














1、面向对象设计是 DDD 的核心
DDD 着重于将业务领域中的概念和对象映射到对象中,使对象模型能够更好地反映业务的真实情况,从而使设计更具可理解性和可维护性。
DDD 是一种领域驱动的设计方法,旨在通过建立对领域模型的清晰理解来解决业务问题。和事务脚本不同,DDD 使用面向对象设计来应对复杂的业务场景。
简单来说,DDD 是由领域对象承载业务逻辑,所有的业务操作均在模型对象上完成,同一对象上不同的业务操作构成了对象的生命周期。
我们以订单为例,如下图所示:
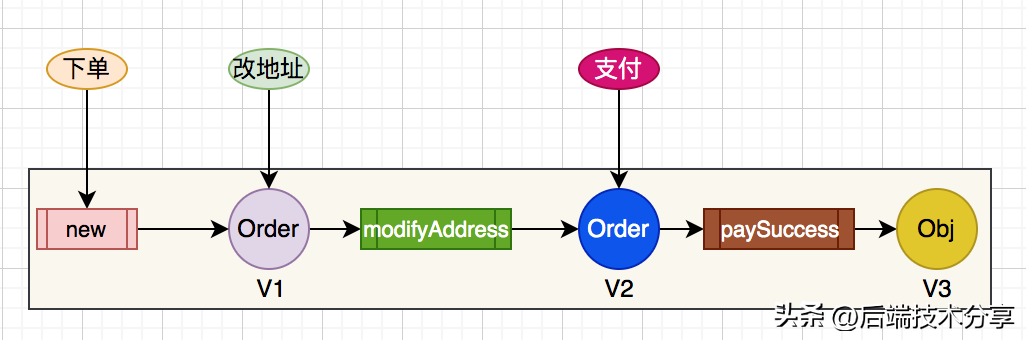
- 首先,用户操作下单,使用提交数据为其创建一个 Order 对象,版本 V1;
- 随后,用户进行改地址操作,调用 Order 对象的 modifyAddress 方法,Order 从原来的 V1 变成 V2;
- 用户完成支付后,调用 Order 对象的 paySuccess 方法,Order 从 V2 变成 V3;
从图上可见,在 DDD 设计中,所有的业务逻辑均由业务对象完成,所以面向对象是 DDD 设计的核心。
2、为什么需要 Repository?
假设,有一台非常牛逼的计算机,计算资源无限、内存大小无限、永不掉电、永不宕机,那最简单高效的方式便是将模型对象全部放在内存中。
但,现实不存在这样的机器,我们不得不将内存对象写入磁盘,下次使用时,在将其从磁盘读入到内存。
整体结构如下图所示:
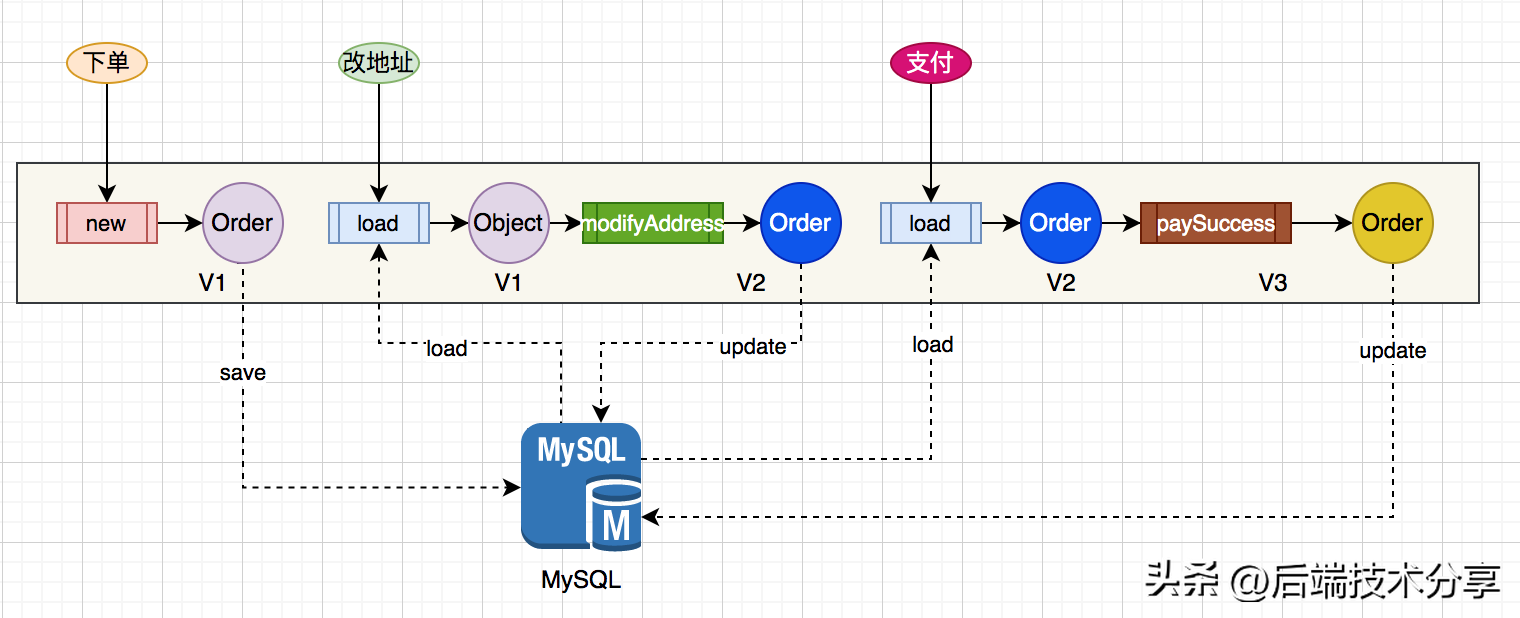
和上图相比,具有如下特点:
- 业务操作没变,仍旧依次完成 下单、改地址、支付等操作。
- 引入持久化存储(MySQL),可以将 Order 对象存储于关系数据库。
- 配合 Order 的生命周期,操作中增加 save、load 和 update 等操作。
- 用户下单创建 Order 对象,通过 save 方法将 Order 对象持久化到 DB。
- 接收到业务操作,需执行load,从 DB 加载数据到内存 并对 Order 对象的状态进行恢复。
- 在业务操作完成后,需执行update,将 Order 对象的最新状态同步的 DB。
相对全内存版本确实增加了不小的复杂性,为了更好的对这些复杂性进行管理,引入 Repository 模式。
在领域驱动设计(DDD)中,Repository 是一种设计模式,它是用来存储领域对象的容器。它提供了一种统一的方式来查询和存储领域对象。Repository提供了对底层数据存储的抽象,允许应用程序在没有直接与数据存储技术交互的情况下访问数据,同时该抽象允许在不修改应用程序代码的情况下更改数据存储技术。
3、什么才是好的 Repository ?
好的 Repository 应该在满足业务需求的前提下,具备以下特性:
- 高内聚:好的 Repository 应该满足单一职责原则,每个 Repository 只关注一种领域对象的存储;
- 松耦合:好的 Repository 应该通过抽象接口与其他层进行交互,保证它们之间的耦合度低;
- 简单易用:好的 Repository 应该提供一组易于使用的方法,方便开发人员使用;
- 可维护性:好的 Repository 应该易于维护,维护人员不需要长时间阅读代码才能了解它的工作原理;
说的太官方了,用人话就是:
- 需要一个统一的 Repository 接口,用于对易用方法save、load、update进行管理
- 为每个聚合根创建一个 Repository 接口,继承自 统一Repository,只关注该聚合根的存储
- Repository 的实现尽可能的简单,最好不用实现(人都是懒的)
4、初始 Spring Data
Spring Data是一个框架,旨在简化数据访问层的开发。它通过抽象和模板化方法,使得与各种数据存储(如关系型数据库,文档数据库,图形数据库,缓存等)的交互变得更加简单和标准化。
Spring Data 通过提供简单的、通用的数据访问接口(如Repository)和自动生成实现代码,使得开发人员不必编写重复的数据访问代码。这样,开发人员可以专注于业务逻辑,而无需关注数据存储和访问的细节。
总的来说,Spring Data的主要解决的问题是:简化数据访问层的开发,提高代码复用性,降低开发复杂度。
Spring Data 对多种数据存储提供了支持,本文以 Spring Data Jpa 为例,快速实现应用程序与关系数据库的交互。
(1)引入 Spring Data Jpa
Spring Data JPA 是 Spring Data 家族的重要成员,主要解决 Java 应用程序使用 JPA 完成对数据库的访问问题。它提供了一种简单而灵活的方法来访问和管理数据,并且可以消除重复代码和提高开发效率。
首先,需要在pom中 引入 spring-data-jpa-starter,具体如下:
其次,引入 MySQL 驱动,具体如下:
Spring Data Jpa 默认实现是 Hibernate,而 Hibernate 是目前最流行且功能最强大的 JPA 实现,它提供了强大的映射、查询和事务管理能力。
(2)完成配置
在 application.yml 增加 DB 和 Jpa 相关配置,具体如下:
在启动类上启用 Spring Data Jpa。
(3)使用 Repository
一切就绪,接下来就可以为模型创建专属 Repository,具体如下:
至此,Order 的专属 Repository 就开发完成。
不知道你是否存在疑问:
- 说好的统一的易用方法在哪里?
- 为什么没有看到实现代码?
