让ChatGPT帮你写剧本,Stable Diffusion生成插图,做视频就差个配音演员了?它来了!
最近来自微软的研究人员发布了一个全新的文本到语音(text-to-speech, TTS)模型VALL-E,只需要提供三秒的音频样本即可模拟输入人声,并根据输入文本合成出对应的音频,而且还可以保持说话者的情感基调。

论文链接:https://arxiv.org/abs/2301.02111
项目链接:https://valle-demo.github.io/
代码链接:https://github.com/microsoft/unilm
先看看效果:假设你有了一段3秒钟的录音。
diversity_speaker音频:00:0000:03
然后只需要输入文本「Because we do not need it.」,即可获得合成的语音。
diversity_s1音频:00:0000:01
甚至使用不同的随机种子,还能进行个性化的语音合成。
diversity_s2音频:00:0000:02
VALL-E还能保持说话人的环境声,比如输入这段语音。
env_speaker音频:00:0000:03
再根据文本「I think it's like you know um more convenient too.」,就能输出合成语音的同时保持环境声。
env_vall_e音频:00:0000:02
而且VALL-E也能保持说话人的情绪,比如输入一段愤怒的语音。
anger_pt音频:00:0000:03
再根据文本「We have to reduce the number of plastic bags.」,同样可以表达愤怒的情绪。
anger_ours音频:00:0000:02
在项目网站上还有更多的例子。
从方法上具体来说,研究人员从现成的神经音频编解码器模型中提取的离散编码来训练语言模型VALL-E,并将TTS视为一个条件语言建模任务而非连续信号回归。
在预训练阶段,VALL-E接受的TTS训练数据达到了6万小时的英语语音,比现有系统用到的数据大了几百倍。
并且VALL-E还展现出了语境学习(in-context learning)能力,只需将unseen speaker的3秒注册录音作为声音提示,即可合成高质量的个性化语音。
实验结果表明,VALL-E在语音自然度和说话人相似度方面明显优于最先进的zero-shot TTS系统,还可以在合成中保留说话人的情感和声音提示的声学环境。
Zero-shot语音合成
过去十年,通过神经网络和端到端建模的发展,语音合成取得了巨大突破。
但目前级联的文本到语音(TTS)系统通常利用具有声学模型的pipeline和使用mel谱图作为中间表示的声码器(vocoder)。
虽然一些高性能的TTS系统可以从单个或多个扬声器中合成高质量的语音,但它仍然需要来自录音室的高质量清洁数据,从互联网上抓取的大规模数据无法满足数据要求,而且会导致模型的性能下降。
由于训练数据相对较少,目前的TTS系统仍然存在泛化能力差的问题。
在zero-shot的任务设置下,对于训练数据中没有出现过的的说话人,相似度和语音自然度都会急剧下降。
为了解决zero-shot的TTS问题,现有的工作通常利用说话人适应(speaker adaption)和说话人编码(speaker encoding)等方法,需要额外的微调,复杂的预先设计的特征,或沉重的结构工程。
与其为这个问题设计一个复杂而特殊的网络,鉴于在文本合成领域的成功,研究人员认为最终的解决方案应当是尽可能地用大量不同的数据来训练模型。
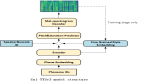
VALL-E模型
在文本合成领域,来自互联网的大规模无标记数据直接喂入模型,随着训练数据量的增加,模型性能也在不断提高。
研究人员将这一思路迁移到语音合成领域,VALL-E模型是第一个基于语言模型的TTS框架,利用海量的、多样化的、多speaker的语音数据。

为了合成个性化的语音,VALL-E模型根据3秒enrolled录音的声学token和音素prompt来生成相应的声学token,这些信息可以限制说话人和内容信息。

最后,生成的声学token被用来与相应的神经编解码器合成最终波形。
来自音频编解码器模型的离散声学token使得TTS可以被视为有条件的编解码器语言建模,所以一些先进的基于提示的大模型技术(如GPTs)就可以被用在TTS任务上了。
声学token还可以在推理过程中使用不同的采样策略,在TTS中产生多样化的合成结果。
研究人员利用LibriLight数据集训练VALL-E,该语料库由6万小时的英语语音组成,有7000多个独特的说话人。原始数据是纯音频的,所以只需要使用一个语音识别模型来生成转录即可。
与以前的TTS训练数据集,如LibriTTS相比,论文中提供的新数据集包含更多的噪声语音和不准确的转录,但提供了不同的说话人和语体(prosodies)。
研究人员认为,文章中提出的方法对噪声具有鲁棒性,并可以利用大数据来实现良好的通用性。

