作者 | Isaac Lyman
译者 | 崔皓
谁都喜欢可读性强的代码,希望接手的代码容易阅读,容易理解,从而减少交接的工作量,但并不是所有的代码都有好的易读性,接手前辈的“屎山”通常是一件令开发者非常痛苦的事情。
关于代码有一种流行说法:代码被阅读的次数是它被书写次数的十倍,而且产品的寿命越长,这个比例就越高。考虑到这点,我们似乎对“理解代码”的投资明显不足。开发者通常更侧重于编码的能力,而不是阅读和解释已有代码的能力,即便这种场景在日常工作中会频繁出现。
开发任务的前80-95%时间应该用来阅读代码以及文档。在研究现有代码的过程中,你可能会学到很多东西,只有读完代码之后才能说:“这个功能已经存在了,或者是加入这个功能弊大于利”。
本文将为你介绍一些实用的代码阅读策略,你可以根据实际情况使用它们。
一、重构局部变量和方法
有时候,一段代码非常模糊会误导读者甚至让人难以推理出其含义。一个几乎没有风险的方法是重新命名局部变量和私有方法,以更准确地描述它们的作用。这些类型的修改不会影响到当前工作文件之外的功能,只要注意避免命名冲突,就不会导致逻辑错误。如果可能的话,使用IDE的重构工具(而不是文本查找和替换),这样就可以一键重命名所有被使用的东西了。
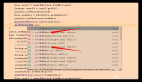
例如,考虑下面这段JavaScript代码
它阅读起来非常困难,方法名ib对理解函数功能毫无用处。不过,这并不妨碍你对它做出推断:
由于reduce是在a上被调用的(并且它返回到一个空数组),a应该是一个数组类型。
回调参数i将是该数组的一个元素。
reduce的第二个参数,一个空的对象{},告诉我们回调参数o是一个字典(对象)。
所以,通过重命名,我们可以得到如下结果:
通过上面的调整,可以看到fn是把数组元素变成字典的键。这就揭示了函数ib的目的:将数组转化为字典,用一个自定义的回调来确定索引每个元素的键。你可以把fn改名为getKey,而ib应该被命名为indexBy。重新命名一些标识符有助于我们理解代码,而不需要改变它的逻辑,也不需要一下子考虑所有的部分。如果可以的话,强烈推荐修改。毕竟这样可以提高代码的可读性,将使整个团队受益,同时它并没有增加或改变程序的功能。
二、搞清楚代码是如何被调用的
大多数代码都会被其他代码调用。如果你在纠结一段代码,那么搞清楚它的调用情况对于了解它的功能有非常大的帮助。可以将方法重命名为ThisBreaksOnPurpose。然后进行编译,尽管在通过反射访问的情况下,你在运行时才会看到错误,但编译的错误提示会告诉这个方法在哪里被使用。
如果以上方法不可行,你可以通过文本搜索方法名。如果你很幸运,这个方法的名字在代码库中是唯一的。如果不是这样,你可能会得到一个更大的结果集,并且不得不翻阅大量不相关的代码。
三、搜索类似的代码
有时,即使所有的标识符都被很好地命名,用例也很清晰,但是代码还是很难理解。不是所有的代码都符合编码习惯。有时某个特定的操作并没有遵循编码习惯。在最坏的情况下,有问题的代码出现在工作的代码库中,同时也没有使用明显的惯用语。
然而真正独特的代码在长期存在的代码库中是很少见的,特别是在单个表达式或代码行上。如果花几分钟时间在项目中搜索类似的代码,你可能会发现一些蛛丝马迹来解开整个谜题。
全文搜索是其中最简单的方法。你可以选择一个突出的代码片段进行搜索,搜索工具通常包括一个 "全词 "搜索选项,这意味着搜索care.exe不会返回scare.exertion这样的结果。如果你想进一步缩小范围,可以用正则表达式而不是文本短语进行搜索。
当然,偶尔即使是正则表达式也不足以缩小范围,没有人愿意花几个小时在搜索结果中寻找可能没有帮助的东西。学习一些高级搜索技术也是值得的。许多程序员喜欢使用Unix的命令行工具,如grep和awk,或者在Windows上使用手写的PowerShell脚本。我的首选是JS Powered Search,这是一个VS Code扩展,可以让你在JavaScript中定义一个逻辑搜索查询。
