一、背景
转转基于Prometheus落地了一体化监控系统,并自研了告警系统,但研发同学每人每天都会接收到很多告警,导致重要的告警被淹没,部分同学会选择直接屏蔽掉所有告警,进一步加重问题。告警过多等同于没有告警。
另外,多个告警之间通常具有一定的关联性,如:SQL执行错误告警导致异常日志过多告警。而面对杂乱无章的告警,很难快速分析出告警的根本原因。
告警降噪治理十分重要,在此背景下,我们基于Alertmanager扩展研发了转转告警中心。
二、规范与SDK
2.1 发送告警
Alertmanager提供了告警发送的OpenAPI,其中,告警的labels用于识别同一条告警并对告警去重、降噪,相同labels的告警的annotations会被覆盖。startsAt与endsAt分别为告警发生时间与结束时间。
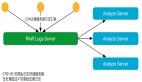
一条告警从提交到发送再到接收人的流程大致如下图所示,其中,Alertmanager需要集群部署来保证高可用性,需要注意的是,发送告警时不能对集群做负载均衡,必须要对集群内所有的Alertmanager发送告警才能保证高可用性。

2.2 常用标签
Alertmanager为基于标签的告警降噪,需提前规范告警常见标签。
- ENV:环境,如:线上环境、测试环境
- APP:服务名
- SOURCE:告警来源,如:日志告警、JVM告警
- NAME:告警名称
- LEVEL:告警等级,如:P0告警、P5告警
- INSTANCE:告警实例IP
- RECEIVER_TYPE:告警接受者类型
- RECEIVER:告警接受者,与RECEIVER_TYPE配合使用,如RECEIVER_TYPE=邮件,RECEIVER即为邮箱地址。
Alertmanager标签名的正则规则为[a-zA-Z_][a-zA-Z0-9_]*,在真正发送通知时,最好将标签名做一次中文映射转换。
2.3 SDK
我们针对Alertmanager开发了发送告警的SDK,如下所示,发送告警非常简单,SDK默认会为每条告警自动增加服务名、环境、IP、告警等级,并按照接收方拆开为多条告警发送。每一项内容都是标签,其中value较为特殊,放在了annotations内,其他均放在了labels内用于唯一识别一条告警。
三、告警降噪
3.1 分组去重
分组机制可以将多条告警信息合并成一个通知。例如,当集群中有数百个正在运行的服务实例,假如此时发生了网络故障,结果就会有数百个告警被发送到Alertmanager。
而作为用户,可能只希望能够在一个通知中就能查看哪些服务实例受到影响。这时可以按照服务所在集群或者告警名称对告警进行分组,将这些告警聚合在一起成为一个通知。
Alertmanager可以将收到的告警按照特定的标签分组、去重,并基于以下参数决定何时发送组内的告警通知,Alertmanager的每一次通知都会包含当前组内的所有告警。
- 初始等待时间(group_wait):一组告警第一次发送之前等待的时间,用于等待同一组的更多告警合并发送。
- 变化等待时间(group_interval):一组已发送初始通知的告警在接收到新告警或有告警恢复后,再次发送通知前等待的时间。
- 重复等待时间(repeat_interval):一组已发送初始通知的告警,组内告警均没有恢复且没有新增告警,再次发送通知前等待的时间。
下面以一张图,来展示从告警产生到合并到某个集合中,到发送通知的整个过程。三角形和圆形表示不断产生的告警,矩形代表实际的通知时间以及告警内容。

3.2 恢复通知
Alertmanager自带恢复通知,默认5m没有收到告警后,告警将被认为恢复,然后会等待group_interval后通知给用户。发送告警时也可以指定告警恢复时间,如下所示:
需要注意的是,endTime如果小于当前时间,会认为告警在发出时就已经恢复,这条告警不会通知。