值得注意的是,现有的TTS系统总是用几十个小时的单语者数据或几百个小时的多语者数据进行训练,比VALL-E小几百倍以上。
总之,VALL-E是一种全新的、用于TTS的语言模型方法,使用音频编解码代码作为中间表征,利用大量不同的数据,赋予模型强大的语境学习能力。
推理:In-Context Learning via Prompting
语境学习(in-context learning)是基于文本的语言模型的一个令人惊讶的能力,它能够预测未见过的输入的标签而不需要额外的参数更新。
对于TTS来说,如果模型能够在不进行微调的情况下为未见过的说话者合成高质量的语音,那么该模型就被认为具有语境中学习能力。
然而,现有的TTS系统的语境中学习能力并不强,因为它们要么需要额外的微调,要么对未见过的说话者来说会有很大的退化。
对于语言模型来说,prompting是必要的,以便在zero-shot的情况下实现语境学习。
研究人员设计的提示和推理如下:
首先将文本转换为音素序列,并将enrolled录音编码为声学矩阵,形成音素提示和声学提示,这两种提示都用于AR和NAR模型中。
对于AR模型,使用以提示为条件的基于采样的解码,因为beam search可能导致LM进入无限循环;此外,基于抽样的方法可以大大增加输出的多样性。
对于NAR模型,使用贪婪解码来选择具有最高概率的token。
最后,使用神经编解码器来生成以八个编码序列为条件的波形。
声学提示可能与要合成的语音之间不一定存在语义关系,所以可以分为两种情况:
VALL-E:主要目标是为未见过的说话者生成给定的内容。
该模型的输入为一个文本句子、一段enrolled语音及其相应的转录。将enrolled语音的转录音素作为音素提示添加到给定句子的音素序列中,并使用注册语音的第一层声学token作为声学前缀。有了音素提示和声学前缀,VALL-E为给定的文本生成声学token,克隆这个说话人的声音。
VALL-E-continual:使用整个转录和话语的前3秒分别作为音素和声学提示,并要求模型生成连续的内容。
推理过程与设置VALL-E相同,只是enrolled语音和生成的语音在语义上是连续的。
实验部分
研究人员在LibriSpeech和VCTK数据集上评估了VALL-E,其中所有测试的说话人在训练语料库中都没有出现过。
VALL-E在语音自然度和说话人相似度方面明显优于最先进的zero-shot TTS系统,在LibriSpeech上有+0.12的比较平均选项得分(CMOS)和+0.93的相似度平均选项得分(SMOS)。

VALL-E在VCTK上也以+0.11 SMOS和+0.23 CMOS的性能改进超越了基线系统,甚至达到了针对ground truth的+0.04CMOS得分,表明在VCTK上,未见过的说话者的合成语音与人类录音一样自然。

此外,定性分析表明,VALL-E能够用2个相同的文本和目标说话人合成不同的输出,这可能有利于语音识别任务的伪数据创建。
实验中还可以发现,VALL-E能够保持声音环境(如混响)和声音提示的情绪(如愤怒等)。
安全隐患
强大的技术如果被乱用,就可能对社会造成危害,比如电话诈骗的门槛又被拉低了!
由于VALL-E具有潜在的恶作剧和欺骗的能力,微软并没有开放VALL-E的代码或接口以供测试。
有网友分享道:如果你给系统管理员打电话,录下他们说「你好」的几句话,然后根据这几句话重新合成语音「 你好,我是系统管理员。我的声音是唯一标识,可以进行安全验证。」我之前一直认为这是不可能的,你不可能用那么少的数据来完成这个任务。现在看来,我可能错了......
在项目最后的道德声明(Ethics Statement)中,研究人员表示「本文的实验是在模型使用者为目标说话人并得到说话人认可的假设下进行的。然而,当该模型推广到看不见的说话人时,相关部分应该伴有语音编辑模型,包括保证说话人同意执行修改的协议和检测被编辑语音的系统。」

作者同时在论文中进行声明,由于 VALL-E 可以合成能够保持说话者身份的语音,它可能会带来误用该模型的潜在风险,例如欺骗声音识别或者模仿特定的说话者。
为了降低这种风险,可以建立一个检测模型来区分音频剪辑是否由 VALL-E 合成。在进一步开发这些模型时,我们还将把微软人工智能原则付诸实践。
参考资料: