1、Nacos简介
Nacos是一款阿里巴巴开源用于管理分布式微服务的中间件,能够帮助开发人员快速实现动态服务发现、服务配置、服务元数据及流量管理等。这篇文章主要剖析一下Nacos作为注册中心时其服务注册与发现原理。
2、为什么会需要Nacos
Nacos作为注册中心是为了更好更方便的管理应用中的每一个服务,是各个分布式节点之间的纽带。其作为注册中心主要提供以下核心功能:
- 服务注册与发现:动态的增减服务节点,服务节点增减后动态的通知服务消费者,不需要由消费者来更新配置。
- 服务配置:动态修改服务配置,并将其推送到服务提供者和服务消费者而不需要重启服务。
- 健康检查和服务摘除:主动的检查服务健康情况,对于宕机的服务将其摘除服务列表。
3、分布式架构CAP理论
CAP定理是分布式系统中最基础的原则,所以理解和掌握了CAP对系统架构的设计至关重要。分布式架构下所有系统不可能同时满足以下三点:Consisteny(一致性)、Availability(可用性)、Partition tolerance(分区容错性),CAP指明了任何分布式系统只能同时满足这三项中的两项。

分布式系统肯定都要保证其容错性 ,那么可用性和一致性就只能选一个了。简单来说分布式系统的CAP理论就像你想买个新手机,这个手机不可能功能强大、便宜、又好看的,它最多只能满足两点的,要么功能强大便宜、要么功能强大好看、要么便宜好看,不可能同时满足三点。
4、几种注册中心的区别
注册中心在分布式应用中是经常用到的,也是必不可少的,那注册中心,又分为以下几种:Eureka、Zookeeper、Nacos等。这些注册中心最大的区别就是其基于AP架构还是CP架构,简单介绍一下:
- Zookeeper:用过或者了解过zk做注册中心的同学都知道,Zookeeper集群下一旦leader节点宕机了,在短时间内服务都不可通讯,因为它们在一定时间内follower进行选举来推出新的leader,因为在这段时间内,所有的服务通信将受到影响,而且leader选取时间比较长,需要花费几十秒甚至上百秒的时间,因此:可以理解为 Zookeeper是实现的CP,也就是将失去A(可用性)。
- Eureka:Eureka集群下每个节点之间都会定时发送心跳,定时同步数据,没有master/slave之分,是一个完全去中心化的架构。因此每个注册到Eureka下的实例都会定时同步ip,服务之间的调用也是根据Eureka拿到的缓存服务数据进行调用。若一台Eureka服务宕机,其他Eureka在一定时间内未感知到这台Eureka服务宕机,各个服务之间还是可以正常调用。Eureka的集群中,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。当数据出现不一致时,虽然A, B上的注册信息不完全相同,但每个Eureka节点依然能够正常对外提供服务,这会出现查询服务信息时如果请求A查不到,但请求B就能查到。如此保证了可用性但牺牲了一致性。
- Nacos:同时支持CP和AP架构,根据根据服务注册选择临时和永久来决定走AP模式还是CP模式。如果注册Nacos的client节点注册时ephemeral=true,那么Nacos集群对这个client节点的效果就是AP,采用distro协议实现;而注册Nacos的client节点注册时ephemeral=false,那么Nacos集群对这个节点的效果就是CP的,采用raft协议实现。
本篇文章主要是深入研究一下Nacos基于AP架构微服务注册原理,由于篇幅有限基于CP架构的Nacos微服务注册下次再跟你们分析。
5、Nacos服务注册与发现的原理
1.微服务在启动将自己的服务注册到Nacos注册中心,同时发布http接口供其他系统调用,一般都是基于SpringMVC。
2.服务消费者基于Feign调用服务提供者对外发布的接口,先对调用的本地接口加上注解@FeignClient,Feign会针对加了该注解的接口生成动态代理,服务消费者针对Feign生成的动态代理去调用方法时,会在底层生成Http协议格式的请求,类似 /stock/deduct? productId=100。
3.Feign最终会调用Ribbon从本地的Nacos注册表的缓存里根据服务名取出服务提供在机器的列表,然后进行负载均衡并选择一台机器出来,对选出来的机器IP和端口拼接之前生成的url请求,生成调用的Http接口地址。

6、Nacos核心功能点
服务注册:Nacos Client会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址、端口等信息。Nacos Server接收到注册请求后,就会把这些元数据信息存储在一个双层的内存Map中。
服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认5s发送一次心跳。
服务健康检查:Nacos Server会开启一个定时任务用来检查注册服务实例的健康情况,对于超过15s没有收到客户端心跳的实例会将它 的healthy属性置为false(客户端服务发现时不会发现),如果某个实例超过30秒没有收到心跳,直接剔除该实例(被剔除的实例如果恢复 发送心跳则会重新注册)
服务发现:服务消费者(Nacos Client)在调用服务提供者的服务时,会发送一个REST请求给Nacos Server,获取上面注册的服务清 单,并且缓存在Nacos Client本地,同时会在Nacos Client本地开启一个定时任务定时拉取服务端最新的注册表信息更新到本地缓存
服务同步:Nacos Server集群之间会互相同步服务实例,用来保证服务信息的一致性。
7、Nacos源码分析
看Nacos源码的不难发现,Nacos实际上就是一个基于Spring Boot的web应用,不管是服务注册还是发送心跳都是通过给Nacos服务端发送http请求实现的。下载并编译Nacos源码就不过多赘述了,首先需要搭建一个微服务作为Nacos的客户端。
7.1 Nacos客户端注册
Nacos客户端也是个Spring Boot项目,当客户端服务启动时Spring Boot项目启动时自动加载spring-cloud-starter-alibaba-nacos-discovery包的META-INF/spring.factories中包含自动装配的配置信息,并将文件中的类加载成bean放入Spring容器中,我们可以先看一下spring.factories文件:
org.springframework.boot.autoconfigure.EnableAutoCnotallow=\
com.alibaba.cloud.nacos.discovery.NacosDiscoveryAutoConfiguration,\
com.alibaba.cloud.nacos.endpoint.NacosDiscoveryEndpointAutoConfiguration,\
com.alibaba.cloud.nacos.registry.NacosServiceRegistryAutoConfiguration,\
com.alibaba.cloud.nacos.discovery.NacosDiscoveryClientConfiguration,\
com.alibaba.cloud.nacos.discovery.reactive.NacosReactiveDiscoveryClientConfiguration,\
com.alibaba.cloud.nacos.discovery.configclient.NacosConfigServerAutoConfiguration,\
com.alibaba.cloud.nacos.NacosServiceAutoConfiguration
org.springframework.cloud.bootstrap.BootstrapCnotallow=\
com.alibaba.cloud.nacos.discovery.configclient.NacosDiscoveryClientConfigServiceBootstrapConfiguration
找到Nacos注册中心的自动配置类:NacosServiceRegistryAutoConfiguration。
NacosServiceRegistryAutoConfiguration这个类是Nacos客户端启动时的一个入口类,代码如下:
@Configuration(
proxyBeanMethods = false
)
@EnableConfigurationProperties
@ConditionalOnNacosDiscoveryEnabled
@ConditionalOnProperty(
value = {"spring.cloud.service-registry.auto-registration.enabled"},
matchIfMissing = true
)
@AutoConfigureAfter({AutoServiceRegistrationConfiguration.class,
AutoServiceRegistrationAutoConfiguration.class,
NacosDiscoveryAutoConfiguration.class})
public class NacosServiceRegistryAutoConfiguration {
public NacosServiceRegistryAutoConfiguration() {
}
@Bean
public NacosServiceRegistry nacosServiceRegistry(NacosDiscoveryProperties nacosDiscoveryProperties) {
return new NacosServiceRegistry(nacosDiscoveryProperties);
}
@Bean
@ConditionalOnBean({AutoServiceRegistrationProperties.class})
public NacosRegistration nacosRegistration(ObjectProvider<List<NacosRegistrationCustomizer>> registrationCustomizers, NacosDiscoveryProperties nacosDiscoveryProperties, ApplicationContext context) {
return new NacosRegistration((List)registrationCustomizers.getIfAvailable(), nacosDiscoveryProperties, context);
}
@Bean
@ConditionalOnBean({AutoServiceRegistrationProperties.class})
public NacosAutoServiceRegistration nacosAutoServiceRegistration(NacosServiceRegistry registry, AutoServiceRegistrationProperties autoServiceRegistrationProperties, NacosRegistration registration) {
return new NacosAutoServiceRegistration(registry, autoServiceRegistrationProperties, registration);
}
}
看NacosServiceRegistryAutoConfiguration配置类有3个@Bean注解。
- nacosServiceRegistry()方法: 定义了NacosServiceRegistry的bean,并且为其属性nacosDiscoveryProperties赋值,即将从配置文件中读取到的配置信息赋值进去待用;
- nacosRegistration()方法主要就是定义了NacosRegistration的bean,后面会用到这个bean;
- nacosAutoServiceRegistration:该方法比较核心它的参数中有2个就是前面定义的两个bean,其实就是为了这个方法服务的,由NacosAutoServiceRegistration类的构造器传入NacosAutoServiceRegistration类中:NacosAutoServiceRegistration(registry, autoServiceRegistrationProperties, registration),后面的流程都是以这句代码作为入口。

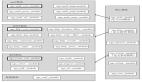
利用IDEA查看类结构,如上图所示,NacosAutoServiceRegistration继承AbstractAutoServiceRegistration类,而AbstractAutoServiceRegistration类又实现了AutoServiceRegistration和ApplicationListener接口。
ApplicationListener接口是Spring提供的事件监听接口,Spring会在所有bean都初始化完成之后发布一个事件,ApplicationListener会监听所发布的事件,这里的事件是Spring Boot自定义的WebServerInitializedEvent事件,主要是项目启动时就会发布WebServerInitializedEvent事件,然后被AbstractAutoServiceRegistration监听到,从而就会执行onApplicationEvent方法,在这个方法里就会进行服务注册。
这里AbstractAutoServiceRegistration类实现了Spring监听器接口ApplicationListener,并重写了该接口的onApplicationEvent方法。
public void onApplicationEvent(WebServerInitializedEvent event) {
this.bind(event);
}继续点下去看bind方法。
public void bind(WebServerInitializedEvent event) {
ApplicationContext context = event.getApplicationContext();
if (!(context instanceof ConfigurableWebServerApplicationContext) || !"management".equals(((ConfigurableWebServerApplicationContext)context).getServerNamespace())) {
this.port.compareAndSet(0, event.getWebServer().getPort());
//start方法
this.start();
}
}看到这里发现了bind方法里有个非常重要的start()方法,继续看该方法的register()就是真正的客户端注册方法。
public void start() {
if (!this.isEnabled()) {
if (logger.isDebugEnabled()) {
logger.debug("Discovery Lifecycle disabled. Not starting");
}
} else {
if (!this.running.get()) {
this.context.publishEvent(new InstancePreRegisteredEvent(this, this.getRegistration()));
//真正的客户端注册方法
this.register();
if (this.shouldRegisterManagement()) {
this.registerManagement();
}
this.context.publishEvent(new InstanceRegisteredEvent(this, this.getConfiguration()));
this.running.compareAndSet(false, true);
}
}
}跳过一些中间非关键性的代码,可以直接看该注册方法。
protected void register() {
this.serviceRegistry.register(getRegistration());
