稀疏的环境里面,目标之间很难有影响。
综上:为了评价预测质量,研究者应该选择更复杂的数据集(包括非凸的障碍、长轨迹和复杂的interaction)以及完整的度量指标(几何+概率)。比较好的方法是根据不同的预测时间、不同的观测周期,不同的场景复杂度设置不同的精度要求。并且应该有鲁棒性评估以及实时性评估。此外应该有相关的指标可以衡量ADAS系统对后端影响程度的指标[18]以及衡量对危险场景敏感性的指标[1]。
8 未来方向
来自于[2]中的讨论,此处为引用。
当前的趋势时用更复杂的方法去超越使用单一模型+KF的方法
方向:
- 使用强化的上下文信息:可以使用更深层次的语义信息,这种语义信息应对静态环境有更好的理解。并且当前使用语义特征进行轨迹预测仍有待于开发
- 关于有social-aware的场景:①当前大多数方法假设所有被观察到的人的行为都是相似的,他们的运动可以由相同的模型和相同的特征来预测,而对高层次社会属性的捕捉和推理还处于发展的早期阶段。②大多数可行的方法基于的假设是人们之间的合作行为,而真实的人可能更倾向于优化个人目标,而不是联合策略,因此结合传统AI+博弈论的方法很有研究前途。
- 对于长期预测,上下文信息变得特别重要,因为要基于情境和周围环境考虑意图。当前许多基于学习的方法将个体视为粒子,用来学习转移信息,以决定未来运动的方向。而通过更多的通过意图驱动的预测来扩展这些模型,类似于人类目标导向的行为,将有利于长期预测。
- 大多数基于规划的方法依赖于一组给定的目标,这使得它们在没有事先知道目的地或可能目的地数量过高的情况下无法使用或不精确。这使得基于语义信息对目的终点进行自动推断变得重要。或者可以动态识别环境里面的可能目的地,并基于此进行轨迹预测。这样就可以在未知的环境里面使用基于规划的方法了。
- 现在的方法都是集中于解决某一类特定的任务,比如当环境中存在明显的运动模式时,或者当环境的空间结构和目标agent的目的地预先已知时。而轨迹预测方法需要能适应未定义的/不断变化的环境,并且可以处理突发情况。这就需要迁移学习以及一些应对新环境的方法,这种情况下,学习和推理基本的不变的规则,或者通用的行人行为或者碰撞避免是不合适的。领域自适应是可以用于学习泛化模型。
- 另外需要注意的方向:鲁棒性与可集成性。
综上:简洁来说就是上下文信息用的要更深入、最好对不同目标有不同行为模型、博弈论、基于更多信息做更鲁棒的意图预测、对终点的自动推断、对新环境的泛化问题、鲁棒性与可集成性。