公司最近开发了一个新项目,设计表时由于有些字段需要对外展示,所以使用了雪花算法生成的id做主键。
不过有位同事对此提出了异议,认为雪花算法生成的id不是顺序递增的,会对MySQL的性能造成影响。
经过交流,发现持有这种认知的还有好几位同事,估摸着对此有疑问的朋友也不少,所以今天我们来分析一下,用雪花算法生成的id做主键,对MySQL性能到底有没有影响?MySQL必须使用连续递增的主键才能发挥最大性能?
既然要分析不同主键的性能,那么就得先了解一下MySQL的数据是如何存储的。
相信只要稍微了解过MySQL的朋友估计都知道,MySQL的InnoDB引擎采用B+树来存储数据,为了数据的安全性,这些数据最终会持久化到磁盘上。
那么我们在查询或者修改数据时,如果每次都把数据全部从磁盘加载到内存好像不太现实,每次只读一条数据又太浪费IO,那怎么办呢?
于是设计MySQL的这些大神们提出了页的概念,即将数据保存到很多个页上面,内存和磁盘交互时以页为单位。
默认情况下,一个页的大小是16KB,也就是说,每次从磁盘会最少加载16KB的数据到内存里。反过来,每次最少把16KB的数据从内存中持久化到磁盘。
这样,时间和空间都利用到了,最大化的保证了性能。
当然,页的种类也有很多,比如保存表空间信息的页,undo日志页,存放数据的数据页等,本文中我们只讨论数据页和目录页。
下图就是一个InnoDB数据页的结构,大家心里有一个印象即可。
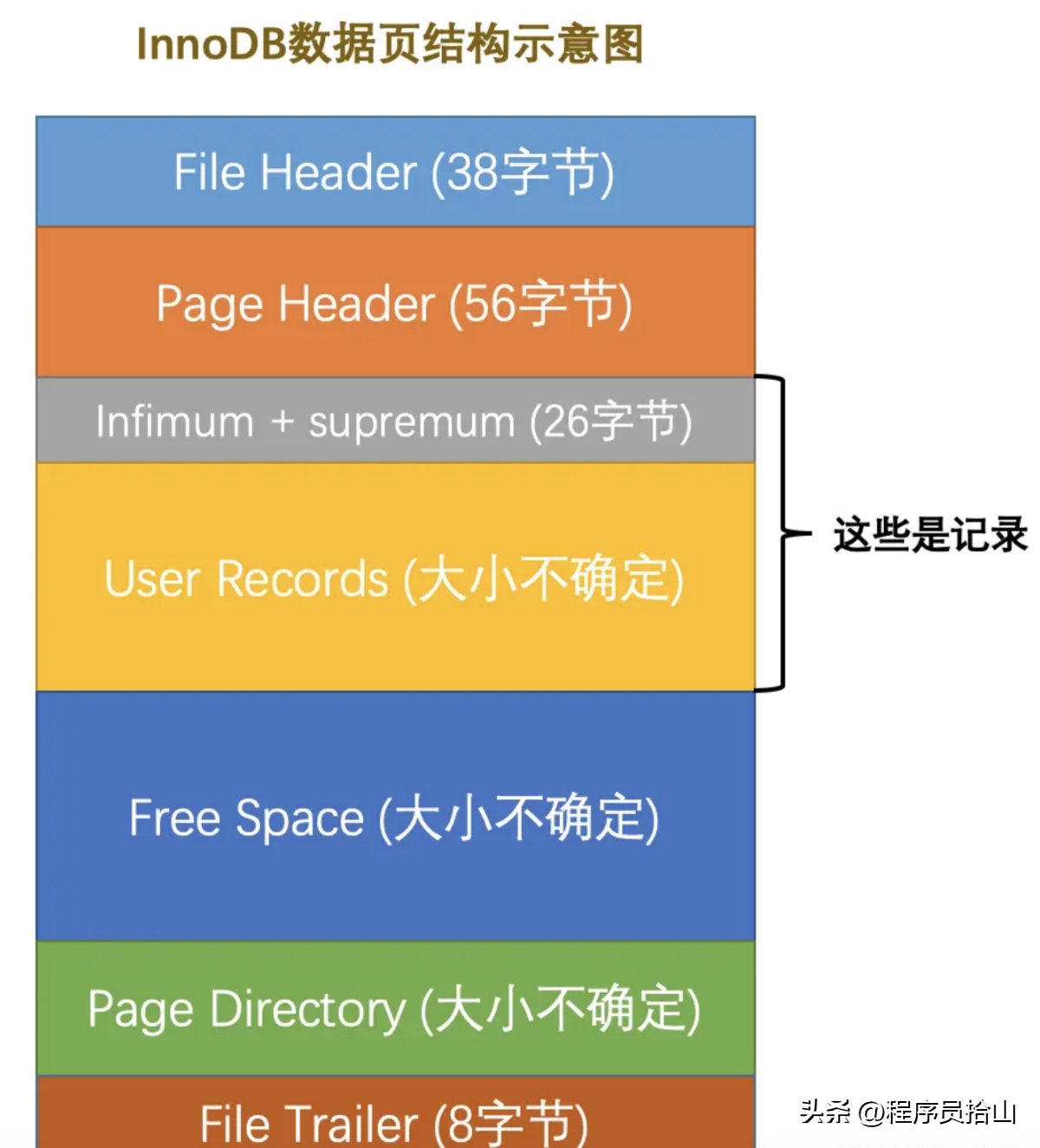
User Records就是用来真正保存我们的数据的,我们看一下数据是如何在页中保存的。
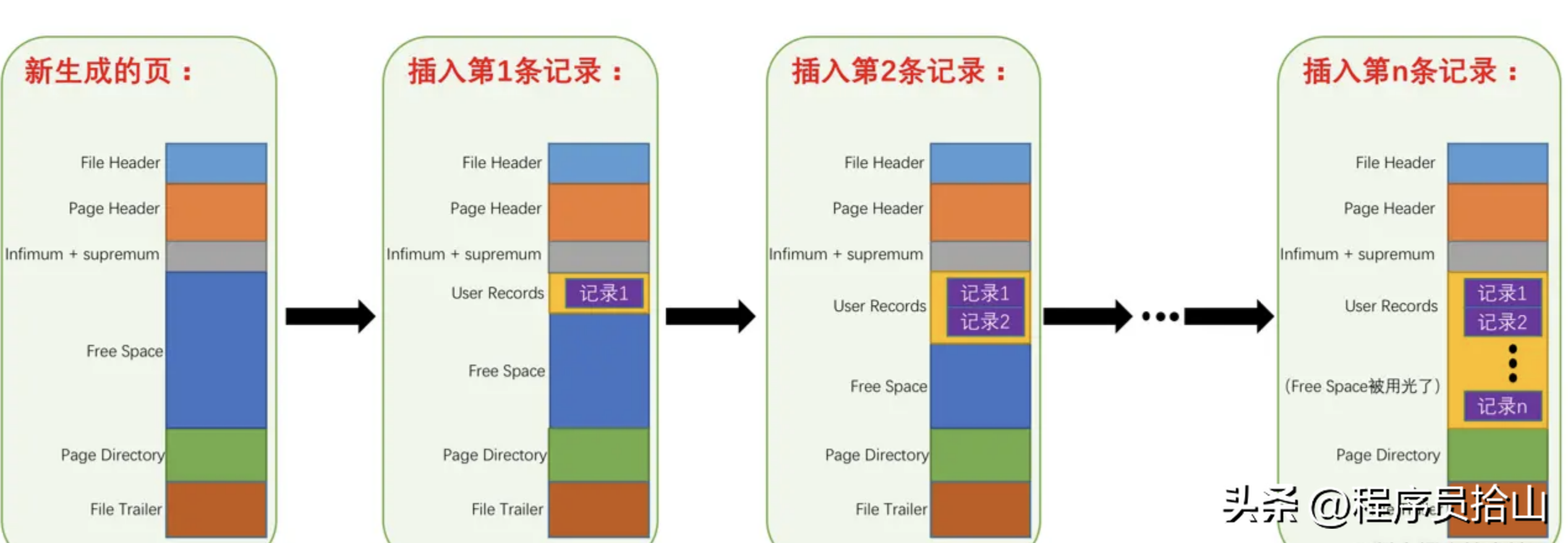
需要特别注意的是,为了性能,这些记录是按照主键的大小按从小到大顺序排放的,最终组成一个单向链表。另外每个数据页都会生成一个页目录,通过主键查找某一条记录时通过二分查找法即可快速找到需要的数据。
上面我们提过,一个页默认只有16KB,也就是说存储的数据是有限的,所以当要存储很多数据时,就需要申请很多数据页,如下所示:
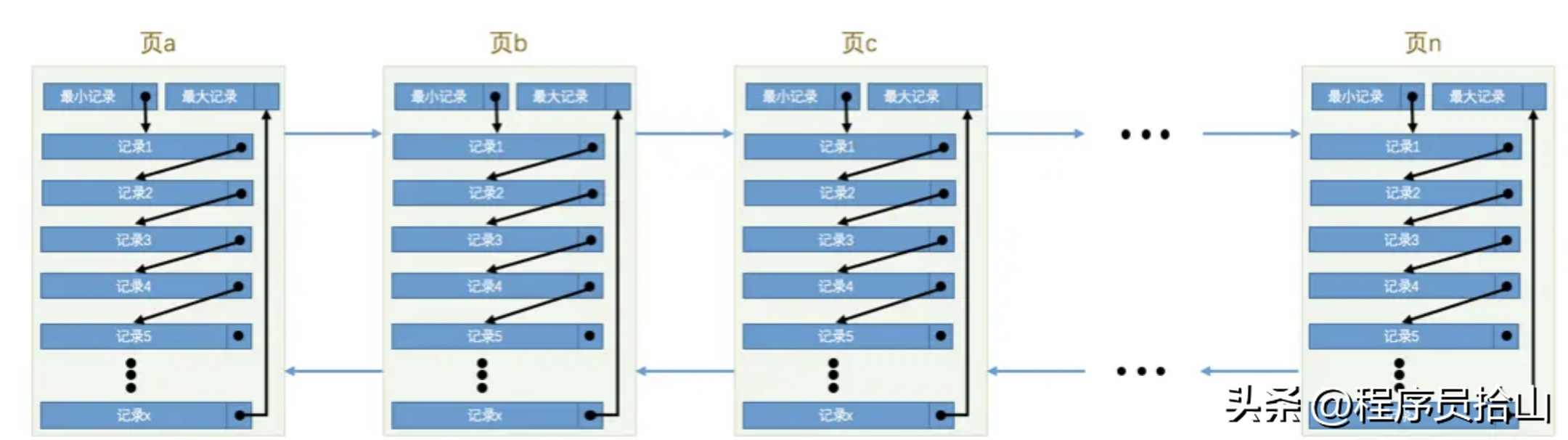
从上图中我们可以看到,每个数据页都保存了很多条记录,相邻页之间还通过双向链表保存着联系。
需要注意的是,这些数据页在物理空间上不一定是连续的地址。
到这里我们知道了MySQL通过数据页来存储数据,但是随着表数据的增多,会带来一个很明显的问题:页太多了不好管理。
所以InnoDB的大神们又设计了目录页(目录页+数据页就组成了一颗索引树)。
看名字也知道,目录页只是一个目录,不会存储具体的数据。
它保存的数据其实特别简单:主键和页号。
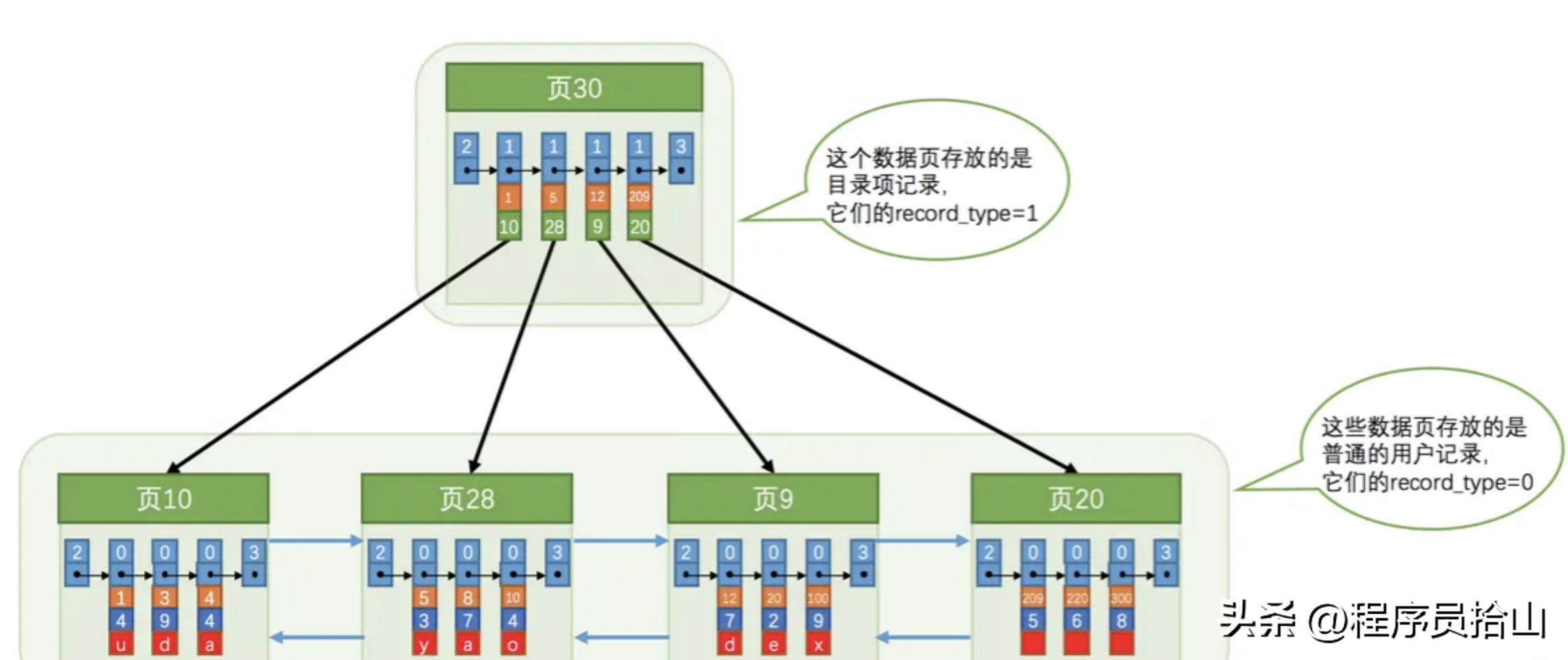
从上图中我们可以看到,页30是一个目录页(可以把他当做树的根节点),页10、页28、页9、页20是真正存放数据的数据页。
在目录页中,会存放每一个数据页的最小主键id以及对应的页号,并且按照主键id排序。
在数据页中,数据也是按照主键从小到大排序的,并且后一个页的最小记录会比上一个页的最大记录大,总体来说,这些页的数据是递增的。
注意!是递增,但是并没有要求顺序递增。
因为对于二分查找法来说,只要数据是有序递增的,就可以保证其快速查找到我们需要的数据了。
以查找id=8的记录为例,首先在根节点通过二分查找法找到记录5,对应的页号是28,然后找到页28,通过二分法找到主键为8的记录。
现在回到我们的问题,雪花算法生成的id会对MySQL性能造成影响吗?
雪花算法的一大特性是什么呢?
大致递增。
换句话说,只要是递增的,哪怕我们用JAVA的AtomicInteger或者通过redis的incrmentBy来生成主键id也没问题。
雪花算法就不过多介绍了,有想了解的朋友可以看一下这篇文章。雪花算法介绍。
另外再多说一句:MySQL自增主键虽然申请时是表级全局递增的,但是最后保存到表中就不一定了。
举个简单的例子,批量保存10条数据,由于某些原因,这个事务操作回滚了。当你再插入一条数据时,你会发现上次申请的10个id已经被浪费掉了,表中的id是从11开始的。
MySQL的数据结构和索引是一个庞大的系统,很难通过一篇简单的文章将其彻底讲清楚,如果你对本文有不同见解,也欢迎在评论区交流。