}这里的serviceRegistry就是NacosServiceRegistryAutoConfiguration类中第一个@Bean定义的bean,第一个@Bean就是这里的serviceRegistry对象的实现;其中getRegistration()获取的就是第二个@Bean定义的NacosRegistration的实例,这两个bean实例都是通过第3个@Bean传进来的,所以这里就可以把NacosServiceRegistryAutoConfiguration类中那3个@Bean给串起来了。
protected void register() {
this.serviceRegistry.register(getRegistration());
}不得不说,阿里巴巴开发的中间件,其底层源码的命名还是很规范的,register()方法从命名上来看就可以知道这是注册的方法,事实也确实是注册的方法,这个方法中会通过nacos-client包来调用nacos-server的服务注册接口来实现服务的注册功能。下面我看一下调用Nacos注册接口方法:
public void register(Registration registration) {
if (StringUtils.isEmpty(registration.getServiceId())) {
log.warn("No service to register for nacos client...");
} else {
NamingService namingService = this.namingService();
String serviceId = registration.getServiceId();
String group = this.nacosDiscoveryProperties.getGroup();
//构建客户端参数ip,端口号等
Instance instance = this.getNacosInstanceFromRegistration(registration);
try {
//调用注册方法
namingService.registerInstance(serviceId, group, instance);
log.info("nacos registry, {} {} {}:{} register finished", new Object[]{group, serviceId, instance.getIp(), instance.getPort()});
} catch (Exception var7) {
log.error("nacos registry, {} register failed...{},", new Object[]{serviceId, registration.toString(), var7});
ReflectionUtils.rethrowRuntimeException(var7);
}
}
}
//构建客户端注册参数
private Instance getNacosInstanceFromRegistration(Registration registration) {
Instance instance = new Instance();
instance.setIp(registration.getHost());
instance.setPort(registration.getPort());
instance.setWeight((double)this.nacosDiscoveryProperties.getWeight());
instance.setClusterName(this.nacosDiscoveryProperties.getClusterName());
instance.setEnabled(this.nacosDiscoveryProperties.isInstanceEnabled());
instance.setMetadata(registration.getMetadata());
instance.setEphemeral(this.nacosDiscoveryProperties.isEphemeral());
return instance;
}根据源码可以知道beatReactor.addBeatInfo()方法作用在于创建心跳信息实现健康检测,Nacos 服务端必须要确保注册的服务实例是健康的,而心跳检测就是服务健康检测的手段。而serverProxy.registerService()实现服务注册,综上可以分析出Nacos客户端注册流程:

到此为止还没有真正的实现服务的注册,但是至少已经知道了Nacos客户端的自动注册原理是借助了Spring Boot的自动配置功能,在项目启动时通过自动配置类。NacosServiceRegistryAutoConfiguration将NacosServiceRegistry注入进来,通过Spring的事件监听机制,调用该类的注册方法register(registration)实现服务的自动注册。
7.2 Nacos服务发现
7.2.1 Nacos客户端客户端服务发现
当Nacos服务端启动后,会先从本地缓存的serviceInfoMap中获取服务实例信息,获取不到则通过NamingProxy调用Nacos服务端获取服务实例信息,最后开启定时任务每秒请求服务端获取实例信息列表进而更新本地缓存serviceInfoMap,服务发现拉取实例信息流程图如下:

废话不多说,直接上服务发现源码:
/**
* 客户端服务发现
*
* @param serviceName name of service
* @param groupName group of service
* @param clusters list of cluster
* @param subscribe if subscribe the service
* @return
* @throws NacosException
*/
@Override
public List<Instance> getAllInstances(String serviceName, String groupName, List<String> clusters,
boolean subscribe) throws NacosException {
ServiceInfo serviceInfo;
if (subscribe) {
// 如果本地缓存不存在服务信息,则进行订阅
serviceInfo = hostReactor.getServiceInfo(NamingUtils.getGroupedName(serviceName, groupName),
StringUtils.join(clusters, ","));
} else {
// 如果非订阅模式就直接拉取服务端的注册表
serviceInfo = hostReactor
.getServiceInfoDirectlyFromServer(NamingUtils.getGroupedName(serviceName, groupName),
StringUtils.join(clusters, ","));
}
List<Instance> list;
if (serviceInfo == null || CollectionUtils.isEmpty(list = serviceInfo.getHosts())) {
return new ArrayList<Instance>();
}
return list;
}
/**
* 客户端从注册中心拉取注册列表
*
* @param serviceName
* @param clusters
* @return
*/
public ServiceInfo getServiceInfo(final String serviceName, final String clusters) {
NAMING_LOGGER.debug("failover-mode: " + failoverReactor.isFailoverSwitch());
String key = ServiceInfo.getKey(serviceName, clusters);
if (failoverReactor.isFailoverSwitch()) {
return failoverReactor.getService(key);
}
//客户端从本地缓存中拉群注册表信息,第一次根据服务名从注册表map中获取,服务表信息肯定是为null
ServiceInfo serviceObj = getServiceInfo0(serviceName, clusters);
//如果拿到缓存map中的服务列表为null,如果是第一次根据服务名拉取注册表信息,肯定为null
if (null == serviceObj) {
serviceObj = new ServiceInfo(serviceName, clusters);
serviceInfoMap.put(serviceObj.getKey(), serviceObj);
updatingMap.put(serviceName, new Object());
//第一次拉取注册表信息为null后,然后调用Nacos服务端接口更新本地注册表
updateServiceNow(serviceName, clusters);
updatingMap.remove(serviceName);
} else if (updatingMap.containsKey(serviceName)) {
if (UPDATE_HOLD_INTERVAL > 0) {
// hold a moment waiting for update finish
synchronized (serviceObj) {
try {
serviceObj.wait(UPDATE_HOLD_INTERVAL);
} catch (InterruptedException e) {
NAMING_LOGGER
.error("[getServiceInfo] serviceName:" + serviceName + ", clusters:" + clusters, e);
}
}
}
}
/**
* 定时任务拉取,每隔几秒钟就去拉取一次,去拉取nacos注册表,更新客户端本地注册列表的map
*
* 为啥这里要定时任务拉取呢?因为上面到注册表map是缓存在客户端本地的,假如有新的服务注册到nacos
* 时,这时就要更新客户端注册表信息,所以这里会执行一个订单拉取的任务
*/
scheduleUpdateIfAbsent(serviceName, clusters);
return serviceInfoMap.get(serviceObj.getKey());
}
//异步拉取任务
public void scheduleUpdateIfAbsent(String serviceName, String clusters) {
if (futureMap.get(ServiceInfo.getKey(serviceName, clusters)) != null) {
return;
}
synchronized (futureMap) {
if (futureMap.get(ServiceInfo.getKey(serviceName, clusters)) != null) {
return;
}
//执行一个定时拉取任务
ScheduledFuture<?> future = addTask(new UpdateTask(serviceName, clusters));
futureMap.put(ServiceInfo.getKey(serviceName, clusters), future);
}
}
//定时拉取注册表任务
public class UpdateTask implements Runnable {
long lastRefTime = Long.MAX_VALUE;
private final String clusters;
private final String serviceName;
/**
* the fail situation. 1:can't connect to server 2:serviceInfo's hosts is empty
*/
private int failCount = 0;
public UpdateTask(String serviceName, String clusters) {
this.serviceName = serviceName;
this.clusters = clusters;
}
private void incFailCount() {
int limit = 6;
if (failCount == limit) {
return;
}
failCount++;
}
private void resetFailCount() {
failCount = 0;
}
@Override
public void run() {
long delayTime = DEFAULT_DELAY;
try {
ServiceInfo serviceObj = serviceInfoMap.get(ServiceInfo.getKey(serviceName, clusters));
if (serviceObj == null) {
//又在继续调用拉取nacos注册列表方法
updateService(serviceName, clusters);
return;
}
if (serviceObj.getLastRefTime() <= lastRefTime) {
//又在继续调用拉取nacos注册列表方法
updateService(serviceName, clusters);
serviceObj = serviceInfoMap.get(ServiceInfo.getKey(serviceName, clusters));
} else {
// if serviceName already updated by push, we should not override it
// since the push data may be different from pull through force push
refreshOnly(serviceName, clusters);
}
lastRefTime = serviceObj.getLastRefTime();
if (!notifier.isSubscribed(serviceName, clusters) && !futureMap
.containsKey(ServiceInfo.getKey(serviceName, clusters))) {
// abort the update task
NAMING_LOGGER.info("update task is stopped, service:" + serviceName + ", clusters:" + clusters);
return;
}
if (CollectionUtils.isEmpty(serviceObj.getHosts())) {
incFailCount();
return;
}
delayTime = serviceObj.getCacheMillis();
resetFailCount();
} catch (Throwable e) {
incFailCount();
NAMING_LOGGER.warn("[NA] failed to update serviceName: " + serviceName, e);
} finally {
//最后继续嵌套调用当前这个任务,实现定时拉取
executor.schedule(this, Math.min(delayTime << failCount, DEFAULT_DELAY * 60), TimeUnit.MILLISECONDS);
}
}
这里值得注意的是,Nacos客户端拉取注册列表方法的最后又是一个定时任务任务,每隔10秒钟就会拉取一次服务端Nacos的注册表。为啥这里要定时任务拉取呢?因为上面到注册表map是缓存在客户端本地的,假如有新的服务注册到Nacos时,这时就要更新客户端注册表信息,所以这里会执行一个拉取的任务。
private void updateServiceNow(String serviceName, String clusters) {
try {
//拉群nacos列表,更新到本地缓存map中的注册列表
updateService(serviceName, clusters);
} catch (NacosException e) {
NAMING_LOGGER.error("[NA] failed to update serviceName: " + serviceName, e);
}
}
/**
* Update service now.