3.3 告警分级
我们将告警分为P0~P5六个等级,告警等级默认取决于服务重要性,转转服务按照重要性分了A、B、C、D、E五个等级,服务重要性与告警等级的对应关系:A → P1,B → P2,C → P3,D → P4,E → P5。发送告警时也可以指定告警等级,如下:
告警分级的目的是尽量让高等级的告警及时发出,低等级的告警减少用户打扰次数。不同等级告警的分组、去重时间均不相同。
如:P4/P5的告警初始时会等待3m收集告警,并将当前告警接收者的所有告警汇总到一条通知内;
P0的告警只会等待15s收集告警,并按照告警接收者、环境、服务名、告警来源、告警名称为维度拆分成多个通知。
告警等级 | 分组标签 | group_wait | group_interval | repeat_interval |
P0 | 告警接收者、环境、服务名、告警来源、告警名称 | 15s | 1m | 30m |
P1 | 告警接收者、环境、服务名、告警来源 | 30s | 5m | 1h |
P2 | 告警接收者、环境、服务名 | 1m | 5m | 1h |
P3 | 告警接收者、环境 | 2m | 10m | 2h |
P4/P5 | 告警接收者 | 3m | 10m | 4h |
3.4 通知合并
统一使用Alertmanager webhook通知,一次通知内容会包含分组内的多个报警,我们会按照告警相似度对告警做合并,如下为6条报警合并成一条通知,其中,告警值与服务实例一一对应。

定义相似度:对于多个报警的labels,只有一个label value不一样,剩余的label key与label value均相同,则认为相似并合并;一次Alertmanager webhook通知可按照相似度拆分成多种告警,不同的告警提取公共标签,最终推送到一条通知内。
如下,为4条告警合并到一条通知,可清晰的看到两台机器的异常日志报警的原因是由于Druid执行SQL错误导致。

3.5 告警抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
当同一个服务、环境、告警来源、IP、接受者、告警名称,同时出现多个等级的告警时,高等级的告警会抑制低等级告警的通知。
如:告警名称为FGC次数,P1告警阈值为20次,P2告警为10次,当某个实例的FGC次数达到20次以上时,只会发送P1告警,不会发送P2告警。
四、多通知机制
支持企业微信、企业微信群、短信、邮件、电话、WebHook,可在一个告警内同时指定多种接收方式,我们会自动按照接收人拆分成多条告警。
- 企业微信、企业微信群、邮件、WebHook:最详细,发送告警与恢复通知。
- 短信:相对以上,只是不会发送恢复通知。
- 电话:不会发送恢复通知,并且只会播报报警标题与告警服务名。
五、未恢复告警
为了防止告警过多时淹没了重要告警,在每条告警的最后,都提供了一个未恢复告警链接,用于实时查询当前未恢复的告警。
未恢复告警拥有三种状态:活跃、静默、抑制。其中,活跃状态可以设置静默,静默状态可以查看被谁静默。

六、静默告警
基于Alertmanager OpenAPI,支持基于标签的静默告警,每条告警通知内都提供了一个链接用于快速静默,也可以在未恢复告警内静默告警。
点击新增静默后,会自动补充静默匹配的标签项,也可以增减标签项,如:去掉INSTANCE标签维度以便匹配所有的机器,修改_RECEIVER为其他人等。需要注意的是,添加静默时RECEIVER必须要指定。
添加完成后,会自动跳转到静默列表,并展示刚刚添加的静默项。

在静默列表内可查询所有的活跃、过期的静默项,可编辑、删除、查看影响的告警。

查看受影响的告警为实时查询,如果当前静默没有匹配到任何告警,查询结果会为空。

七、告警历史
告警通知给用户后,我们会保留三个月的历史告警记录列表。

八、总结
Alertmanager提供了告警降噪的策略,我们在Alertmanager的基础上制定了标签规范、告警分级降噪、分级抑制、告警合并,并基于Alertmanager OpenAPI扩展了未恢复告警、静默告警、告警历史。Alertmanager虽然不是告警降噪的银弹,但也可以解决大部分问题,如果你也面临着告警轰炸的问题,可以尝试一下。
关于作者
苑冲,转转架构部存储服务负责人,主要负责MQ、监控系统、Redis、KV存储等。爱学习,喜欢以辩证思维与变化思维思考。