一般情况下,JpaRepository 接口中的方法就能满足大部分需求,典型方法包括:
方法 | 含义 |
save、saveAll | 保存或更新,如果数据库没有则执行 insert 操作,数据库有则执行 update 操作 |
findById | 根据主键查询实体 |
findAllById | 根据主键批量获取实体 |
count | 查询数量 |
delete、deleteById | 删除数据 |
findAll | 分页或排序 |
5、实战--订单
为了体现 Spring Data Jpa的强大功能,以最常见的订单为例,业务模型如下图所示:
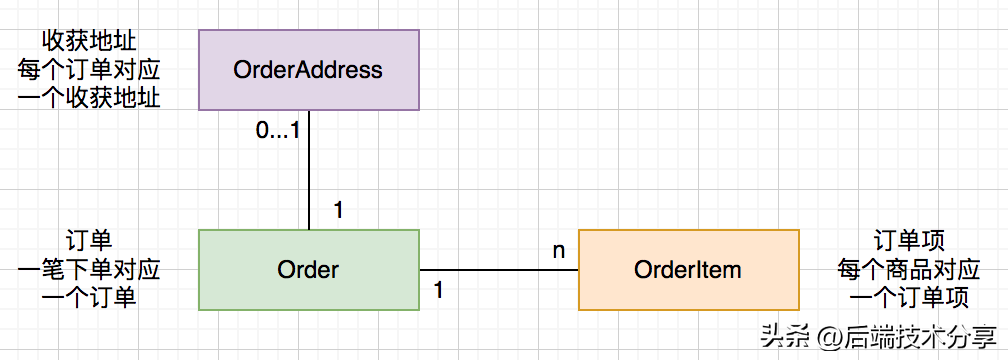
- 一笔下单对应一个订单(Order)
- 一个订单可以有一个收获地址(OrderAddress)
- 一个订单可以关联多个订单项(OrderItem)
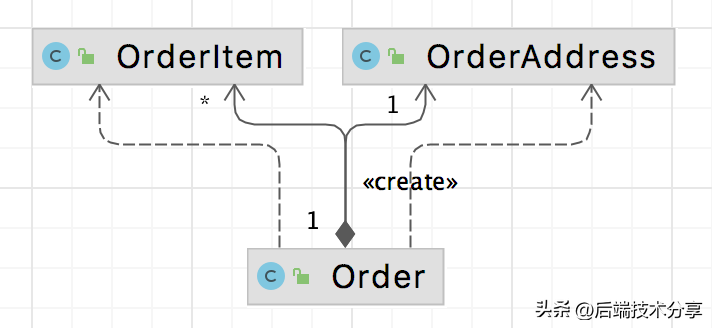
对应到领域模型如下:
核心代码如下:
(1)生单
先简单看下生单的核心代码,具体如下:
单元测试,具体如下:
运行单元测试,打印以下 SQL:
是否发现 Spring Data Jpa 的强大之处:核心逻辑全部内聚在 Order 类,在没有写任何数据层访问代码的前提下,一个 save 方法便可以将这组高内聚的对象保存到 DB。
(2)修改地址
修改地址核心代码如下:
首先,看一个添加地址的场景,生单时没有提供收货地址,生单后修改地址:
运行单测可,控制台输出以下信息:
看一个更新地址的场景,生单时设置收货地址,然后操作修改地址:
运行测试用例,输出如下信息:
从该用例可看出,Jpa 具有:
- 懒加载能力,只有在访问到关联数据时才对数据进行加载。
- 自动同步能力,新增对象通过 insert 将其插入数据库,修改对象通过 update 对数据库数据进行更新。
(3)支付
修改地址是简单的一对一,那对于较复杂的一对多,Jpa 是否也具有 懒加载 和 自动同步能力呢?
支付核心代码如下:
单元测试如下:
运行单元测试,控制台出现信息如下:
从 SQL 中可见,在复杂的 一对多 场景,懒加载 和 自动同步能力 仍旧有效。
从代码上可以清晰得出:在 Spring Data Jpa 的助力下,无需编写任何数据层访问代码,便可以完成领域对象的管理。
6、小结
DDD 和 Jpa 都是面向对象设计的巅峰之作,两者结合威力巨大。
结合使用 DDD 和 JPA 可以有效地将领域模型与数据库持久化技术相结合。开发人员可以使用领域驱动的方法管理数据,并通过 JPA 将数据存储在数据库中,从而避免冗长的数据持久化代码。
此外,使用 DDD 和 JPA 还有其他优势:
提高代码可读性:领域驱动的设计方法可以帮助开发人员更清晰地了解领域模型,使代码更易于阅读和维护。
减少代码量:使用 JPA 可以减少代码量,因为开发人员不需要编写手动的数据持久化代码。
提高代码的可重用性:通过使用领域模型,开发人员可以创建一组可重用的实体,并在多个地方使用它们。
提高代码的可扩展性:使用 DDD 和 JPA 可以使代码更易于扩展,因为它们遵循领域驱动的设计方法。
总之,使用 DDD 和 JPA 可以帮助开发人员更有效地解决业务问题,提高代码的可读性,可重用性和可扩展性,并减少代码量。


