* 拉取注册列表
*
* @param serviceName service name
* @param clusters clusters
*/
public void updateService(String serviceName, String clusters) throws NacosException {
ServiceInfo oldService = getServiceInfo0(serviceName, clusters);
try {
//调用拉群列表接口
String result = serverProxy.queryList(serviceName, clusters, pushReceiver.getUdpPort(), false);
if (StringUtils.isNotEmpty(result)) {
//解析返回值服务表json
processServiceJson(result);
}
} finally {
if (oldService != null) {
synchronized (oldService) {
oldService.notifyAll();
}
}
}
/**
* Nacos客户端查询服务端注册表数
*
* @param serviceName service name
* @param clusters clusters
* @param udpPort udp port
* @param healthyOnly healthy only
* @return instance list
* @throws NacosException nacos exception
*/
public String queryList(String serviceName, String clusters, int udpPort, boolean healthyOnly)
throws NacosException {
final Map<String, String> params = new HashMap<String, String>(8);
params.put(CommonParams.NAMESPACE_ID, namespaceId);
params.put(CommonParams.SERVICE_NAME, serviceName);
params.put("clusters", clusters);
params.put("udpPort", String.valueOf(udpPort));
params.put("clientIP", NetUtils.localIP());
params.put("healthyOnly", String.valueOf(healthyOnly));
//调用拉取注册列表接口
return reqApi(UtilAndComs.nacosUrlBase + "/instance/list", params, HttpMethod.GET);
}7.2.2 服务端服务发现查询注册表api
上面分析了当客户端在其本地缓存中没有找到注册表信息,就会调用Nacos服务端api拉取注册表信息,不难发现服务端查询注册表api为"/instance/list"。
/**
* Get all instance of input service.
* 客户端获取nacos所有注册实例方法
*
* @param request http request
* @return list of instance
* @throws Exception any error during list
*/
@GetMapping("/list")
@Secured(parser = NamingResourceParser.class, action = ActionTypes.READ)
public ObjectNode list(HttpServletRequest request) throws Exception {
String namespaceId = WebUtils.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
NamingUtils.checkServiceNameFormat(serviceName);
String agent = WebUtils.getUserAgent(request);
String clusters = WebUtils.optional(request, "clusters", StringUtils.EMPTY);
String clientIP = WebUtils.optional(request, "clientIP", StringUtils.EMPTY);
int udpPort = Integer.parseInt(WebUtils.optional(request, "udpPort", "0"));
String env = WebUtils.optional(request, "env", StringUtils.EMPTY);
boolean isCheck = Boolean.parseBoolean(WebUtils.optional(request, "isCheck", "false"));
String app = WebUtils.optional(request, "app", StringUtils.EMPTY);
String tenant = WebUtils.optional(request, "tid", StringUtils.EMPTY);
boolean healthyOnly = Boolean.parseBoolean(WebUtils.optional(request, "healthyOnly", "false"));
return doSrvIpxt(namespaceId, serviceName, agent, clusters, clientIP, udpPort, env, isCheck, app, tenant,
healthyOnly);
}
这里通过doSrvIpxt()方法获取服务列表,根据namespaceId、serviceName获取service实例,service实例中srvIPs获取所有服务提供者的实例信息,遍历组装成json字符串并返回。
public ObjectNode doSrvIpxt(String namespaceId, String serviceName, String agent, String clusters, String clientIP,
int udpPort, String env, boolean isCheck, String app, String tid, boolean healthyOnly) throws Exception {
ClientInfo clientInfo = new ClientInfo(agent);
ObjectNode result = JacksonUtils.createEmptyJsonNode();
Service service = serviceManager.getService(namespaceId, serviceName);
long cacheMillis = switchDomain.getDefaultCacheMillis();
// now try to enable the push
try {
if (udpPort > 0 && pushService.canEnablePush(agent)) {
pushService
.addClient(namespaceId, serviceName, clusters, agent, new InetSocketAddress(clientIP, udpPort),
pushDataSource, tid, app);
cacheMillis = switchDomain.getPushCacheMillis(serviceName);
}
} catch (Exception e) {
Loggers.SRV_LOG
.error("[NACOS-API] failed to added push client {}, {}:{}", clientInfo, clientIP, udpPort, e);
cacheMillis = switchDomain.getDefaultCacheMillis();
}
if (service == null) {
if (Loggers.SRV_LOG.isDebugEnabled()) {
Loggers.SRV_LOG.debug("no instance to serve for service: {}", serviceName);
}
result.put("name", serviceName);
result.put("clusters", clusters);
result.put("cacheMillis", cacheMillis);
result.replace("hosts", JacksonUtils.createEmptyArrayNode());
return result;
}
checkIfDisabled(service);
List<Instance> srvedIPs;
//获取所有实例
srvedIPs = service.srvIPs(Arrays.asList(StringUtils.split(clusters, ",")));
// filter ips using selector:
if (service.getSelector() != null && StringUtils.isNotBlank(clientIP)) {
srvedIPs = service.getSelector().select(clientIP, srvedIPs);
}
if (CollectionUtils.isEmpty(srvedIPs)) {
if (Loggers.SRV_LOG.isDebugEnabled()) {
Loggers.SRV_LOG.debug("no instance to serve for service: {}", serviceName);
}
if (clientInfo.type == ClientInfo.ClientType.JAVA
&& clientInfo.version.compareTo(VersionUtil.parseVersion("1.0.0")) >= 0) {
result.put("dom", serviceName);
} else {
result.put("dom", NamingUtils.getServiceName(serviceName));
}
result.put("name", serviceName);
result.put("cacheMillis", cacheMillis);
result.put("lastRefTime", System.currentTimeMillis());
result.put("checksum", service.getChecksum());
result.put("useSpecifiedURL", false);
result.put("clusters", clusters);
result.put("env", env);
result.set("hosts", JacksonUtils.createEmptyArrayNode());
result.set("metadata", JacksonUtils.transferToJsonNode(service.getMetadata()));
return result;
}
Map<Boolean, List<Instance>> ipMap = new HashMap<>(2);
ipMap.put(Boolean.TRUE, new ArrayList<>());
ipMap.put(Boolean.FALSE, new ArrayList<>());
for (Instance ip : srvedIPs) {
ipMap.get(ip.isHealthy()).add(ip);
}
if (isCheck) {
result.put("reachProtectThreshold", false);
}
double threshold = service.getProtectThreshold();
if ((float) ipMap.get(Boolean.TRUE).size() / srvedIPs.size() <= threshold) {
Loggers.SRV_LOG.warn("protect threshold reached, return all ips, service: {}", serviceName);
if (isCheck) {
result.put("reachProtectThreshold", true);
}
ipMap.get(Boolean.TRUE).addAll(ipMap.get(Boolean.FALSE));
ipMap.get(Boolean.FALSE).clear();
}
if (isCheck) {
result.put("protectThreshold", service.getProtectThreshold());
result.put("reachLocalSiteCallThreshold", false);
return JacksonUtils.createEmptyJsonNode();
}
ArrayNode hosts = JacksonUtils.createEmptyArrayNode();
for (Map.Entry<Boolean, List<Instance>> entry : ipMap.entrySet()) {
List<Instance> ips = entry.getValue();
if (healthyOnly && !entry.getKey()) {
continue;
}
for (Instance instance : ips) {
// remove disabled instance:
if (!instance.isEnabled()) {
continue;
}
ObjectNode ipObj = JacksonUtils.createEmptyJsonNode();
ipObj.put("ip", instance.getIp());
ipObj.put("port", instance.getPort());
// deprecated since nacos 1.0.0:
ipObj.put("valid", entry.getKey());
ipObj.put("healthy", entry.getKey());
ipObj.put("marked", instance.isMarked());
ipObj.put("instanceId", instance.getInstanceId());
ipObj.set("metadata", JacksonUtils.transferToJsonNode(instance.getMetadata()));
ipObj.put("enabled", instance.isEnabled());
ipObj.put("weight", instance.getWeight());
ipObj.put("clusterName", instance.getClusterName());
if (clientInfo.type == ClientInfo.ClientType.JAVA
&& clientInfo.version.compareTo(VersionUtil.parseVersion("1.0.0")) >= 0) {
ipObj.put("serviceName", instance.getServiceName());
} else {
ipObj.put("serviceName", NamingUtils.getServiceName(instance.getServiceName()));
}
ipObj.put("ephemeral", instance.isEphemeral());
hosts.add(ipObj);
}
}
result.replace("hosts", hosts);
if (clientInfo.type == ClientInfo.ClientType.JAVA
&& clientInfo.version.compareTo(VersionUtil.parseVersion("1.0.0")) >= 0) {
result.put("dom", serviceName);
} else {
result.put("dom", NamingUtils.getServiceName(serviceName));
}
result.put("name", serviceName);
result.put("cacheMillis", cacheMillis);
result.put("lastRefTime", System.currentTimeMillis());
result.put("checksum", service.getChecksum());
result.put("useSpecifiedURL", false);
result.put("clusters", clusters);
result.put("env", env);
result.replace("metadata", JacksonUtils.transferToJsonNode(service.getMetadata()));
return result;
}
最后看一下获取服务端实例方法,最后就是将临时实例或者持久实例放在一个集合中返回给客户端。
public List<Instance> srvIPs(List<String> clusters) {
if (CollectionUtils.isEmpty(clusters)) {
clusters = new ArrayList<>();
clusters.addAll(clusterMap.keySet());
}
return allIPs(clusters);
}
public List<Instance> allIPs(List<String> clusters) {
List<Instance> result = new ArrayList<>();
for (String cluster : clusters) {
Cluster clusterObj = clusterMap.get(cluster);
if (clusterObj == null) {
continue;
}
result.addAll(clusterObj.allIPs());
}
return result;
}
public List<Instance> allIPs() {
List<Instance> allInstances = new ArrayList<>();
//将nacos内存中注册表信息返回
allInstances.addAll(persistentInstances);
allInstances.addAll(ephemeralInstances);
return allInstances;
}总结一下Nacos客户端服务发现的核心流程:
如果没有开启订阅模式,则直接通过调用/instance/list接口获取服务实例列表信息;
如果开启订阅模式,则先会从本地缓存中获取实例信息,如果不存在,则进行订阅获并获取实例信息;在获得最新的实例信息之后,也会执行processServiceJson(result)方法来更新内存和本地实例缓存,并发布变更时间。
开启订阅时,会开启定时任务,定时执行UpdateTask获取服务器实例信息、更新本地缓存、发布事件等;
7.3 Nacos服务端注册
服务端的注册源码逻辑相对客户端的还是要复杂很多,所以这里我们先看一下Nacos服务端注册的完整流程图,避免一上来就看源码被绕晕。

接下来我们就着重分析一下AP架构Nacos服务注册的源码。
7.3.1 Nacos服务端注册
Nacos服务端注册当然是本文的核心,那么首先我们来看一下Nacos服务端注册源码。从Nacos的客户端注册原理不难发现,客户端通过调用Nacos服务端提供的http接口实现注册,对外提供的服务接口请求地址为nacos/v1/ns/instance,实现代码咋nacos-naming模块下的InstanceController类中:
@CanDistro
@PostMapping
@Secured(parser = NamingResourceParser.class, action = ActionTypes.WRITE)
public String register(HttpServletRequest request) throws Exception {
//从请求参数汇总获得namespaceId(命名空间Id)
final String namespaceId = WebUtils
.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
//从请求参数汇总获得serviceName(服务名)
final String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
NamingUtils.checkServiceNameFormat(serviceName);
final Instance instance = parseInstance(request);
//registerInstance注册实例
serviceManager.registerInstance(namespaceId, serviceName, instance);
return "ok";
}
客户端就是通过调用该api实现Nacos的注册的,下面可以看一下Nacos的这个注册api是怎么实现的。
public void registerInstance(String namespaceId, String serviceName, Instance instance) throws NacosException {
createEmptyService(namespaceId, serviceName, instance.isEphemeral());
//前面构建过了,这里调取肯定部不为null,从serviceMap中根据namespaceId和serviceName得到一个服务对象
Service service = getService(namespaceId, serviceName);
if (service == null) {
throw new NacosException(NacosException.INVALID_PARAM,
"service not found, namespace: " + namespaceId + ", service: " + serviceName);
}
//调用addInstance添加服务实例
//总体流程:把需要注册的实例放到内存阻塞队列中,另外会起另一个线程从内存中取出intance实例放到Service中,即注册成功了
addInstance(namespaceId, serviceName, instance.isEphemeral(), instance);
}registerInstance()干了两件事儿,第一就是createEmptyService()方法从请求参数汇总获得serviceName(服务名)和namespaceId(命名空间Id),第二就是调用registerInstance注册实例。先看一下createEmptyService方法。
7.3.2 服务端构建注册表
Nacos的注册表是多级存储结构,最外层是通过namespace来实现环境隔离,然后是group分组,分组下就是服务,一个服务有可以分为不同的集群,集群中包含多个实例。因此其注册表结构为一个Map,类型是:Map<String, Map<String, Service>>外层key是namespace_id,内层key是group + serviceName,Service内部维护一个Map,结构是:Map<String, Cluster>的key是clusterName,其值是集群信息;Cluster内部维护一个Set集合Set<Instance> ephemeralInstances和Set<Instance> persistentInstances,元素是Instance类型,代表集群中的多个实例。
createEmptyService()方法就是服务端构建注册表的方法,基于AP架构的Nacos实际就是将注册实例信息保存在内存中。
/**
* 1、创建一个Serivice对象,内部包含了一个clusterMap。
* 2、将service对象放入到SeriviceMap中,结构为:Map<namespaceId, Map<groupName::serviceName, Service>>。
* 3、开启一个定时任务用来检测实例的心跳是否超时,每5秒执行一次。
*
* @param namespaceId
* @param serviceName
* @param local
* @throws NacosException
*/
public void createEmptyService(String namespaceId, String serviceName, boolean local) throws NacosException {
createServiceIfAbsent(namespaceId, serviceName, local, null);
}
public void createServiceIfAbsent(String namespaceId, String serviceName, boolean local, Cluster cluster)
throws NacosException {
Service service = getService(namespaceId, serviceName);
//第一次注册进来,从注册表里获取命名空间,肯定是为null,所以需要构建一个命名空间,
//设置nameSpace等信息,如果Service实例为空,则创建并保存到缓存中
if (service == null) {
Loggers.SRV_LOG.info("creating empty service {}:{}", namespaceId, serviceName);
service = new Service();
service.setName(serviceName);
service.setNamespaceId(namespaceId);
service.setGroupName(NamingUtils.getGroupName(serviceName));
// now validate the service. if failed, exception will be thrown
service.setLastModifiedMillis(System.currentTimeMillis());
service.recalculateChecksum();
if (cluster != null) {
cluster.setService(service);
service.getClusterMap().put(cluster.getName(), cluster);
}
service.validate();
//注册和初始化,通过putService()方法将服务缓存到内存
putServiceAndInit(service);
if (!local) {
addOrReplaceService(service);
}
}
}
createEmptyService()方法主要作用如下:
- 创建一个Serivice对象,内部包含了一个clusterMap;
- 将service对象放入到SeriviceMap中,结构为:Map<namespaceId, Map<groupName::serviceName, Service>>;
- 开启一个定时任务用来检测实例的心跳是否超时,每5秒执行一次。
createServiceIfAbsent()方法主要作用在于第一次注册进来,从注册表里获取命名空间,肯定是为null,所以需要构建一个命名空间,设置nameSpace等信息并保存到缓存中。这个方法里值得注意的是putServiceAndInit()方法,可以点进来看一下这个方法:
private void putServiceAndInit(Service service) throws NacosException {
//构建注册表双层map,初始化serviceMap --> Map<String, Map<String, Service>> serviceMap
putService(service);
//初始化service,开启心跳检测的线程
service.init();
//实现数据一致性监听
consistencyService
.listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), true), service);
consistencyService
.listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), false), service);
Loggers.SRV_LOG.info("[NEW-SERVICE] {}", service.toJson());
}这里我着重putService(service)方法,这里实际是将注册的实例缓存到内存的注册表中
/**
* 通过putService()方法将服务缓存到内存
*
* @param service service
*/
public void putService(Service service) {
if (!serviceMap.containsKey(service.getNamespaceId())) {
//双检索防止并发,为了防止同一个服务多个地方同时注册
synchronized (putServiceLock) {
if (!serviceMap.containsKey(service.getNamespaceId())) {
//构建NamespaceId,Serivce对象放到了ServiceMap里面了,也就是说下次我们再调用getService(namespaceId)的时候就可以获取到一个Service对象了
serviceMap.put(service.getNamespaceId(), new ConcurrentSkipListMap<>());
}
}
}
//构建 service name
serviceMap.get(service.getNamespaceId()).put(service.getName(), service);
}
7.3.3 Nacos服务端心跳机制
接下来我们看一下 putServiceAndInit(Service service)方法中的,init()初始化方法是怎么保持心跳连接的。
/**
* service.init()建立心跳机制
*/
public void init() {
//客户端心跳检查任务,每隔5s执行一次,clientBeatCheckTask是一个线程的方法
HealthCheckReactor.scheduleCheck(clientBeatCheckTask);
for (Map.Entry<String, Cluster> entry : clusterMap.entrySet()) {
entry.getValue().setService(this);
entry.getValue().init();
}
}
/**
* Schedule client beat check task with a delay.
*
* @param task client beat check task
*/
public static void scheduleCheck(ClientBeatCheckTask task) {
//客户端的心跳任务,这里并没有嵌套调用,而是开启延迟5s的任务,然后每隔5秒钟执行一次
futureMap.putIfAbsent(task.taskKey(), GlobalExecutor.scheduleNamingHealth(task, 5000, 5000, TimeUnit.MILLISECONDS));
}
public class ClientBeatCheckTask implements Runnable {
private Service service;
public ClientBeatCheckTask(Service service) {
this.service = service;
}
@JsonIgnore
public PushService getPushService() {
return ApplicationUtils.getBean(PushService.class);
}
@JsonIgnore
public DistroMapper getDistroMapper() {
return ApplicationUtils.getBean(DistroMapper.class);
}
public GlobalConfig getGlobalConfig() {
return ApplicationUtils.getBean(GlobalConfig.class);
}
public SwitchDomain getSwitchDomain() {
return ApplicationUtils.getBean(SwitchDomain.class);
}
public String taskKey() {
return KeyBuilder.buildServiceMetaKey(service.getNamespaceId(), service.getName());
}
@Override
public void run() {
try {
/**
* nacos心跳在集群架构下只允许在一台机器上执行健康检查任务
*
* 集群中有多台机器,本方法在于对服务名称做hash运算再对机器数量取模后,那么
* 这里每次只有定位到一台机器,其他机器都直接return了
*
* 疑问:如果一台机器挂了会怎么办?这里取模会不会乱掉?那这里会不会要做一致性hash?
