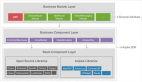
1、背景介绍
1.1 得物pandora介绍
什么是流量录制回放?流量录制回放是应用端通过挂载注入录制器探针自动注册到服务端形成录制流量回流,将所有外部调用依赖的响应内容(如数据库、分布式缓存、外部服务响应等)进行完整记录。由平台向回放器分发流量回放指令。其核心价值是通过直接录制生产的真实数据,将生产真实数据转化成可复用、可执行的流量,快速地在测试环境中进行回放比对接口返回值和中间链路的验证。
得物版本的流量录制回放平台pandora在官方开源版本上进行了很大的拓展,支持了很多官方版本不支持的子调用和入口调用。此外,平台还对得物的中间件进行了诸多适配工作,避免了大量的回放失败噪音。

1.2 市场工具对比
目前市场上已知的流量录制回放平台大部分都是在Jvm-Sandbox-Repeater基础上进行二次开发和改造,并且多数都是只支持Java语言。核心原理也都是通过录制线上真实流量然后在测试环境进行回放,验证代码逻辑正确性。
2、实践落地
2.1 协作模式
在具体的实施层面,目前采用的是业务测试,平台研发,业务研发三方协同的模式。任务分拆如下图所示。

得物流量回放实施模式
2.2 阶段应用
流量回放在各阶段的理想实施应用:
- 提测阶段卡点:聚焦核心场景,低成本验证每次提测对于核心场景的影响;
- 测试回归阶段卡点:全量场景,重点追求覆盖场景全面性,验证新功能对历史功能的影响;
- 预发环境回归:目前预发跟生产同库,未来会推动落地基于预发&生产环境的流量回放,尽可能拉近录制时环境和回放时环境的仿真差异,从而降低回放阶段的噪音影响;
在得物的整体QA体系中,流量回放短期聚焦在回归兜底保障上。

得物迭代&项目时间轴
2.3 实践落地
流量回放的开展自发起后,在本域由探索尝试阶段逐渐过渡到应用场景拓展阶段。
订单流量回放模式
在经过一段时间的探索,摸索出了一套适用于本域迭代的模式。

Part1、尝试接入
团队开始开展流量回放的专项之后,通过调研,选取了40%的服务优先接入。
1. 阶段目标
- 完成30%P0应用top10 接口100%场景覆盖,形成迭代落地质量卡点,完成适用性和提效分析;
- 增加订单域流量回放人员投入,落地质量卡点,覆盖5%回归场景;
2. 实施方案
- 调研应用的特性,尝试接入流量录制回放;
- 梳理服务的P0接口及用例,配置对应的接口及用例标签;
- 用例自动沉淀到用例集后,在回归阶段尝试进行流量回放。
3. 收益成果
- 完成30%应用形成落地质量卡点,落地15%用例回归场景,验证方案可行性和易用性,摸索研发测试协同机制。
Part2、探索升级
上一阶段花费大量的时间梳理接口配置标签,用例沉淀速度缓慢,并且收益与投入不成正比,因此调整了策略,应用智能化分析进行提效,快速沉淀用例,扩大用例量及覆盖的接口量。45%业务应用接入并均实现强卡点落地,配合平台侧优化,解决大部分组件适配和使用问题,迭代应用流程以及应用指标分析机制基本跑顺。
1. 阶段目标
- 应用:接入的应用交由对应的服务负责人,负责对应服务的接口维护运营及沉淀、排错分析;
- 用例:尝试探索新的用例沉淀方式,进一步扩大用例量,增加覆盖的接口量;
- 排错:根据服务的用例量以及接入的时间,提升测试排错能力,阶段2结束测开排错达到五五开;
2.收益成果
- 从开始试点到应用卡点,沉淀的用例量也在应用热点流量方案之后开始了升级之路。接入的应用数也超过原定目标达到50%且均实现强卡点落地。
- 应用智能化分析策略提效效果明显,沉淀的用例数成指数型增长,接入应用的P0接口覆盖率达到100%。
- 测试排错能力提升,每迭代流量回放发现的bug数也在增加,新方案的可实施性和可推广性基本符合预期。
Part3、专项提速
在沉淀的用例case大量的增加、用例沉淀速度提效明显的前提下,流量回放在迭代的应用中发现更多的缺陷,规划扩大接入的应用以及覆盖的接口范围。
1. 阶段目标
- 应用接入:新增40%应用接入,接入应用占比合计90%;
- 排错:提升测试的排错能力,新版本排错由平台研发转交业务研发,测试开发排错占比五五开;
- 用例量:加速沉淀用例量,扩大覆盖的范围,至少65%的应用完成全量用例沉淀;
- 卡点:接入应用达到100%卡点,提升排错速度,部分应用由生产卡点转为预发卡点;
- 全域接入应用接口维度覆盖率98%以上,接口配置完善度98%以上,全量用例路径覆盖率60%以上。
2. 收益成果
随着应用的接入,沉淀的用例量也在扩大,发现的问题数也在增多。同时也增加覆盖率的指标来衡量流量回放用例覆盖的代码占总代码行的比值。随着对覆盖率的关注,平台采样策略也进行了一个调整,删除所有历史沉淀用例,仅沉淀新策略实施之后录制的流量。
- 流量回放接入90%应用,扩大应用接入和case沉淀,超预期达成目标,沉淀应用Case量是原计划的3倍,此阶段累计发现缺陷数占全域流量回放发现的bug数的45%,充分验证了落地策略的有效性;
- 从阶段3本域发现的缺陷统计来看,其中回归类BUG占比38%,发现线上自有/隐藏问题占比8%,迭代过程中代码问题(日志报错)和代码规范类问题占比46%,性能问题占比8%;
- 接口配置完善度100%;接口维度覆盖率96.49%;全量用例路径覆盖率79.32%,全量代码覆盖率平均39.8%;
3、总结分析
3.1 问题归类分析
3.1.1 累计发现的缺陷分类:

3.1.2 累计发现的缺陷来源分类:

3.1.3 典型案例:
- 回放时系统异常,排查之后定位为NPE类问题,如:


- response返回的业务字段diff对比不一致,如:

通过对缺陷以及缺陷来源的归类不难看出:
- 流量回放发现拦截的问题近一半都是会引起生产业务报错的,其中包括像金额不对涉及资损的问题以及字段传值不对、枚举类型取错等缺陷;作为生产发布前的最后阶段的防线之一,充分展现了流量录制回放作为对测试回归的兜底能力的补充手段的重要性。
- 45%左右的问题是手工测试过程中难以发现隐藏比较深的代码层面问题,例如NPE报错、入参出参字段未序列化等,这些问题如果仅仅通过前端测试或接口测试不看日志不一一对比所有字段势必会将问题带到生产环境,最终影响生产环境的稳定性。
- 6%左右的性能问题,例如存在重复子调用,影响接口RT,如果不在生产发布前发现解决,势必给用户体验带来一定的挑战。
- 从缺陷的来源上看,发现的缺陷来源还是集中在项目迭代需求和技术优化上,充分验证了流量回放整体提速后的有效性以及对测试覆盖兜底能力的补充。
- 通过对失败用例的排错分析经验的累积和分享培训,参与专项的测试团队的整体技术水平通过流量回放专项提速在技术氛围上有明显提升,培养了多位同学对自身负责模块的实现的代码走读能力,以及深挖缺陷的code diff能力。
3.2 适用性分析
- 适用场景
适用于返回数据量大、业务流量也很大,以及读取业务占比大的场景,如ToC产品。
- 不适用场景
- 挂载沙箱后开启录制会导致RT瞬间飙高,影响生产服务的稳定性。
- 异步场景目前流量回放平台不支持。
- 需要验证数据库的落地,节点的流转的链路测试,需要自动化。
先投入能迅速形成能卡点有收益的应用(迭代代码变更相对少,分层结构比较好,异步少,写操作少),把看得到的使用效果做出来。
流量回放能否完全替代手工回归以及自动化?
目前来看,答案是否定的。首先,从沙箱挂载到接口配置再到流量录制这一套流程下来,也需要较长的时间才能达到较高的用例覆盖,对于一些边界极端场景还是需要手工设计;其次,流量录制回放是后置的回归兜底,更侧重于对历史逻辑的回归验证。
1、接口覆盖不全。迭代需求新接口,未配置关联录制,不在流量回放的录制范围。
2、全量代码覆盖率不高。接口已经配置覆盖了,但是由于采样比例小场景极端等原因,接口的分支场景并没有录制到未被覆盖。
3、排错能力的高低影响。接口覆盖了,排错的时候由于新加了子调用,导致失败的用例在排错的时候容易被简单定义为代码变更。
4、平台问题。diff比对异常,显示回放成功,异步线程的回放是一个待攻克的难点。
3.3 面临的挑战
3.3.1 排错的效率
录制流量后对流量进行回放,发现回放结果比对失败的很多。经过对失败原因的排查与分析,有些是代码bug导致的失败,但更多的失败不一定是代码bug,常见噪音主要包含:
- 代码修改,新增或删除了子调用,导致mock失败
- 平台不支持的子调用,导致失败
- 时间戳相关的子调用,diff不一致
- 子调用中使用随机参数相关,导致mock匹配不上
- repeater代码自身缺陷
- 业务自增数据差异
- 配置中心数据不一致
- 返回无序元素集合,造成结果对比误差
失败原因很多,真正有效的失败数很少。如此一来,每次回放失败的排查成本就非常高。给业务的推进造成了巨大的阻碍。
原版repeater上报的信息不够丰富,很多情况需要看日志才能排查。目前也没有公开成熟的参考的方案。平台也进行了一些初步的探索,对回放失败的场景自动进行归类,上报更丰富的数据信息提供排查指引,帮助排查人员聚焦定位问题。同时平台也针对一些噪音进行自动识别并在回放时自动过滤降噪。
回放失败分类 | 界面提示 | 界面展示信息 |
子调用多调用 | 错误 | 得物链路traceId, 多调用的参数,调用堆栈,是否参数不匹配,是否完全多出来一次调用,等等 |
子调用少调用+回放时捕获到异常 | 错误 | 得物链路traceId, 回放轨迹,异常堆栈,参数 |
子调用少调用 | 错误 | 得物链路traceId, 回放轨迹 |
入口返回diff有差异 | 错误 | 得物链路traceId, 返回数据的diff比对 |
仅回放时捕获到异常 | 告警 | 得物链路traceId, 异常堆栈,参数 |
3.3.2 异步线程录制回放问题
入口主线程不等子线程执行完就返回的异步场景,当前的策略是用户可配置对异步子线程的多调用忽略,只关注主线程的执行情况。这一方式虽然可以提升这种异步线程场景的回放成功率,但是损失了异步子线程业务逻辑的回归能力。

