译者 | 李睿
审校 | 孙淑娟
表格数据是网络上最好的数据来源之一。它们可以存储大量有用的信息,同时又不丢失易于阅读的格式,使其成为数据相关项目的金矿。
无论是抓取足球赛事数据还是提取股票市场数据,都可以使用Python从HTML表中快速访问、解析和提取数据,而这需要感谢Requests和Beautiful Soup。
理解HTML表的结构
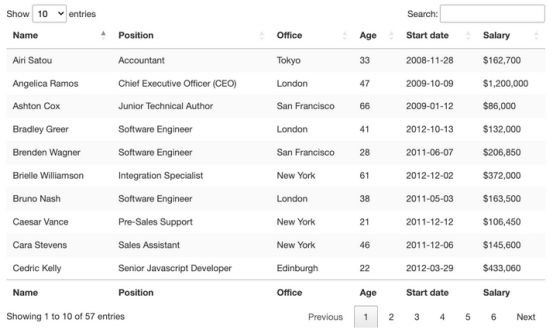
从视觉上看,HTML表是一组以表格格式显示信息的行和列。本文主要介绍如何抓取表格数据:
为了能够抓取该表中包含的数据,需要更深入地研究它的编码。
一般来说,HTML表实际上是使用以下HTML标记构建的:
- <table>:标志着HTML表的开始
- <th> 或 <thead>:定义行作为HTML表的标题
- <tbody>:表示数据所在的部分
- <tr>:表示表中的一行
- <td>:在表中定义单元格
然而,正如人们在实际场景中看到的,并不是所有开发人员在构建表时都遵循这些约定,这使得一些项目比其他项目更难。不过,了解它们的工作原理对于找到正确的方法至关重要。
在浏览器中输入表的URL,并检查页面,看看在底层发生了什么。
这就是这个页面非常适合练习用Python抓取表格数据的原因。有一个明确的<table>标签对打开和关闭表,所有相关数据都在<tbody>标签中。它只显示与前端所选条目数量匹配的10行。
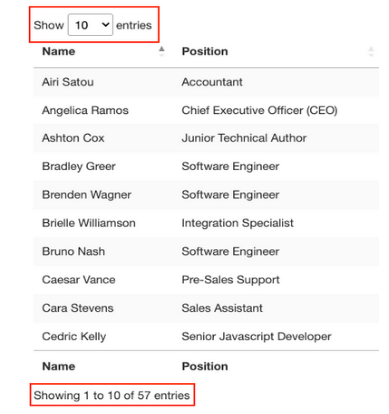
关于这个表还有一些需要了解的事情,即想要抓取的条目共有57个,并且似乎有两种访问数据的解决方案。第一种是点击下拉菜单,选择“100”,显示所有条目:
或者单击“下一步”按钮以浏览分页。

那么哪一种方案会更好?这两种解决方案都会给脚本增加额外的复杂性,因此,先检查从哪里提取数据。
当然,因为这是一个HTML表,因此所有数据都应该在HTML文件本身上,而不需要AJAX注入。要验证这一点,需要右击>查看页面来源。接下来,复制一些单元格并在源代码中搜索它们。
对来自不同分页单元格的多个条目执行了相同的操作,尽管前端没有显示,但似乎所有目标数据都在其中。
有了这些信息,就可以开始编写代码了。
使用Python的Beautiful Soup删除HTML表
因为要获取的所有员工数据都在HTML文件中,所以可以使用Requests库发送HTTP请求,并使用Beautiful Soup解析响应。
注:对于网页抓取的新手,本文作者在Python教程中为初学者创建了一个网络抓取教程。尽管新手没有经验也可以学习,但从基础开始总是一个好主意。
1.发送主请求
在这个项目中创建一个名为python-html-table的新目录,然后创建一个名为bs4-table-scraper的新文件夹,最后创建一个新的python_table_scraper.py文件。
从终端pip3安装请求beautifulsoup4,并将它们导入到项目中,如下所示:
要用requests发送HTTP请求,所需要做的就是设置一个URL并通过request.get()传递它,将返回的HTML存储在响应变量中并输出response.status_code。
注:如果完全不熟悉Python,可以使用命令python3python_table_scraper.py从终端运行代码。
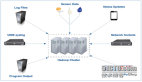
如果它有效,将会返回一个200状态码。任何其他情况都意味着IP正在被网站设置的反抓取系统拒绝。一个潜在的解决方案是在脚本中添加自定义标题,使脚本看起来更加人性化,但这可能还不够。另一个解决方案是使用Web抓取API处理所有这些复杂的问题。
2.使用Beautiful Soup构建解析器
在提取数据之前,需要将原始HTML转换为格式化或解析的数据。将这个解析后的HTML存储到一个soup对象中,如下所示:
从这里开始,可以使用HTML标记及其属性遍历解析树。
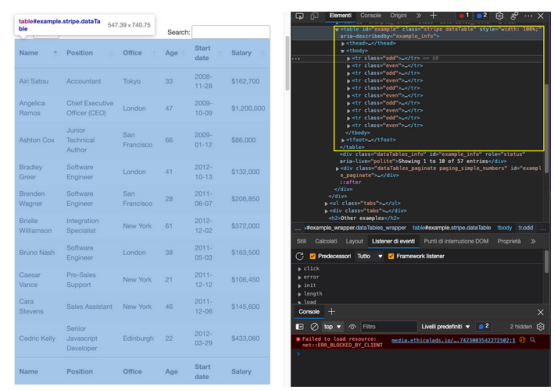
如果返回到页面上的表,已经看到该表用类stripe dataTable封装在<table>标记之间,可以使用它来选择该表。
注:在测试之后,添加第二个类(dataTable)并没有返回元素。实际上,在return元素中,表的类只是stripe。还可以使用id='example'。
以下是它返回的结果:
既然已经获取了表,就可以遍历行并获取所需的数据。
3.遍历HTML表
回想一下HTML表的结构,每一行都由<tr>元素表示,其中有包含数据的<td>元素,所有这些都包装在<tbody>标签对之间。
为了提取数据,将创建两个for looks,一个用于抓取表的<tbody>部分(所有行所在的位置),另一个用于将所有行存储到可以使用的变量中:
在行中,将存储表正文部分中找到的所有<tr>元素。如果遵循这个逻辑,下一步就是将每一行存储到单个对象中,并循环遍历它们以查找所需的数据。
首先,尝试使用.querySelectorAll()方法在浏览器控制台上选择第一个员工的名字。这个方法的一个真正有用的特性是,可以越来越深入地实现大于(>)符号的层次结构,以定义父元素(在左侧)和要获取的子元素(在右侧)。
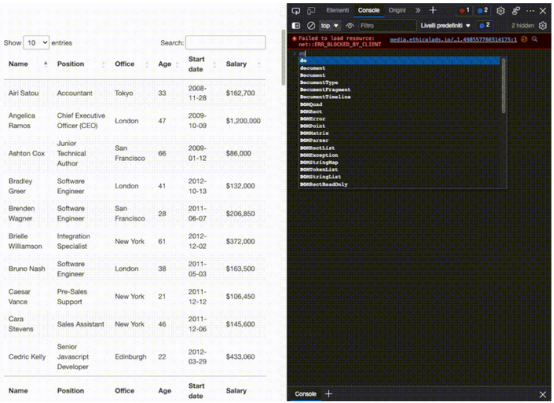
如上所见,一旦抓取所有<td>元素,这些元素就会成为节点列表。因为不能依赖类来获取每个单元格,所以只需要知道它们在索引中的位置,而第一个name是0。
从那里,可以像这样编写代码:
简单地说,逐个获取每一行,并找到其中的所有单元格,一旦有了列表,只获取索引中的第一个单元格(position 0),然后使用.text方法只获取元素的文本,忽略不需要的HTML数据。
这是一个包含所有员工姓名的列表! 对于其余部分,只需要遵循同样的逻辑:
然而,将所有这些数据输出在控制台上并没有太大帮助。与其相反,可以将这些数据存储为一种、更有用的新格式。
4.将表格数据存储到JSON文件中
虽然可以轻松地创建一个CSV文件并将数据发送到那里,但如果可以使用抓取的数据创建一些新内容,那么这将不是最容易管理的格式。
尽管如此,以前做的一个项目解释了如何创建一个CSV文件来存储抓取的数据。
好消息是,Python有自己的JSON模块来处理JSON对象,所以不需要安装任何程序,只需要导入它。
但是,在继续并创建JSON文件之前,需要将所有这些抓取的数据转换为一个列表。为此,将在循环外部创建一个空数组。
然后向它追加数据,每个循环向数组追加一个新对象。
如果print(employee_list),其结果如下:
还是有点混乱,但已经有了一组准备转换为JSON的对象。
注:作为测试,输出employee_list的长度,它返回57,这是抓取的正确行数(行现在是数组中的对象)。
将列表导入到JSON只需要两行代码:
- 首先,打开一个新文件,传入想要的文件名称(json_data)和'w',因为想要写入数据。
- 接下来,使用.dump()函数从数组(employee_list)和indent=2中转储数据,这样每个对象都有自己的行,而不是所有内容都在一个不可读的行中。
5.运行脚本和完整代码
如果一直按照下面的方法做,那么代码库应该是这样的:
注:在这里为场景添加了一些注释。
以下是JSON文件中的前三个对象:
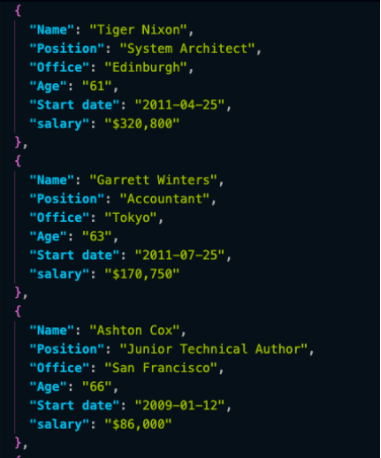
以JSON格式存储抓取数据允将信息用于新的应用程序
使用Pandas抓取HTML表
在离开页面之前,希望探索第二种抓取HTML表的方法。只需几行代码,就可以从HTML文档中抓取所有表格数据,并使用Pandas将其存储到数据框架中。
在项目的目录中创建一个新文件夹(将其命名为panda-html-table-scraper),并创建一个新文件名pandas_table_scraper.py。
打开一个新的终端,导航到刚刚创建的文件夹(cdpanda-html-table-scraper),并从那里安装pandas:
在文件的顶部导入它。
Pandas有一个名为read_html()的函数,它主要抓取目标URL,并返回所有HTML表作为DataFrame对象的列表。
要实现这一点,HTML表至少需要结构化,因为该函数将查找<table>之类的元素来标识文件中的表。
为了使用这个函数,需要创建一个新变量,并将之前使用的URL传递给它:
当输出它时,它将返回页面内的HTML表列表。
如果比较DataFrame中的前三行,它们与采用BeautifulSoup抓取的结果完全匹配。
为了处理JSON,Pandas可以有一个内置的.to_json()函数。它将把DataFrame对象列表转换为JSON字符串。
而所需要做的就是调用DataFrame上的方法,并传入路径、格式(split,data,records,index等),并添加缩进以使其更具可读性:
如果现在运行代码,其结果文件如下:
注意,需要从索引([0])中选择表,因为.read_html()返回一个列表,而不是单个对象。
以下是完整的代码以供参考
有了这些新知识,就可以开始抓取网络上几乎所有的HTML表了。只要记住,如果理解了网站的结构和背后的逻辑,就没有什么是不能抓取的。
也就是说,只要数据在HTML文件中,这些方法就有效。如果遇到动态生成的表,则需要找到一种新的方法。
原文标题:How to Use Python to Loop Through HTML Tables and Scrape Tabular Data,作者:Zoltan Bettenbuk