* 在nacos集群中每台机器之间也是存在状态同步的,每台机器之间都有集群节点同步任务,详见com.alibaba.nacos.naming.cluster.ServerListManager.ServerStatusReporter
*
*/
if (!getDistroMapper().responsible(service.getName())) {
return;
}
if (!getSwitchDomain().isHealthCheckEnabled()) {
return;
}
//获取服务端所有实例
List<Instance> instances = service.allIPs(true);
// first set health status of instances:
/**
* for循环对每个实例都做健康检查
* 在这个方法里面主要是循环当前service的每一个临时实例 用当前时间减去最后一次心跳时间 是否大于心跳超时时间来判断心跳是否超时,
* 如果大于这个时间会执行instance.setHealthy(false)将实例的健康状态改为false;但是这个定时任务不会立即执行,会每5秒执行一次:
*/
for (Instance instance : instances) {
//判断心跳是否超时:当前时间 - 实例上次心跳时间 > 心跳的超时时间【默认是15秒】?
if (System.currentTimeMillis() - instance.getLastBeat() > instance.getInstanceHeartBeatTimeOut()) {
if (!instance.isMarked()) {
if (instance.isHealthy()) {
//如果大于心跳默认时间,把实例的 healthy 设置为false【服务列表一开始不会删掉,一开始会变成false】
instance.setHealthy(false);
Loggers.EVT_LOG
.info("{POS} {IP-DISABLED} valid: {}:{}@{}@{}, region: {}, msg: client timeout after {}, last beat: {}",
instance.getIp(), instance.getPort(), instance.getClusterName(),
service.getName(), UtilsAndCommons.LOCALHOST_SITE,
instance.getInstanceHeartBeatTimeOut(), instance.getLastBeat());
getPushService().serviceChanged(service);
ApplicationUtils.publishEvent(new InstanceHeartbeatTimeoutEvent(this, instance));
}
}
}
}
if (!getGlobalConfig().isExpireInstance()) {
return;
}
// then remove obsolete instances:
for (Instance instance : instances) {
if (instance.isMarked()) {
continue;
}
//当前时间 - 实例上一次心跳时间 > 实例的删除时间【默认30s】
if (System.currentTimeMillis() - instance.getLastBeat() > instance.getIpDeleteTimeout()) {
// delete instance
Loggers.SRV_LOG.info("[AUTO-DELETE-IP] service: {}, ip: {}", service.getName(),
JacksonUtils.toJson(instance));
//直接删除实例
deleteIp(instance);
}
}
} catch (Exception e) {
Loggers.SRV_LOG.warn("Exception while processing client beat time out.", e);
}
}
private void deleteIp(Instance instance) {
try {
NamingProxy.Request request = NamingProxy.Request.newRequest();
request.appendParam("ip", instance.getIp()).appendParam("port", String.valueOf(instance.getPort()))
.appendParam("ephemeral", "true").appendParam("clusterName", instance.getClusterName())
.appendParam("serviceName", service.getName()).appendParam("namespaceId", service.getNamespaceId());
//调用本地服务
String url = "http://" + IPUtil.localHostIP() + IPUtil.IP_PORT_SPLITER + EnvUtil.getPort() + EnvUtil.getContextPath()
+ UtilsAndCommons.NACOS_NAMING_CONTEXT + "/instance?" + request.toUrl(); // /v/ns/instance
// delete instance asynchronously:
HttpClient.asyncHttpDelete(url, null, null, new Callback<String>() {
@Override
public void onReceive(RestResult<String> result) {
if (!result.ok()) {
Loggers.SRV_LOG
.error("[IP-DEAD] failed to delete ip automatically, ip: {}, caused {}, resp code: {}",
instance.toJson(), result.getMessage(), result.getCode());
}
}
@Override
public void onError(Throwable throwable) {
Loggers.SRV_LOG
.error("[IP-DEAD] failed to delete ip automatically, ip: {}, error: {}", instance.toJson(),
throwable);
}
@Override
public void onCancel() {
}
});
} catch (Exception e) {
Loggers.SRV_LOG
.error("[IP-DEAD] failed to delete ip automatically, ip: {}, error: {}", instance.toJson(), e);
}
}
}
可以看出init方法是开启了一个异步线程ClientBeatCheckTask去做了个周期性发送心跳的机制,方法中客户端心跳检查任务,开启延迟5s的任务,然后每隔5秒钟执行一次。
service.init()方法主要通过定时任务不断检测当前服务下所有实例最后发送心跳包的时间。在这个方法里面主要是循环当前service的每一个临时实例,用当前时间减去最后一次心跳时间是否大于15s来判断心跳是否超时,如果大于这个时间会执行instance.setHealthy(false)将实例的健康状态改为false,但是这个定时任务不会立即执行,会每5秒执行一次;当前时间 - 实例上一次心跳时间 > 实例的删除时间【默认30s】就会删除实例。
那么服务实例的最后心跳包更新时间是谁来触发的呢?实际上前面在说客户端注册时有说到, Nacos客户端注册服务的同时也建立了心跳机制。
7.3.4 服务端实例注册
上文中registerInstance注册实例方法中还有一个最最重要的方法就是addInstance()方法,其本质上就是把当前注册的服务实例保存到Service中。
public void addInstance(String namespaceId, String serviceName, boolean ephemeral, Instance... ips)
throws NacosException {
String key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral);
Service service = getService(namespaceId, serviceName);
synchronized (service) {
//将需要注册的实例全部放到Cluster,再将Cluster放在Service里
List<Instance> instanceList = addIpAddresses(service, ephemeral, ips);
Instances instances = new Instances();
instances.setInstanceList(instanceList);
//看一下 consistencyService 对象初始化的地方就知道走的是哪个实现
consistencyService.put(key, instances);
}
}
public static String buildInstanceListKey(String namespaceId, String serviceName, boolean ephemeral) {
//根据 ephemeral 取值默认是 true为临时实例,临时实例是存放在内存的;false即为永久实例写到文件的,可以通过此参数区分nacos是AP还是CP架构
return ephemeral
? buildEphemeralInstanceListKey(namespaceId, serviceName)
: buildPersistentInstanceListKey(namespaceId, serviceName);
}
这里着重看一下这个put方法,put方法主要做了两件事,第一对对客户端的请求过来的实例进行注册,第二是Nacos集群架构下的数据同步,Nacos默认用的是临时实例,也就是ephemeral = true,也就是本文的重点AP架构的Nacos注册原理。
public void put(String key, Record value) throws NacosException {
//注册逻辑:实际就是把实例注册任务放到内存阻塞队列中
onPut(key, value);
//AP 架构下的节点数据同步
distroProtocol.sync(new DistroKey(key, KeyBuilder.INSTANCE_LIST_KEY_PREFIX), DataOperation.CHANGE,
globalConfig.getTaskDispatchPeriod() / 2);
}
/**
* 注册逻辑
*/
public void onPut(String key, Record value) {
if (KeyBuilder.matchEphemeralInstanceListKey(key)) {
Datum<Instances> datum = new Datum<>();
datum.value = (Instances) value;
datum.key = key;
datum.timestamp.incrementAndGet();
//把客户端信息注册信息更新到注册表
dataStore.put(key, datum);
}
if (!listeners.containsKey(key)) {
return;
}
//这里放的是DataOperation.CHANGE
notifier.addTask(key, DataOperation.CHANGE);
}先来看一下onPut()方法,不难发现当注册实例数据有改变时,就无脑将这个实例扔到这个task内存阻塞队列中去,具体可以看一下addTask()方法。
public class Notifier implements Runnable {
private ConcurrentHashMap<String, String> services = new ConcurrentHashMap<>(10 * 1024);
//用于存放即将要注册实例信息的内存阻塞队列
private BlockingQueue<Pair<String, DataOperation>> tasks = new ArrayBlockingQueue<>(1024 * 1024);
/**
* Add new notify task to queue.
*
* @param datumKey data key
* @param action action for data
*/
public void addTask(String datumKey, DataOperation action) {
if (services.containsKey(datumKey) && action == DataOperation.CHANGE) {
return;
}
if (action == DataOperation.CHANGE) {
services.put(datumKey, StringUtils.EMPTY);
}
/**
* 把客户端的参数封装成pair对象后,放进了一个内存队列中,注册就结束了,看这里并没有把客户端的注册信息写进双层map中
* 凭经验能猜到,这里把客户端对象放进内存队列,后续肯定是通过异步起线程的方式去注册
*/
tasks.offer(Pair.with(datumKey, action));
}
public int getTaskSize() {
return tasks.size();
}
@Override
public void run() {
Loggers.DISTRO.info("distro notifier started");
/**
* Spring启动时就会开启一个线程加载 Notifier任务,这里就会死循环一直从内存队列中拿取实例信息实现异步注册
*
* 问 题1:这里的for循环会占用cpu资源吗?
* 不会占用,因为tasks是个阻塞队列,如果tasks中没有实例信息,这里就会阻塞在这,不会无脑死循环
*
* 问 题2:为什么要把实例信息都无脑先放在内存阻塞队列中,然后另起一个线程去异步注册呢?阿里这里为什么要这么设计?
* 个人理解:nacos是在阿里内部使用的中间件,一般是需要满足三高特性【高并发、高性能、高可扩展】,阿里内部就有几十万台机器,
* 如果不能实现高并发注册那么肯定会有很多问题。比如订单服务A需要注册到nacos时,是在订单A启动时就需要注册,服务注册到nacos的逻辑
* 还是比较复杂的【详见com.alibaba.nacos.naming.core.Service#updateIPs】,假如这里不用异步注册而是用同步注册的方式,那么
* 服务注册到nacos需要花费很多时间,这才是一个注册到nacos的行为就花费了大量时间,那么如果多几个中间需要加载的话,那得浪费多少时间?
* 所以这里采用异步注册。
*
* 问 题3:内存阻塞队列 tasks 会不会有堆积的情况呢?
