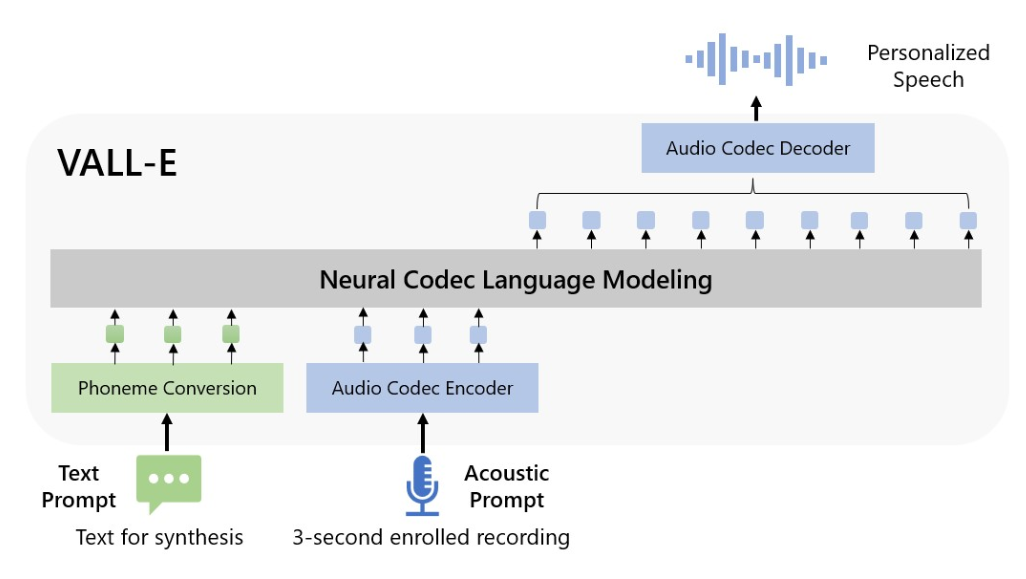
1 月 10 日消息,微软最近发布了一款名为 VALL-E 的人工智能工具,只需 3 秒音频即可模仿人说话。
该工具经过 60000 小时英语语音数据的训练,并使用特定语音的 3 秒剪辑来生成内容。与目前的许多人工智能工具不同,VALL-E 可以复制说话者的情绪和语气,即使说话者本人从未说过的单词也可以模仿。
IT之家了解到,康奈尔大学的一篇论文使用 VALL-E 合成了几种声音,大家可以在 GitHub 上聆听这些 AI 合成的音频。
研究人员指出,在许多情况下,Vall-E 的性能优于当前的文本到语音转换模型。然而,该研究还写道,人工智能模型目前存在几个问题。例如,文本提示中的某些单词可能会发音不清晰、完全遗漏或在输出中出现两次。此外,该模型目前难以模仿某些声音,尤其是带有口音的声音。
像其他 AI 新技术一样,VALL-E 在安全、伦理等方面也引发了担忧。微软发布了关于使用 VALL-E 的道德声明,但未来的使用用途方面没有明确说明。
目前,微软 Vall-E 尚未开源。微软已经在 GitHub 上创建了一个 Vall-E 存储库,但目前只包含一个描述文件。