译者 | 陈峻
审校 | 孙淑娟
众所周知,人类在很小的时候就学会了识别和标记自己所看到的事物。如今,随着机器学习和深度学习算法的不断迭代,计算机已经能够以非常高的精度,对捕获到的图像进行大规模的分类了。目前,此类先进算法的应用场景已经涵括到了包括:解读肺部扫描影像是否健康,通过移动设备进行面部识别,以及为零售商区分不同的消费对象类型等领域。
下面,我将和您共同探讨计算机视觉(Computer Vision)的一种应用——图像分类,并逐步展示如何使用TensorFlow,在小型图像数据集上进行模型的训练。
1、数据集和目标
在本示例中,我们将使用MNIST数据集的从0到9的数字图像。其形态如下图所示:

我们训练该模型的目的是为了将图像分类到其各自的标签下,即:它们在上图中各自对应的数字处。通常,深度神经网络架构会提供一个输入、一个输出、两个隐藏层(Hidden Layers)和一个用于训练模型的Dropout层。而CNN或卷积神经网络(Convolutional Neural Network)是识别较大图像的首选,它能够在减少输入量的同时,捕获到相关的信息。
2、准备工作
首先,让我们通过TensorFlow、to_categorical(用于将数字类的值转换为其他类别)、Sequential、Flatten、Dense、以及用于构建神经网络架构的 Dropout,来导入所有相关的代码库。您可能会对此处提及的部分代码库略感陌生。我会在下文中对它们进行详细的解释。
3、超参数
- 我将通过如下方面,来选择正确的超参数集:
- 首先,让我们定义一些超参数作为起点。后续,您可以针对不同的需求,对其进行调整。在此,我选择了128作为较小的批量尺寸(batch size)。其实,批量尺寸可以取任何值,但是2的幂次方大小往往能够提高内存的效率,因此应作为首选。值得注意的是,在决定合适的批量尺寸时,其背后的主要参考依据是:过小的批量尺寸会使收敛过于繁琐,而过大的批量尺寸则可能并不适合您的计算机内存。
- 让我们将epoch(训练集中每一个样本都参与一次训练)的数量保持为50 ,以实现对模型的快速训练。epoch数值越低,越适合小而简单的数据集。
- 接着,您需要添加隐藏层。在此,我为每个隐藏层都保留了128个神经元。当然,你也可以用64和32个神经元进行测试。就本例而言,像MINST这样的简单数据集,我并不建议使用较高的数值。
- 您可以尝试不同的学习率(learning rate),例如0.01、0.05和0.1。在本例中,我将其保持为0.01。
- 对于其他超参数,我将衰减步骤(decay steps)和衰减率(decay rate)分别选择为2000和0.9。而随着训练的进行,它们可以被用来降低学习率。
- 在此,我选择Adamax作为优化器。当然,您也可以选择诸如Adam、RMSProp、SGD等其他优化器。
4、创建训练和测试集
由于TensorFlow库也包括了MNIST数据集,因此您可以通过调用对象上的 datasets.mnist ,再调用load_data() 的方法,来分别获取训练(60,000个样本)和测试(10,000个样本)的数据集。
接着,您需要对训练和测试的图像进行整形和归一化。其中,归一化会将图像的像素强度限制在0和1之间。
最后,我们使用之前已导入的to_categorical 方法,将训练和测试标签转换为已分类标签。这对于向TensorFlow框架传达输出的标签(即:0到9)为类(class),而不是数字类型,是非常重要的。
5、设计神经网络架构
下面,让我们来了解如何在细节上设计神经网络架构。
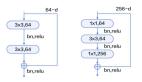
我们通过添加Flatten ,将2D图像矩阵转换为向量,以定义DNN(深度神经网络)的结构。输入的神经元在此处对应向量中的数字。
接着,我使用Dense() 方法,添加两个隐藏的密集层,并从之前已定义的“params”字典中提取各项超参数。我们可以将“relu”(Rectified Linear Unit)作为这些层的激活函数。它是神经网络隐藏层中最常用的激活函数之一。
然后,我们使用Dropout方法添加Dropout层。它将被用于在训练神经网络时,避免出现过拟合(overfitting)。毕竟,过度拟合模型倾向于准确地记住训练集,并且无法泛化那些不可见(unseen)的数据集。
输出层是我们网络中的最后一层,它是使用Dense() 方法来定义的。需要注意的是,输出层有10个神经元,这对应于类(数字)的数量。
6、训练
至此,我们已经定义好了架构。下面让我们用给定的训练数据,来编译和训练神经网络。
首先,我们以初始学习率、衰减步骤和衰减率作为参数,使用ExponentialDecay(指数衰减学习率)来定义学习率计划。
其次,将损失函数定义为CategoricalCrossentropy(用于多类式分类)。
接着,通过将优化器 (即:adamax)、损失函数、以及各项指标(由于所有类都同等重要、且均匀分布,因此我选择了准确性)作为参数,来编译模型。
然后,我们通过使用x_train、y_train、batch_size、epochs和validation_data去调用一个拟合方法,并拟合出模型。
同时,我们调用模型对象的评估方法,以获得模型在不可见数据集上的表现分数。
最后,您可以使用在模型对象上调用的save方法,保存要在生产环境中部署的模型对象。
7、小结
综上所述,我们讨论了为图像分类任务,训练深度神经网络的一些入门级的知识。您可以将其作为熟悉使用神经网络,进行图像分类的一个起点。据此,您可了解到该如何选择正确的参数集、以及架构背后的思考逻辑。
原文链接:https://www.kdnuggets.com/2022/12/guide-train-image-classification-model-tensorflow.html