* 实际上看了com.alibaba.nacos.naming.core.Cluster#updateIps注册方法可以发现,注册实际上就是把实例信息写进一个内存集合Set中
* 【com.alibaba.nacos.naming.core.Cluster#ephemeralInstances】这样的操作其实是很快的,假如真有个运维写了个批量注册的脚本
* 把一堆机器同时注册进来,那这样确实有可能会造成内存阻塞队列tasks的堆积现象,但是这种情况并没什么关系,Eureka有时候实例注册都会感知
* 几十秒,对当前的nacos架构而言,既然要实现高并发那么只能牺牲一点实例注册的即使响应时间。正常情况下,即使有几十台几百台机器同时注册,
* 由于注册是内存操作,速度也很快,可以说是准实时,基本上正常情况下注册信息1s就能感知到。
*
*/
for (; ; ) {
try {
//从内存队列中拿出任务
Pair<String, DataOperation> pair = tasks.take();
//拿出pair对象中的客户端信息去注册
handle(pair);
} catch (Throwable e) {
//这个线程即使抛异常也不终止
Loggers.DISTRO.error("[NACOS-DISTRO] Error while handling notifying task", e);
}
}
}
private void handle(Pair<String, DataOperation> pair) {
try {
//前面拼接的参数 "com.alibaba.nacos.naming.iplist.ephemeral.namespaceId##serviceName"
String datumKey = pair.getValue0();
//前面传的DataOperation.CHANGE。
DataOperation action = pair.getValue1();
services.remove(datumKey);
int count = 0;
if (!listeners.containsKey(datumKey)) {
return;
}
for (RecordListener listener : listeners.get(datumKey)) {
count++;
try {
if (action == DataOperation.CHANGE) {
/**
* 拿到前面放的map中的客户端信息dataStore.get,这里的key就是前面的
* 拼接的参数 "com.alibaba.nacos.naming.iplist.ephemeral.namespaceId##serviceName"
* 前面放的是DataOperation.CHANGE。
*
*/
listener.onChange(datumKey, dataStore.get(datumKey).value);
continue;
}
if (action == DataOperation.DELETE) {
listener.onDelete(datumKey);
continue;
}
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] error while notifying listener of key: {}", datumKey, e);
}
}
if (Loggers.DISTRO.isDebugEnabled()) {
Loggers.DISTRO
.debug("[NACOS-DISTRO] datum change notified, key: {}, listener count: {}, action: {}",
datumKey, count, action.name());
}
} catch (Throwable e) {
Loggers.DISTRO.error("[NACOS-DISTRO] Error while handling notifying task", e);
}
}
}当有实例需要注册时,直接调用addTask()方法将这个实例信息无脑扔进内存阻塞队列中去,注册就结束了。这个应该算是Nacos注册的一个精髓吧,Nacos为了提高性能其源码使用了大量的异步任务、异步线程等操作,用这些方式对提升Nacos性能有很大帮助。不难猜到,这里把客户端实例对象放进内存队列,后续肯定是通过异步起线程的方式去注册。
不难发现addTask()方法是Notifier类的方法,Notifier实现了Runnable接口,很明显这就是一个异步线程,这里跟上面的猜想一致,Nacos就是通过开启了一个异步线程实现注册的,具体的注册方法直接可以看Notifier线程的run()方法即可。那么这个Notifier线程是啥时候开启的呢?
@DependsOn("ProtocolManager")
@org.springframework.stereotype.Service("distroConsistencyService")
public class DistroConsistencyServiceImpl implements EphemeralConsistencyService, DistroDataProcessor {
//本类DistroConsistencyServiceImpl注入到了Spring容器中,所以项目启动时类加载的时候就会初始化这个方法
@PostConstruct
public void init() {
//线程池执行器,执行notifier线程的任务
GlobalExecutor.submitDistroNotifyTask(notifier);
}
}了解Spring的应该都知道这个是Spring加载的一种初始化方式,Spring启动时加载这个init方法初始化数据,就会开启一个线程加载Notifier任务。
看了Notifier线程的run()方法,不免会有几个疑问。第一、这里的for循环会占用cpu资源吗?第二、为什么要把实例信息都无脑先放在内存阻塞队列中,然后另起一个线程去异步注册呢?第三、阿里这里为什么要这么设计?这样设计好处是什么呢?
这里第一个问题不会占用cpu资源,因为tasks是个阻塞队列,如果tasks中没有实例信息,这里就会阻塞在这,不会无脑死循环,所以是不会占用cpu资源的;
第二个问题个人理解:Nacos是在阿里内部使用的中间件,肯定是需要满足高并发、高性能、高可扩展,阿里内部估计就有几十万台机器,如果不能实现高并发注册那么肯定会有很多问题。比如订单服务需要注册到nacos时,那么订单启动时就需要注册,服务注册到Nacos的逻辑还是比较复杂的【详见com.alibaba.nacos.naming.core.Service#updateIPs】,假如这里不用异步注册而是用同步注册的方式,那么服务注册到Nacos需要花费很多时间,这才是一个注册到Nacos的行为就花费了大量时间,那么如果多几个中间需要加载的话,那会浪费很多时间,所以这里采用异步注册。
那么我们再看一下异步写注册表的方法:
public void onChange(String key, Instances value) throws Exception {
Loggers.SRV_LOG.info("[NACOS-RAFT] datum is changed, key: {}, value: {}", key, value);
for (Instance instance : value.getInstanceList()) {
if (instance == null) {
// Reject this abnormal instance list:
throw new RuntimeException("got null instance " + key);
}
//设置权重默认值啥的
if (instance.getWeight() > 10000.0D) {
instance.setWeight(10000.0D);
}
if (instance.getWeight() < 0.01D && instance.getWeight() > 0.0D) {
instance.setWeight(0.01D);
}
}
//真正的注册实例的方法
updateIPs(value.getInstanceList(), KeyBuilder.matchEphemeralInstanceListKey(key));
recalculateChecksum();
}
public void updateIPs(Collection<Instance> instances, boolean ephemeral) {
Map<String, List<Instance>> ipMap = new HashMap<>(clusterMap.size());
for (String clusterName : clusterMap.keySet()) {
ipMap.put(clusterName, new ArrayList<>());
}
for (Instance instance : instances) {
try {
if (instance == null) {
Loggers.SRV_LOG.error("[NACOS-DOM] received malformed ip: null");
continue;
}
if (StringUtils.isEmpty(instance.getClusterName())) {
instance.setClusterName(UtilsAndCommons.DEFAULT_CLUSTER_NAME);
}
if (!clusterMap.containsKey(instance.getClusterName())) {
Loggers.SRV_LOG
.warn("cluster: {} not found, ip: {}, will create new cluster with default configuration.",
instance.getClusterName(), instance.toJson());
Cluster cluster = new Cluster(instance.getClusterName(), this);
cluster.init();
getClusterMap().put(instance.getClusterName(), cluster);
}
List<Instance> clusterIPs = ipMap.get(instance.getClusterName());
if (clusterIPs == null) {
clusterIPs = new LinkedList<>();
ipMap.put(instance.getClusterName(), clusterIPs);
}
clusterIPs.add(instance);
} catch (Exception e) {
Loggers.SRV_LOG.error("[NACOS-DOM] failed to process ip: " + instance, e);
}
}
for (Map.Entry<String, List<Instance>> entry : ipMap.entrySet()) {
//make every ip mine
List<Instance> entryIPs = entry.getValue();
/**
* 注册逻辑updateIps,更新注册表信息:
*
* 这个方法里面会将已经注册过的实例列表复制一份,将新的实例和老的实例都更新到一个集合中,
* 最终再将这个集合更新到真正的实例列表,是一种写时复制的思想,主要时为了解决并发冲突,
* 在写的过程中,其他线程读到的还是旧数据,等真正写完之后再将数据更新回去。
*
* 思考一下,正常情况下在写之前都要加锁,不然可能会有读写并发问题,这里为什么不在加锁?
* 假如这里加了一个锁之后,相当于把读和写操作排队串行化执行了,就是读写不能同时进行了,
* 这里并发肯定会很低,所以这里用copy on write机制,将原来的注册表复制出一个副本,然后进
* 行修改,此时读请求进来还是读老的注册表,这样读写就能并发执行。
*
* 那这里用读写分离和加锁串行执行有什么优劣势吗?
* 读写分离:写的时候写的是副本,读的是老得数据,这样可能读到读不是最新数据,只有当副本写完将
* 老数据替换,此时读的才是最新数据,读写分离虽然提高了读写并发但是对数据的一致性稍有妥协,但是
* 对于此时注册的场景而言影响不大,即使是没有读到最新数据也没关系,最多就当此服务启动的慢一点而
* 已,当前这个注册场景,还是提高并发注册能力稍重要些,若是对读写数据一致场景要求很高时,就必须得
* 加锁串行执行
*
* 加锁执行:读写都是加锁执行,写完后再去读,读的一定是最新的数据,读写数据强一致,但是这里根本不需要数据强一致
*
* 这里有个疑问注册时每个微服务都去复制一个副本,然后将副本替换回原件时会不会有覆盖的问题?
* 不会,这里是开的一个线程去拿内存队列的数据进行注册的,所以不可能存在覆盖并发问题。详见
* com.alibaba.nacos.naming.consistency.ephemeral.distro.DistroConsistencyServiceImpl#init()方法
*
*/
clusterMap.get(entry.getKey()).updateIps(entryIPs, ephemeral);
}
setLastModifiedMillis(System.currentTimeMillis());
//上面已经更新过了注册表后,这里需要发布事件,主动通知客户端
getPushService().serviceChanged(this);
StringBuilder stringBuilder = new StringBuilder();
for (Instance instance : allIPs()) {
stringBuilder.append(instance.toIpAddr()).append("_").append(instance.isHealthy()).append(",");
}
Loggers.EVT_LOG.info("[IP-UPDATED] namespace: {}, service: {}, ips: {}", getNamespaceId(), getName(),
stringBuilder.toString());
}
/**
* Update instance list.
