GPU作为一种协处理器,传统用途主要是处理图像类并行计算任务;计算机系统面对的计算任务有着复杂而不同的性能要求,当 CPU 无法满足特定处理任务时,则需要一个针对性的协处理器辅助计算。GPU 就是针对图像计算高并行度,高吞吐量,容忍高延迟而定制的并行处理器。
本文选自“从软件算法生态看GPU发展与局限”,重点介绍GPU原理、GPU场景、局限性等,具体内容如下:
1、GPU是什么?
2、为什么需要GPU等协处理器?
3、GPU还能干什么?
4、GPU不适合干什么?
5、GPU总体市场现状
GPU简介
GPU其原始设计针对图像计算的特性进行优化,因此也能兼职一些与图像计算特性接近的大规模并行标准浮点数计算任务,如科学计算与数值模拟。但大规模并行计算并非一个笼统的概念,而是一个可以按照计算性能需求在6个维度上进行细分的大类别。因此GPU绝非解决大规模并行计算问题的万金油,无法很好的支持与图形计算特性相差较大的并行计算任务。
1.1 GPU 是什么?
GPU其他名称有显示核心、视觉处理器、显示芯片。顾名思义,GPU最主要的应用场景就是处理图像显示计算。计算机图像显示流程见图,在这个过程中CPU决定了显示内容,而GPU则决定了显示的质量如何。像GPU这类辅助CPU完成特定功能芯片统称“协处理器”,“协”字表明了GPU在计算机体系中处于从属地位。

GPU芯片可根据与CPU的关系分为独立GPU和集成GPU。独立GPU通常图形处理能力更高一些,但也有成本更高,功耗和发热较大等问题。近年集成式GPU流行于移动计算平台如笔记本和智能手机。例如高通的智能手机芯片通常将CPU和一个功能较弱的GPU以及其他协处理器通过SoC(System on Chip,片上系统)技术组合在一起。集成GPU图形计算性能相对独立GPU较弱但功耗/成本均针对了移动计算平台的需求做了优化,将长期占据移动计算市场。

1.2 为什么需要 GPU 等协处理器?
在计算机系统中,之所以出现GPU等协处理器,归根到底在于没有一种芯片设计方案能够满足所有不同类别计算任务所需求的全部性能指标:
- 计算精度;
- 计算并行度;
- 计算延迟;
- 计算吞吐量;
- 并行进程之间的交互复杂度;
- 计算实时性要求;
鱼和熊掌不可兼得;在设计计算机芯片中,以上六个指标不可能在有限的资源约束下同时满足。图的雷达图比较了CPU的设计偏向(蓝线)以及图形计算的要求(红线),越靠近外圈则表示要求高/性能好,如计算延迟低、计算吞吐量大。

我们可以发现CPU设计的一部分偏好,如并行进程交互能力强,低计算延迟是图形计算所不需要的;但图形计算要求的高计算并行度,高计算吞吐量是CPU所不能提供的。将CPU应用在图形处理中会造成一部分性能被浪费,而另一些性能CPU无法满足要求(雷达图上红线和蓝线的显著差异);这提供了GPU这种针对图形技术优化芯片性能指标的协处理器的生存空间。
在广义计算系统体系中,其他类别的协处理器,如DSP,FPGA,BP等协处理器之所以独立存在,均因为其所处理的特定计算任务在计算指标雷达图中与CPU以及其他协处理器差异过大。一个协处理器产业是否有足够的市场空间主要取决于其针对的计算任务在性能雷达图中是否独特(否则会被CPU等“兼职”),以及这种计算任务是否有足够大市场需求。
1.3 GPU 还能干什么?
GPU生产厂商针对图形处理的性能要求将资源分配强化两个特定指标:计算并行度和计算吞吐量。除了图形计算以外,还有一些计算任务的性能雷达图落在GPU的性能范围内或相差不甚太远(见图),比如数值仿真模拟、金融类计算、搜索引擎、数据挖掘等。

正因看中拓展GPU在特殊计算任务的应用前景,主流的GPU厂商纷纷推出软硬件结合的并行编程解决方案。例如Nvidia推出闭源的CUDA并行计算平台,而AMD推出了基于开放性OpenCL标准的Stream技术。这类技术在软件上提供一个定制的编译器,将计算任务尽可能分解成可独立并行执行的小组件(术语为“线程”);在硬件上对GPU进行小幅度修改,少量提高其在延迟/并行交互等传统弱项的性能。
虽然GPU的并行计算能力与金融数据处理需求存在一定匹配(图4中红线和蓝线相近),但金融核心账本计算中需要远超过一般计算平台的精度。GPU内部搭载的2进制计算单元无法保障账本分毫不差;金融业的核心账本计算业务长期依赖搭载10进制计算单元的IBM Power系列高端处理器。如果改造GPU使其搭载10进制硬件计算单元,则其又无法适应图形计算的需求。这个案例充分说明:并非所有并行计算任务就一定适合GPU计算,而需要根据实际情况区分。
1.4 GPU 不适合干什么?
GPU属于大规模并行计算芯片的一个子类;但其并不能解决所有的大规模并行计算任务。大规模并行计算芯片可粗略划分为两大组成部分:
1)并行计算单元,数目从数个至数千个不等,完成“线程”计算;
2)NoC(Network on Chip,片上通讯网络),负责在计算单元之间传递数据;
针对不同的计算需求场景,大规模并行计算芯片的设计思路大体有两个方向:
1)处理单元优化:包括增减处理器单元数量或改变处理器单元内部的结构等;
2)NoC网络优化:更改网络拓扑、网络路由算法、优化网络控制机制等;
这两个方向上的优化需要分享芯片上有限的资源;强化一个方向的性能/增加某个方向的资源分配往往就意味着需要牺牲另一个方向的性能。
多核CPU、GPU、FPGA是常见的并行计算架构,它们的资源分配倾向示意图见图。

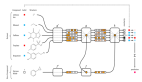
GPU将主要资源分配给了图形常用计算单元,如浮点数的乘法和加法,而采用了最简单的片上网络拓扑:树状NoC网络,在基本计算单元之间传递数据,见图;
这种片上网络的优缺点分别是:
- 优点1:消耗的资源最小;
- 缺点1:通过读写片上存储的方式传递数据,速度较慢;
- 缺点2:树根结点容易因通讯堵塞成为瓶颈,如图中红线和蓝线分别表示A计算节点向B,C向D传递数据,两个传递过程在根节点和二级共享节点交汇,当片上数据传递频繁时,树状拓扑NoC极易发生堵塞问题。

GPU之所以采用树状拓扑结构,概因其“主业”-图形计算仅有少量情形需要在计算节点之间做复杂数据通信,因此采用树状拓扑以外的方案是纯粹的浪费。但树状拓扑结构限制了相当多类别的大规模并行计算任务在GPU上发挥,换句话说,下列这些并行计算任务并不是GPU扩展的强项:
- 带有较多分支判断类的并行计算任务,典型任务如人机交互、电脑和环境交互中的逻辑判断计算等;
- 并行计算中带有较多串行成分,以及反馈算法的并行计算任务,典型例子如控制系统计算任务;
- 带有网状结构数据流的并行计算。典型案例为FFT(傅里叶分析)计算任务,CUDA中的FFT优化后可以提供相对CPU约10倍的提速,但当FFT长度超过某个门限后GPU的提升性能就发生下滑(资料来源:NV官网)。DSP芯片往往针对FFT的算法特性提供定制优化,没有GPU存在的问题,因此手机SoC中往往由DSP而不是GPU处理FFT这种网状大规模并行计算。