上面的案例就是由于应用开启了排查提效优先的开关,忽略了异步子线程的调用,导致diff比对异常,显示回放成功。该接口在生产发布时报了异常,String类型长度超长被try catch,埋点丢失。
4、展望&未来规划
流量录制回放作为测试领域的一个新兴事物,在诞生初期就吸引了广大测试同仁的关注,市场上也有些公司也对此进行了一些实践。我们对流量录制回放的实践还处于起步的阶段,一些问题的解法也在探索中 。
预发只读接口非mock回放
在得物预发环境是联通生产环境的数据库和下游应用,因此对于预发进行不mock的回放,特别是对只读接口进行不mock的回放能够在上线前的最后阶段进行一次兜底的回归校验。最难解决的问题是,当前是只读的接口难以保证后续的变更不会引入写操作。在当前阶段开放这一功能会引入额外的资损类风险敞口。
对此问题,每次回放前都进行人工校验可能可以解决,但是又引入了极大的效率问题。如何高效地保证在预发/灰度环境进行不mock流量回放不会产生资损风险,是一个值得探索的问题,需要研发跟测试的共同努力。
方案1-单回放(准实时回放)

方案1落地遇到的问题:
1.配置中心的数据不一致,噪音比较大
2.时效问题,有10S的时差,一些业务对时效要求比较高
方案2-双回放(实时回放)

方案2不仅避免了上面方案1的问题,另外后续规划还可以根据覆盖率沉淀有效用例集,手工添加异常用例。
通过一段时间的运行,目前已经看到了一些流量录制回放在业务迭代中产生了价值,发现了一些隐藏bug。接入流量回放明显的变化是能够将测试从繁重的回归测试、用例梳理维护等重复性高的劳动中解放出来,将重心放在测试计划的设定、思考测试策略以及自我提升的实践上,比如做些辅助排错提效的coding能力提升和加强对业务的熟悉的宽度和深度上,从而最大程度的保障业务系统的质量和稳定性。
未来期望能在不断的实践中把得物的流量录制回放体系建设得越来越完善,解放更多的生产力,产出更多的价值。