*
* @param ips instance list 需要注册的实例
* @param ephemeral whether these instances are ephemeral 是哪种实例,永久实例还是临时实例
*/
public void updateIps(List<Instance> ips, boolean ephemeral) {
//根据传进来的 ephemeral 判断是哪种实例,直接把这种实例复制一份toUpdateInstances
Set<Instance> toUpdateInstances = ephemeral
? ephemeralInstances //临时实例 【这里这个实例是注册表已有的实例,这里直接将原有的实例再次复制了一份,就是toUpdateInstances】
: persistentInstances; //永久实例 【这里这个实例是注册表已有的实例,这里直接将原有的实例再次复制了一份,就是toUpdateInstances】
HashMap<String, Instance> oldIpMap = new HashMap<>(toUpdateInstances.size());
//循环将上面复制的实例toUpdateInstances放oldIpMap中
for (Instance ip : toUpdateInstances) {
oldIpMap.put(ip.getDatumKey(), ip);
}
/**
* 下面就是对比新注册的实例与副本实例的差异,判断新的实例是新增、删除、还是修改,这里使用了copyOnWrite机制,上面的toUpdateInstances就是
* 复制出来的副本,新增、删除、修改都是在副本上进行,之后再将原注册表覆盖
* 新增:直接新增到副本中
* 修改:直接修改副本的实例信息
* 删除:删除副本的实例
*
*/
//更新注册表
List<Instance> updatedIPs = updatedIps(ips, oldIpMap.values());
if (updatedIPs.size() > 0) {
for (Instance ip : updatedIPs) {
Instance oldIP = oldIpMap.get(ip.getDatumKey());
// do not update the ip validation status of updated ips
// because the checker has the most precise result
// Only when ip is not marked, don't we update the health status of IP:
if (!ip.isMarked()) {
ip.setHealthy(oldIP.isHealthy());
}
if (ip.isHealthy() != oldIP.isHealthy()) {
// ip validation status updated
Loggers.EVT_LOG.info("{} {SYNC} IP-{} {}:{}@{}", getService().getName(),
(ip.isHealthy() ? "ENABLED" : "DISABLED"), ip.getIp(), ip.getPort(), getName());
}
if (ip.getWeight() != oldIP.getWeight()) {
// ip validation status updated
Loggers.EVT_LOG.info("{} {SYNC} {IP-UPDATED} {}->{}", getService().getName(), oldIP.toString(),
ip.toString());
}
}
}
//删除注册表
List<Instance> newIPs = subtract(ips, oldIpMap.values());
if (newIPs.size() > 0) {
Loggers.EVT_LOG
.info("{} {SYNC} {IP-NEW} cluster: {}, new ips size: {}, content: {}", getService().getName(),
getName(), newIPs.size(), newIPs.toString());
for (Instance ip : newIPs) {
HealthCheckStatus.reset(ip);
}
}
List<Instance> deadIPs = subtract(oldIpMap.values(), ips);
if (deadIPs.size() > 0) {
Loggers.EVT_LOG
.info("{} {SYNC} {IP-DEAD} cluster: {}, dead ips size: {}, content: {}", getService().getName(),
getName(), deadIPs.size(), deadIPs.toString());
for (Instance ip : deadIPs) {
HealthCheckStatus.remv(ip);
}
}
toUpdateInstances = new HashSet<>(ips);第三个问题:可以看上面这个写注册表的源码,当服务A需要注册到Nacos时,并不是直接写进Nacos的注册表里,实际上是先拷贝了一个副本,订单服务注册写注册表时直接写副本的注册表,副本写完后才会替换原来Nacos中的注册表,所以当库存服务需要从Nacos拉取服务时,拉取的是Nacos实际注册表中的信息,这种设计方式能够大大提高Nacos的注册性能。
类似于CopyOnWriteArrayList的copy on write机制,也就是写时复制、读写分离设计思想。这种读写分离对于客户端注册感知实时性可能会稍差点,但是这种情况并没什么关系,Eureka有时候实例注册都会感知几十秒,对当前的nacos架构而言,既然要实现高并发那么只能牺牲一点实例注册的及时响应时间。
当Nacos注册成功后,就需要发布事件,主动通知客户端,接下来可以看一下发布事件的源码:
public void serviceChanged(Service service) {
// merge some change events to reduce the push frequency:
if (futureMap
.containsKey(UtilsAndCommons.assembleFullServiceName(service.getNamespaceId(), service.getName()))) {
return;
}
//时间发布,发布事件,通知客户端
this.applicationContext.publishEvent(new ServiceChangeEvent(this, service));
}这里Nacos会通过udp的方式将服务变动通知给订阅的客户端。Nacos的这种推送模式相对于zk那种利用tcp长连接而言还是会节约很多资源,即使有大量节点更新也不会使Nacos出现性能瓶颈。
当Nacos客户端接收到了udp消息后会给服务端返回一个ack,如果Nacos超时未收到ack,还会有重发机制,超过了这个超时时间就不再重发了。虽然udp是个不可靠协议不能保证消息一定能推送到客户端,但是Nacos客户端还是有定时轮训做兜底定时查询Nacos注册表。Nacas采用了这两种机制,既保证了实时性,又保证了数据更新不会被漏掉。
7.3.5 Nacos集群新节点启动数据同步
Nacos数据同步分为全量同步和增量同步,全量同步就是初始化数据一次性同步,而增量同步是指有数据增加的时候,只同步增加的数据。
7.3.5.1 Nacos集群全量数据同步
Nacos集群有新的节点启动时,DistroProtocol类就会在Spring加载时调用构造方法,同时开启一个数据同步任务,该方法会执行startVerifyTask()和startLoadTask(),我们重点关注startLoadTask(),具体代码如下:
@Component
public class DistroProtocol {
/**
* 当nacos集群只有两台机器时,此时若又新增一台机器,此时需要将原来两台机器的数据同步到新的nacos机器上
*
* @param memberManager
* @param distroComponentHolder
* @param distroTaskEngineHolder
* @param distroConfig
*/
public DistroProtocol(ServerMemberManager memberManager, DistroComponentHolder distroComponentHolder,
DistroTaskEngineHolder distroTaskEngineHolder, DistroConfig distroConfig) {
this.memberManager = memberManager;
this.distroComponentHolder = distroComponentHolder;
this.distroTaskEngineHolder = distroTaskEngineHolder;
this.distroConfig = distroConfig;
//本项目启动时DistroProtocol类加载时需要加载本构造方法,开启一个数据同步任务
startDistroTask();
}
private void startDistroTask() {
if (EnvUtil.getStandaloneMode()) {
isInitialized = true;
return;
}
//启动startVerifyTask,做数据同步校验
startVerifyTask();
//加载任务
startLoadTask();
}
private void startLoadTask() {
///处理状态回调对象
DistroCallback loadCallback = new DistroCallback() {
//处理成功
@Override
public void onSuccess() {
isInitialized = true;
}
//处理失败
@Override
public void onFailed(Throwable throwable) {
isInitialized = false;
}
};
GlobalExecutor.submitLoadDataTask(
new DistroLoadDataTask(memberManager, distroComponentHolder, distroConfig, loadCallback));
}
}
上面方法会调用DistroLoadDataTask对象,而该对象其实是个线程,因此会执行它的run方法,run方法会调用load()方法实现数据全量加载,代码如下:
public class DistroLoadDataTask implements Runnable {
private final ServerMemberManager memberManager;
private final DistroComponentHolder distroComponentHolder;
private final DistroConfig distroConfig;
private final DistroCallback loadCallback;
private final Map<String, Boolean> loadCompletedMap;
public DistroLoadDataTask(ServerMemberManager memberManager, DistroComponentHolder distroComponentHolder,
DistroConfig distroConfig, DistroCallback loadCallback) {
this.memberManager = memberManager;
this.distroComponentHolder = distroComponentHolder;
this.distroConfig = distroConfig;
this.loadCallback = loadCallback;
loadCompletedMap = new HashMap<>(1);
}
/**
* 数据加载过程
*/
@Override
public void run() {
try {
//加载数据
load();
if (!checkCompleted()) {
GlobalExecutor.submitLoadDataTask(this, distroConfig.getLoadDataRetryDelayMillis());
} else {
loadCallback.onSuccess();
Loggers.DISTRO.info("[DISTRO-INIT] load snapshot data success");
}
} catch (Exception e) {
loadCallback.onFailed(e);
Loggers.DISTRO.error("[DISTRO-INIT] load snapshot data failed. ", e);
}
}
}数据同步会通过Http请求从远程服务器获取数据,并同步到当前服务的缓存中。执行流程如下:
首先,loadAllDataSnapshotFromRemote()从远程加载所有数据,并处理同步到本机;
第二,transportAgent.getDatumSnapshot()远程加载数据,通过Http请求执行远程加载;
第三,dataProcessor.processSnapshot()处理数据同步到本地
/**
* 加载数据,并同步
*
* @throws Exception
*/
private void load() throws Exception {
while (memberManager.allMembersWithoutSelf().isEmpty()) {
Loggers.DISTRO.info("[DISTRO-INIT] waiting server list init...");
TimeUnit.SECONDS.sleep(1);
}
while (distroComponentHolder.getDataStorageTypes().isEmpty()) {
Loggers.DISTRO.info("[DISTRO-INIT] waiting distro data storage register...");
TimeUnit.SECONDS.sleep(1);
}
for (String each : distroComponentHolder.getDataStorageTypes()) {
if (!loadCompletedMap.containsKey(each) || !loadCompletedMap.get(each)) {
//从远端机器拉取数据,从远程加载所有数据,并处理同步到本机
loadCompletedMap.put(each, loadAllDataSnapshotFromRemote(each));
}
}
}
/**
* 从远端机器拉取数据
*
* @param resourceType
* @return
*/
private boolean loadAllDataSnapshotFromRemote(String resourceType) {
DistroTransportAgent transportAgent = distroComponentHolder.findTransportAgent(resourceType);
DistroDataProcessor dataProcessor = distroComponentHolder.findDataProcessor(resourceType);
if (null == transportAgent || null == dataProcessor) {
Loggers.DISTRO.warn("[DISTRO-INIT] Can't find component for type {}, transportAgent: {}, dataProcessor: {}",
resourceType, transportAgent, dataProcessor);
return false;
}
//拉取不包含自己的机器
for (Member each : memberManager.allMembersWithoutSelf()) {
try {
Loggers.DISTRO.info("[DISTRO-INIT] load snapshot {} from {}", resourceType, each.getAddress());
//调取接口获取除自己外的所有机器
DistroData distroData = transportAgent.getDatumSnapshot(each.getAddress());
//同步数据
boolean result = dataProcessor.processSnapshot(distroData);
Loggers.DISTRO
.info("[DISTRO-INIT] load snapshot {} from {} result: {}", resourceType, each.getAddress(),
result);
//同步成功直接return,从一台机器上同步
if (result) {
return true;
}
} catch (Exception e) {
Loggers.DISTRO.error("[DISTRO-INIT] load snapshot {} from {} failed.", resourceType, each.getAddress(), e);
}
}
return false;
}
private boolean checkCompleted() {
if (distroComponentHolder.getDataStorageTypes().size() != loadCompletedMap.size()) {
return false;
}
for (Boolean each : loadCompletedMap.values()) {
if (!each) {
return false;
}
}
return true;
}
到这为止实现数据全量同步,其实全量同步最终还是互相调用Nacos提供的api。总结一下全量数据同步的过程:
- 启动一个定时任务线程DistroLoadDataTask加载数据,调用load()方法加载数据
- 调用loadAllDataSnapshotFromRemote()方法从远程机器同步所有的数据
- 构造http请求,调用httpGet方法从指定的server获取数据
- 同步处理数据processData并执行监听器listener成功后,就更新data store
7.3.5.2 Nacos集群增量数据同步
当服务注册完成后,Nacos需要将客户端实例信息同步到Nacos集群其他节点,可以看一下Nacos底层是怎么实现的。我们再次回到put方法:
public void put(String key, Record value) throws NacosException {
//注册逻辑:实际就是把实例注册任务放到内存阻塞队列中
onPut(key, value);
//AP 架构下的节点数据同步
distroProtocol.sync(new DistroKey(key, KeyBuilder.INSTANCE_LIST_KEY_PREFIX), DataOperation.CHANGE,
globalConfig.getTaskDispatchPeriod() / 2);
}上文中已经解释过put方法中的 onPut(key, value)方法,接下来我们再了解一下AP结构Nacos下的节点数据是同步,也就是distroProtocol.sync方法。
**
* Start to sync data to all remote server.
