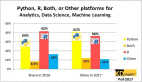
Pandas 为 Python 中数据分析提供了基础和高级的构建组件。Pandas 库是用于数据分析与数据操作的最强大和最灵活的开源分析工具之一,并且它还提供了用于建模和操作表格数据(以行和列组织的数据)的数据结构。
Pandas 库有两个主要的数据结构:第一个是 “系列Series”,该数据结构能够很方便地从 Python 数组或字典中按位置或指定的索引名称来检索数据;第二个是“数据帧DataFrames”,该数据结构将数据存储在行和列中。列可以通过列名访问,行通过索引访问。列可以有不同类型的数据,包括列表、字典、序列、数据帧、NumPy 数组等。
Pandas 库可以处理各种文件格式
有各种各样的文件格式。用于数据分析的工具必须能够提供处理各种文件格式的方法。
Pandas 可以读取各种文件格式,例如 CSV 文件、JSON 文件、XML 文件、Parquet 文件、SQL 文件,详见下表。
| 写入 | 读取 |
CSV 文件 | | |
JSON 文件 | | |
Parquet 文件 | | |
SQL 文件 | | |
XML 文件 | | |
使用 Pandas 进行数据清理
在现实场景中,很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。此外,数据还会有需要 屏蔽mask
Pandas 清洗空值:
a. 空行可以使用 df.dropna(inplace=True) 方法来删除。
b. 空值可以使用 df.fillna(<value>, inplace=True) 方法来替换。还可以指定某一个列来替换该列的空数据。
Pandas 屏蔽数据:
c. 要屏蔽所有不满足条件 my_list.where(my_list < 5) 的敏感数据的值,可以使用 my_list.mask(my_list < 5)。
Pandas 清洗重复数据:
d. 要删除重复数据,可以使用 drop_duplicates() 方法:
使用 Pandas 进行数据分析
下面的表格列出了 Pandas 中进行数据分析的各种函数,以及其语法。(请注意:df 代表一个 数据帧DataFrame
< 如显示不全,请左右滑动 >
语法 | 描述 |
| |
| |
| Loc 函数返回指定行的数据,也可以对数据进行切片 |
| 对指定列的数据进行分组 |
| 计算指定列数据的总和 |
| 计算指定列数据的算术平均值 |
| 计算指定列数据的最小值 |
| 计算指定列数据的最大值 |
| 在指定列上根据数值进行排序,默认升序 |
| 返回元素的个数,即为行数 * 列数 |
| 返回对各列的统计汇总 |
| 创建 |
| 根据 |
Pandas 的优点
- 支持多索引(层次索引),方便分析多维数据。
- 支持数据透视表的创建,堆栈和取消堆栈操作。
- 可以使用 Pandas 处理有限值的分类数据。
- 支持分组和聚合运算。
- 可以禁用排序。
- 支持行级过滤(获取满足过滤条件的行)和列级过滤(只选择需要的列)。
- 有助于重塑数据集(数组的维度变换)。还可以转置数组的值,并转换为列表。当你使用 Python 处理数据时,可以将 Pandas 数据帧转换为多维 NumPy 数组。
- 支持面向标签的数据切片。
Pandas 的不足
Pandas 的代码和语法与 Python 不同,所以人们需要额外再学习 Pandas。此外,相较于 Pandas,像三维数据这样的高维数据会在 NumPy 等其他库有更好的处理。
总结
Pandas 能够大幅提升数据分析的效率。它与其他库的兼容性使它在其他 Python 库中都能有效地使用。