Linux Namespace是Linux提供的一种内核级别环境隔离的方法。学习过Linux的同学应该对chroot命令比较熟悉(通过修改根目录把用户限制在一个特定目录下),chroot提供了一种简单的隔离模式:chroot内部的文件系统无法访问外部的内容。Linux Namespace在此基础上,提供了对UTS、IPC、mount、PID、network、User等的隔离机制。Namespace是对全局系统资源的一种封装隔离,使得处于不同namespace的进程拥有独立的全局系统资源,改变一个namespace中的系统资源只会影响当前namespace里的进程,对其他namespace中的进程没有影响。
相关命令:
ip netns: 管理网络namespace
用法:
ip netns list
ip netns add NAME
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
1.
2.
3.
4.
5.
6.
7.
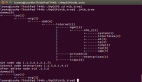
下面使用ip netns来演示创建net Namespace。
shell A
#创建一对网卡,分别命名为veth0_11/veth1_11# ip link add veth0_11 type veth peer name veth1_11#查看已经创建的网卡#ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 5e:75:97:0d:54:17 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.1/24 brd 192.168.1.255 scope global eth0
valid_lft forever preferred_lft forever
3: br1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/24 scope global br1
valid_lft forever preferred_lft forever
96: veth1_11@veth0_11: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 5e:75:97:0d:54:0e brd ff:ff:ff:ff:ff:ff
97: veth0_11@veth1_11: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether a6:c7:1f:79:a6:a6 brd ff:ff:ff:ff:ff:ff
#使用ip netns创建两个net namespace# ip netns add r1# ip netns add r2# ip netns list
r2
r1 (id: 0)
#将两个网卡分别加入到对应的netns中# ip link set veth0_11 netns r1# ip link set veth1_11 netns r2#再次查看网卡,在bash当前的namespace中已经看不到veth0_11和veth1_11了# ip a1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 5e:75:97:0d:54:17 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.1/24 brd 192.168.1.255 scope global eth0
valid_lft forever preferred_lft forever
3: br1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/24 scope global br1
valid_lft forever preferred_lft forever
#接下来我们切换到对应的netns中对网卡进行配置#通过nsenter --net可以切换到对应的netns中,ip a展示了我们上面加入到r1中的网卡# nsenter --net=/var/run/netns/r1 /bin/bash# ip a1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
97: veth0_11@if96: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether a6:c7:1f:79:a6:a6 brd ff:ff:ff:ff:ff:ff link-netnsid 1#对网卡配置ip并启动# ip addr add 172.18.0.11/24 dev veth0_11# ip link set veth0_11 up# ip a1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
97: veth0_11@if96: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN qlen 1000
link/ether a6:c7:1f:79:a6:a6 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 172.18.0.11/24 scope global veth0_11
valid_lft forever preferred_lft forever
-----> 切换至shell B执行
------------------------------------------------------------------#在r1中ping veth1_11# ping 172.18.0.12
PING 172.18.0.12 (172.18.0.12) 56(84) bytes of data.
64 bytes from 172.18.0.12: icmp_seq=1ttl=64time=0.033 ms
64 bytes from 172.18.0.12: icmp_seq=2ttl=64time=0.049 ms
...
#至此我们通过netns完成了创建net Namespace的小实验
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
shell B
#在shell B中我们同样切换到netns r2中进行配置#通过nsenter --net可以切换到r2,ip a展示了我们上面加入到r2中的网卡# nsenter --net=/var/run/netns/r2 /bin/bash# ip a1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
96: veth1_11@if97: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 5e:75:97:0d:54:0e brd ff:ff:ff:ff:ff:ff link-netnsid 0#对网卡配置ip并启动# ip addr add 172.18.0.12/24 dev veth1_11# ip link set veth1_11 up# ip a1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
96: veth1_11@if97: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 5e:75:97:0d:54:0e brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.12/24 scope global veth1_11
valid_lft forever preferred_lft forever
inet6 fe80::5c75:97ff:fe0d:540e/64 scope link
valid_lft forever preferred_lft forever
#尝试ping r1中的网卡# ping 172.18.0.11
PING 172.18.0.11 (172.18.0.11) 56(84) bytes of data.
64 bytes from 172.18.0.11: icmp_seq=1ttl=64time=0.046 ms
64 bytes from 172.18.0.11: icmp_seq=2ttl=64time=0.040 ms
...
#可以完成通信
切换至shell A执行 <-----
#过滤系统挂载可以查看cgroup# mount |grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
#如果系统中没有挂载cgroup,可以使用mount命令创建cgroup#挂载根cgroup# mkdir /sys/fs/cgroup# mount -t tmpfs cgroup_root /sys/fs/cgroup#将cpuset subsystem关联到/sys/fs/cgroup/cpu_memory# mkdir /sys/fs/cgroup/cpuset# sudo mount -t cgroup cpuset -o cgroup /sys/fs/cgroup/cpuset/#将cpu和memory subsystem关联到/sys/fs/cgroup/cpu_memory# mkdir /sys/fs/cgroup/cpu_memory# sudo mount -n -t cgroup -o cpu,memory cgroup /sys/fs/cgroup/cpu_memory