*
* @param distroKey distro key of sync data
* @param action the action of data operation
*/
public void sync(DistroKey distroKey, DataOperation action, long delay) {
//循环将新增实例同步到除自己外的所有实例,单机for循环都不会走,集群架构就会走本方法
for (Member each : memberManager.allMembersWithoutSelf()) {
//先把每台机器都数据封装称distroKeyWithTarget对象
DistroKey distroKeyWithTarget = new DistroKey(distroKey.getResourceKey(), distroKey.getResourceType(),
each.getAddress());
DistroDelayTask distroDelayTask = new DistroDelayTask(distroKeyWithTarget, action, delay);
//添加到task任务中
distroTaskEngineHolder.getDelayTaskExecuteEngine().addTask(distroKeyWithTarget, distroDelayTask);
if (Loggers.DISTRO.isDebugEnabled()) {
Loggers.DISTRO.debug("[DISTRO-SCHEDULE] {} to {}", distroKey, each.getAddress());
}
}
/**
* 将集群中除自己外其他需要同步的机器信息添加到一个tasks任务中,由前面的知识可以猜到这里也是
* 用异步开启一个线程去拿tasks进行同步新增实例信息到其他nacos机器中
*
* @param key key of task
* @param newTask
*/
@Override
public void addTask(Object key, AbstractDelayTask newTask) {
lock.lock();
try {
AbstractDelayTask existTask = tasks.get(key);
if (null != existTask) {
newTask.merge(existTask);
}
//将集群中除自己外其他需要同步的机器信息添加到一个tasks任务中,task是个保存信息的ConcurrentHashMap
tasks.put(key, newTask);
} finally {
lock.unlock();
}
}
这里直接把需要同步的信息放在了内存的ConcurrentHashMap中,我们看一下这里具体看一下怎么同步其他节点。
@Component
public class DistroTaskEngineHolder {
//延迟任务执行器
private final DistroDelayTaskExecuteEngine delayTaskExecuteEngine = new DistroDelayTaskExecuteEngine();
//任务执行引擎器
private final DistroExecuteTaskExecuteEngine executeWorkersManager = new DistroExecuteTaskExecuteEngine();
public DistroTaskEngineHolder(DistroComponentHolder distroComponentHolder) {
DistroDelayTaskProcessor defaultDelayTaskProcessor = new DistroDelayTaskProcessor(this, distroComponentHolder);
delayTaskExecuteEngine.setDefaultTaskProcessor(defaultDelayTaskProcessor);
}
public DistroDelayTaskExecuteEngine getDelayTaskExecuteEngine() {
return delayTaskExecuteEngine;
}
public DistroExecuteTaskExecuteEngine getExecuteWorkersManager() {
return executeWorkersManager;
}
public void registerNacosTaskProcessor(Object key, NacosTaskProcessor nacosTaskProcessor) {
this.delayTaskExecuteEngine.addProcessor(key, nacosTaskProcessor);
}
}
这个类中会创建一个任务执行引擎,代码如下:
public class DistroDelayTaskExecuteEngine extends NacosDelayTaskExecuteEngine {
public DistroDelayTaskExecuteEngine() {
super(DistroDelayTaskExecuteEngine.class.getName(), Loggers.DISTRO);
}
@Override
public void addProcessor(Object key, NacosTaskProcessor taskProcessor) {
Object actualKey = getActualKey(key);
super.addProcessor(actualKey, taskProcessor);
}
@Override
public NacosTaskProcessor getProcessor(Object key) {
Object actualKey = getActualKey(key);
return super.getProcessor(actualKey);
}
private Object getActualKey(Object key) {
return key instanceof DistroKey ? ((DistroKey) key).getResourceType() : key;
}
}
//忽略一些中间省略的代码
public NacosDelayTaskExecuteEngine(String name, int initCapacity, Logger logger, long processInterval) {
super(logger);
tasks = new ConcurrentHashMap<Object, AbstractDelayTask>(initCapacity);
processingExecutor = ExecutorFactory.newSingleScheduledExecutorService(new NameThreadFactory(name));
//这里又执行了一个任务
processingExecutor
.scheduleWithFixedDelay(new ProcessRunnable(), processInterval, processInterval, TimeUnit.MILLISECONDS);
}
/**
* 执行了一个任务
*/
private class ProcessRunnable implements Runnable {
@Override
public void run() {
try {
processTasks();
} catch (Throwable e) {
getEngineLog().error(e.toString(), e);
}
}
}public boolean process(NacosTask task) {
if (!(task instanceof DistroDelayTask)) {
return true;
}
DistroDelayTask distroDelayTask = (DistroDelayTask) task;
DistroKey distroKey = distroDelayTask.getDistroKey();
if (DataOperation.CHANGE.equals(distroDelayTask.getAction())) {
//将延迟任务变更成异步任务,异步任务对象是一个线程
DistroSyncChangeTask syncChangeTask = new DistroSyncChangeTask(distroKey, distroComponentHolder);
//将前面封装到任务拿出来放在一个队列中
distroTaskEngineHolder.getExecuteWorkersManager().addTask(distroKey, syncChangeTask);
return true;
}
return false;
}
public void addTask(Object tag, AbstractExecuteTask task) {
//拿前面其他实例到任务
NacosTaskProcessor processor = getProcessor(tag);
if (null != processor) {
processor.process(task);
return;
}
TaskExecuteWorker worker = getWorker(tag);
//将同步数据到其他nacos实例到tasks任务放进一个queue中 在InnerWorker.run()方法中从queue队列中拿任务执行
worker.process(task);
}
public boolean process(NacosTask task) {
if (task instanceof AbstractExecuteTask) {
putTask((Runnable) task);
}
return true;
}
/**
* 把任务同步放进内存队列中
*
* @param task
*/
private void putTask(Runnable task) {
try {
queue.put(task);
} catch (InterruptedException ire) {
log.error(ire.toString(), ire);
}
}将同步数据到其他Nacos实例到tasks任务放进一个queue中,然后在InnerWorker.run()方法中从queue队列中拿任务执行。看一下具体是怎么执行同步任务的:
/**
* Inner execute worker.
*/
private class InnerWorker extends Thread {
InnerWorker(String name) {
setDaemon(false);
setName(name);
}
@Override
public void run() {
while (!closed.get()) {
try {
//从queue中拿同步任务
Runnable task = queue.take();
long begin = System.currentTimeMillis();
//实际就是执行异步同步任务 DistroSyncChangeTask 的run()
task.run();
long duration = System.currentTimeMillis() - begin;
if (duration > 1000L) {
log.warn("distro task {} takes {}ms", task, duration);
}
} catch (Throwable e) {
log.error("[DISTRO-FAILED] " + e.toString(), e);
}
}
}
}
这里从队列里面拿出来任务执行,不难发现这里的任务执行的具体方法就是DistroSyncChangeTask类的run方法:
public class DistroSyncChangeTask extends AbstractDistroExecuteTask {
private final DistroComponentHolder distroComponentHolder;
public DistroSyncChangeTask(DistroKey distroKey, DistroComponentHolder distroComponentHolder) {
super(distroKey);
this.distroComponentHolder = distroComponentHolder;
}
@Override
public void run() {
Loggers.DISTRO.info("[DISTRO-START] {}", toString());
try {
//获取各种参数
String type = getDistroKey().getResourceType();
DistroData distroData = distroComponentHolder.findDataStorage(type).getDistroData(getDistroKey());
distroData.setType(DataOperation.CHANGE);
//调用http接口同步任务
boolean result = distroComponentHolder.findTransportAgent(type).syncData(distroData, getDistroKey().getTargetServer());
//同步失败会继续重试
if (!result) {
handleFailedTask();
}
Loggers.DISTRO.info("[DISTRO-END] {} result: {}", toString(), result);
} catch (Exception e) {
Loggers.DISTRO.warn("[DISTRO] Sync data change failed.", e);
handleFailedTask();
}
}
/**
* 同步失败会继续重试
*/
private void handleFailedTask() {
String type = getDistroKey().getResourceType();
DistroFailedTaskHandler failedTaskHandler = distroComponentHolder.findFailedTaskHandler(type);
if (null == failedTaskHandler) {
Loggers.DISTRO.warn("[DISTRO] Can't find failed task for type {}, so discarded", type);
return;
}
failedTaskHandler.retry(getDistroKey(), DataOperation.CHANGE);
}
@Override
public String toString() {
return "DistroSyncChangeTask for " + getDistroKey().toString();
}
}每个Nacos服务端实例都会提供这样的一个api接口供其他Nacos实例调用,从而同步注册实例数据。DistroSyncChangeTask类的run方法,就是调用http接口同步任务接口,将本节点的注册实例数据同步到其他节点机器上。
总结一下上面增量数据同步方法:
DistroProtocol 使用 sync() 方法处理AP 架构下的节点数据同步
向其他节点发布广播任务调用 distroTaskEngineHolder 发布延迟任务
调用 DistroDelayTaskProcessor.process() 方法进行任务投递:将延迟任务转换为异步变更任务
执行变更任务 DistroSyncChangeTask.run() 方法:向指定节点发送消息
8、总结
Nacos避免并发读写的冲突:Nacos在更新实例列表时,会采用CopyOnWrite技术,首先将老得实例列表拷贝一份,然后更新拷贝的实例列表,再用更新后的实例列表来覆盖旧的实例列表。
Nacos提高注册并发:为了应对阿里巴巴内部数十万服务的并发写请求Nacos内部会将服务注册的任务放入阻塞队列,采用线程池异步来完成实例更新,从而提高并发写能力。
Nacos的服务发现分为两种模式:主动拉取模式,消费者定期主动从Nacos服务端拉取服务列表并缓存起来,当服务调用时优先读取本地缓存中的服务列表。订阅模式,消费者订阅Nacos中的服务列表,并基于UDP协议来接收服务变更通知。当Nacos中的服务列表更新时,会发送UDP广播给所有订阅者。与Eureka相比,Nacos的订阅模式服务状态更新更及时,消费者更容易及时发现服务列表的变化,剔除故障服务。