四、运行单元测试
在一个完美的代码库中,你可以通过使用单元测试了解代码运行的状态。但是大多数代码库并不完美;由于效率的原因,单元测试工作往往显得可有可无,有时单元测试所描述的是过时的行为。尽管如此,检查并执行代码测试仍旧是一个好主意。至少,他们会描述代码的输入和输出。
如果没有单元测试或者单元测试不够全面,你还有第二次挽救的机会。可以编写一两个测试来证明代码是否存在的问题。如果发现问题并修复它然后提交修改,增加代码库的稳定性,让这段代码具有自解释的能力。你永远不必担心增加自动化测试会破坏现有的功能。
测试需要花费时间来编写,但此举可以大大提升代码执行效率。测试是代码正常工作的实际证据,有单元测试在你就会相信代码功能不会被破坏。
五、使用Debugger工具
一旦有了单元测试,就有了很好的机制帮助你进行逐步的调试。设置一个断点或在这段代码的顶部添加一个断点/调试器语句。然后运行测试。一旦碰到了断点,执行就会暂停,你可以每次前进一行,进入和退出函数,并检查范围内所有变量的值。
如果你知道哪些用户行为触发了相关的代码,你就可以设置断点并正常运行程序,与程序的界面进行交互。如果你这样做,反馈回路会更长,但它也会使用更真实的数据,这可能有助于你发现空引用和边缘案例。
从上到下的逐行调试可能对运行几十或几百次的代码不太有用,比如嵌套的循环。对于这样的代码,可以在每个循环中添加汇总的变量,方便在循环结束的时查看总量。许多集成开发环境还允许你设置条件性断点,可以通过设置条件在循环中暂停并进入断点从而查看对应变量的值。
六、搜索知识库
如果你的团队把编写文档作为开发过程的一部分,你可以快速跳过这一步。文档不应该是唯一的真理来源,你应该依靠代码来了解程序的行为方式。
文档虽然可以解释代码的 "How",但它往往更擅长解释 "Why"。有时你明白一段代码在做什么,但从另一个角度看貌似有些不对。所以在改变它之前,你应该尽一切努力去了解原来的程序员是根据什么信息或约束来编码的。
一篇好的内部文档也能为你指出知道真相的队友。如果你已经走到了这一步,做了足够多的工作,那么可以向外寻求帮助。确保让对方知道你在做什么工作,你想解决什么问题,他们很有可能会注意到你的视野盲区。
七、使用版本控制注释
看到这里,你已经了解了几种有效的代码阅读策略。但即使如此,也可能会有无法解决的问题:一个奇怪的设计决定,一个打破代码库编码模式的方法,一个没有明显理由的代码特质。
版本控制系统可以显示代码库中任何一行代码的作者和提交。在Git中,就是git blame命令。大多数系统称它为"blue"或"annotate"。你可以在命令行或IDE中运行这个命令。出现的将是一个逐行的提交列表:一个提交哈希值,一个提交信息,以及一个作者。
如果该行代码的最近一次提交没有意义——例如它是一个格式化或空白的变化,就需要通过文件的变更历史来找到引入该行代码的提交。同样,版本控制系统有一些工具可以帮助你做到这一点。
一旦你拿到了PR和Ticket,不仅拥有了代码的背景,还可以找到与之相关的工作人员:代码的作者、PR审核者、任何评论或更新Ticket的人、签署QA的人。如果前几种方法都不奏效,那么是时候该和前辈们聊聊了。
八、先理解,再编码
通过对以上步骤的学习,或许对你有所帮助,特别是对代码背景的理解以及功能的实现方面。在你继续前进之前,还需要考虑重构代码以使其清晰,创建新的文档,在这里投入的任何时间都会让你和你的团队在代码的互动中获得回报。
有效阅读代码的能力是一种秘密武器,它可以使你快速通过技术面试,并使你成为任何团队的重要成员。擅长写代码的程序员是有价值的,擅长读代码的程序员就更具价值了。当生产中出现错误或急需开发新功能时,第一步也是最重要的一步就是理解,阅读代码是能让你顺利到达彼岸。
原文链接:https://stackoverflow.blog/2022/08/15/how-to-interrogate-unfamiliar-code/
译者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。